
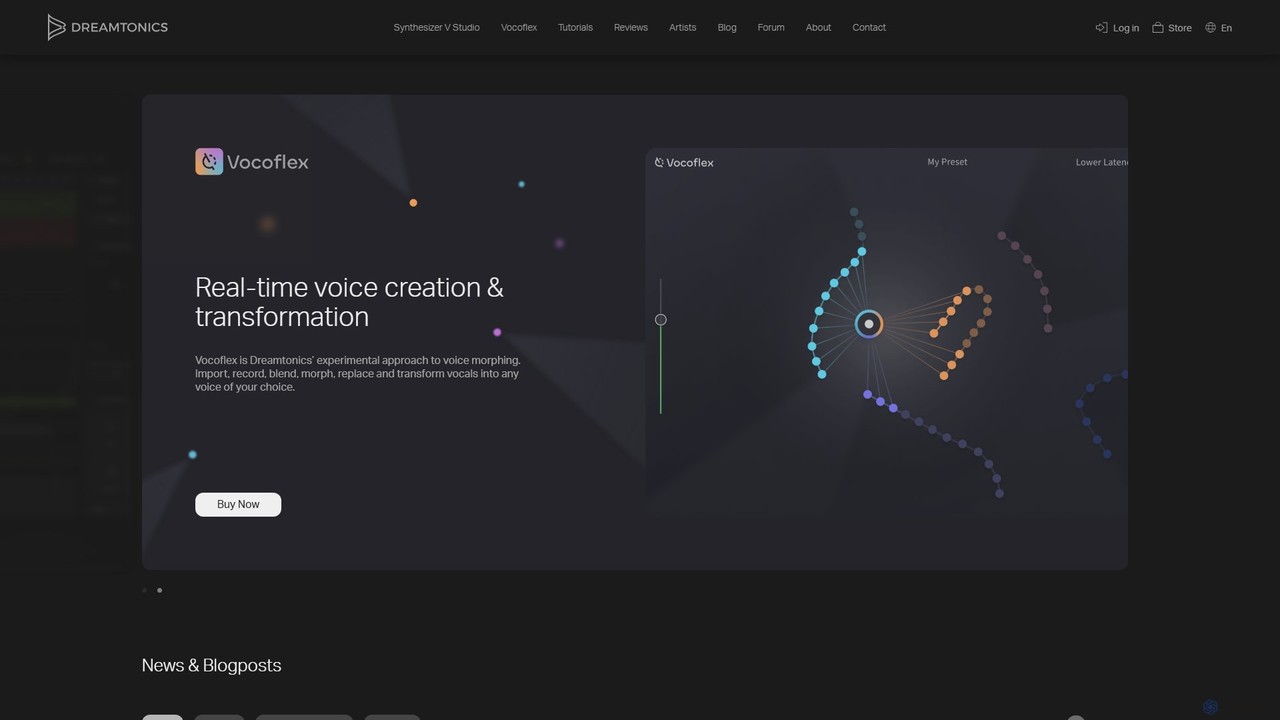
Dreamtonics
Dreamtonicsは、テキストとメロディーから超リアルな歌声を作成するSynthesizer V Studioや、リアルタイムのボイスモーフィングを実現するVocoflexなど、先進的なAIボーカル制作ツールを提供しています。これらのツールは音楽プロデューサー、作曲家、アーティスト向けに設計されており、合成ボーカル制作において比類のないコントロールとリアリズムを実現します。
Dreamtonicsは、テキストとメロディーから超リアルな歌声を作成するSynthesizer V Studioや、リアルタイムのボイスモーフィングを実現するVocoflexなど、先進的なAIボーカル制作ツールを提供しています。これらのツールは音楽プロデューサー、作曲家、アーティスト向けに設計されており、合成ボーカル制作において比類のないコントロールとリアリズムを実現します。
音声合成について
音声合成ツールは、書かれたテキストを人間のような聞き取り可能な音声に変換するAI搭載ソフトウェアの一種です。これらのツールは、テキストを分析し、自然なイントネーション、ペース、感情を持つリアルな音声を生成するために、テキスト読み上げ(TTS)エンジンとして知られる高度なディープラーニングモデルを利用します。その主な価値は、マイク、声優、スタジオを必要とせずに、高品質のナレーションやオーディオコンテンツを効率的に作成できる点にあります。この技術により、ビデオのナレーションからアクセシビリティ機能まで、スケーラブルな音声制作が