Fragment AI
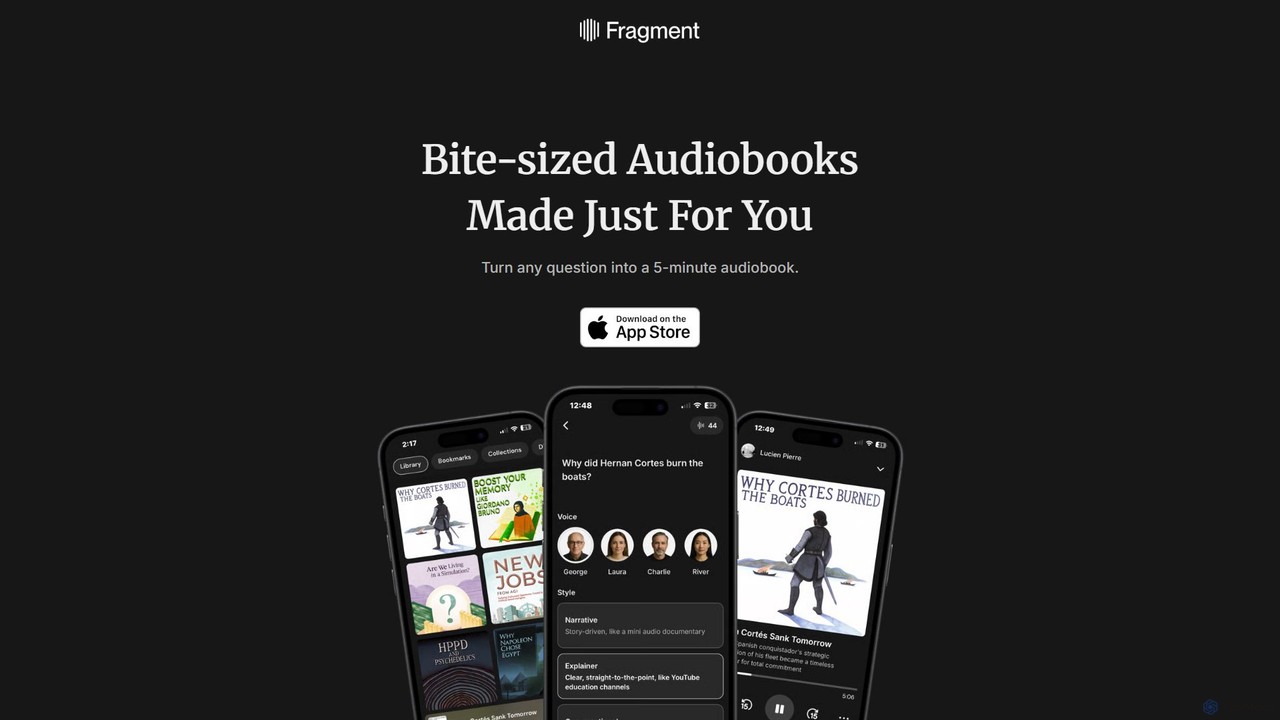
Fragment AIは、あなたの好奇心をパーソナライズされた5分間のオーディオブックに変えます。科学的な概念から歴史的な出来事まで、どんな質問でもするだけで、AIが簡潔で魅力的な音声要約を生成します。あなたの学習スタイルに合わせて、様々な声や物語のスタイルを選べます。各オーディオブックの核心的なアイデアである「パーティクル」でさらに深く掘り下げ、知識ベースを構築しましょう。あなただけのためのマイクロラーニングです。
Fragment AIは、あなたの好奇心をパーソナライズされた5分間のオーディオブックに変えます。科学的な概念から歴史的な出来事まで、どんな質問でもするだけで、AIが簡潔で魅力的な音声要約を生成します。あなたの学習スタイルに合わせて、様々な声や物語のスタイルを選べます。各オーディオブックの核心的なアイデアである「パーティクル」でさらに深く掘り下げ、知識ベースを構築しましょう。あなただけのためのマイクロラーニングです。
FileSpeech
FileSpeechは、PDF、ウェブサイト、スキャンした文書など様々なファイルを自然な音声に変換する強力なテキスト読み上げiOSアプリです。多言語と多様な音声に対応し、オフラインモードでどこでも聴くことができます。アクセシビリティの向上、生産性の向上、コンテンツ制作の支援に最適です。
FileSpeechは、PDF、ウェブサイト、スキャンした文書など様々なファイルを自然な音声に変換する強力なテキスト読み上げiOSアプリです。多言語と多様な音声に対応し、オフラインモードでどこでも聴くことができます。アクセシビリティの向上、生産性の向上、コンテンツ制作の支援に最適です。
テキスト読み上げについて
テキスト読み上げ(TTS)ツールは、書かれたテキストを自然な音声に変換するAI搭載アプリケーションです。これらのツールは、高度な人工知能、自然言語処理、深層学習モデルを活用し、驚くべき精度と表現力で人間のような音声を合成します。多様なユーザーのアクセシビリティ向上、コンテンツ作成ワークフローの自動化、さまざまなデジタルプラットフォームでの新しいインタラクティブなコミュニケーション形式の実現により、計り知れない価値を提供します。現代のTTSソリューションは、感情のニュアンス、多言語サポート、特定の文脈に合わせて発音を微調整する機能を備えた、高度にカスタマイズ可能な音声を提供します。
主要機能
- 自然な音声生成:リアルなイントネーション、リズム、自然な間合いで高品質な人間のような音声を生成し、魅力的で理解しやすいオーディオを作成します。
- 多言語・アクセント対応:幅広い言語と地域アクセントでの音声生成をサポートし、クリエイターがローカライズされたコンテンツでグローバルな視聴者にリーチできるようにします。
- 音声カスタマイズ:音声パラメータを広範囲に制御でき、ユーザーはピッチ、話速、音量を調整し、コンテンツの雰囲気に合わせてさまざまな音声スタイルや感情的なトーンを選択できます。
- SSML(音声合成マークアップ言語)サポート:テキスト内の発音、強調、間合い、話し方をきめ細かく制御し、複雑なスクリプトを正確に配信することを保証します。
- オーディオエクスポートオプション:MP3、WAV、OGGなどの一般的なオーディオ形式での合成音声のエクスポートを可能にし、さまざまなメディアプラットフォームでの互換性と多用途な使用を保証します。
適用シーン
テキスト読み上げツールは、効率的なオーディオソリューションを求めるコンテンツクリエイター、教育者、企業に広く採用されています。YouTuber、ポッドキャスター、オーディオブックプロデューサーを含むコンテンツクリエイターは、TTSを利用して動画、ポッドキャスト、オーディオブック全体のプロフェッショナルなナレーションを生成し、従来の録音と比較して時間とリソースを大幅に節約しています。eラーニングプラットフォームや出版社は、膨大なコース教材、記事、文書をオーディオ形式に変換し、視覚障害のある学習者、読書障害のある学習者、または移動中に聴覚学習を好む個人にとって教育をよりアクセスしやすくしています。さらに、企業はTTSを顧客サービスシステムに統合し、自動音声プロンプト、インタラクティブ音声応答(IVR)メニュー、会話型AIに活用することで、ユーザーエクスペリエンスを向上させ、サポート業務を効率化しています。
選択のポイント
テキスト読み上げツールを選択する際は、聴衆にとって快適で信頼できるリスニング体験を保証するために、音声の品質と自然さを優先してください。ターゲットとするすべての人口統計と地域差をサポートしているかを確認するために、その言語とアクセントのカバー範囲を評価してください。表現豊かで文脈に合った出力には不可欠な、ピッチ、話速、感情の範囲、発音の微調整能力など、提供される音声カスタマイズのレベルを考慮してください。APIを介して既存のアプリケーション、コンテンツ管理システム、または開発ワークフローとTTSサービスを接続する必要がある場合は、統合機能を評価してください。最後に、文字数、使用時間、またはサブスクリプションティアに基づいて異なることが多い価格モデルを慎重に比較し、予算と使用量に合った費用対効果の高いソリューションを見つけてください。
テキスト読み上げ利用シーン
動画コンテンツのナレーションを生成
動画クリエイターやマーケターは、テキスト読み上げツールを使用して、YouTube動画、解説アニメーション、プロモーションクリップのプロフェッショナルなナレーションを迅速に作成できます。スクリプトを入力するだけで、さまざまな声や言語で一貫した高品質のオーディオを生成でき、録音スタジオや声優の必要がなくなり、多様なコンテンツの制作期間を大幅に短縮できます。
eラーニング教材をオーディオに変換
教育機関やオンラインコース提供者は、TTSを活用して教科書、講義ノート、記事をアクセスしやすいオーディオ形式に変換します。これにより、視覚障害のある学生、読書障害のある学生、または移動中に学習することを好む学生に利益をもたらします。包括性を高め、柔軟な学習オプションを提供し、学習者が自分のペースで聴覚的にコンテンツを消費できるようにします。
顧客サービスIVRシステムを自動化
企業はテキスト読み上げ技術を展開して、インタラクティブ音声応答(IVR)システム用の動的で自然な音声プロンプトを作成できます。すべてのメッセージを事前に録音する代わりに、TTSはリアルタイムでの応答生成を可能にし、IVRメニューをより柔軟で更新しやすくします。これにより、明確で一貫性のある最新の情報を提供することで顧客体験が向上します。
オーディオブックやポッドキャストを効率的に制作
作家や独立系出版社は、TTSツールを利用して書かれた原稿を長編オーディオブックやポッドキャストのエピソードに変換できます。これにより、声優を雇ったり録音機材をレンタルしたりするよりも費用対効果が高く、時間も節約できます。カスタマイズ可能な声と感情的なトーンで、クリエイターはより幅広い聴衆に届く魅力的なオーディオコンテンツを制作できます。
アクセシブルなウェブサイトコンテンツを作成
ウェブサイトの所有者やコンテンツ管理者は、TTS機能を統合して、ウェブページ、ブログ投稿、記事のオーディオ版を提供できます。これにより、読書困難なユーザー、視覚障害のあるユーザー、またはマルチタスク中に聞くことを好むユーザーにとって、ウェブサイトのアクセシビリティが大幅に向上します。複数の消費オプションを提供することで、視聴者のリーチを広げ、ユーザーエンゲージメントを高めます。
インタラクティブな語学学習アプリを開発
語学学習プラットフォームやアプリ開発者は、テキスト読み上げを利用して正確な発音モデルとインタラクティブなリスニング演習を提供します。学習者は自然なAI音声で話される単語やフレーズを聞くことができ、新しい言語での発音、リスニング理解、全体的な流暢さを向上させるのに役立ちます。これにより、ダイナミックでパーソナライズされた学習体験が生まれます。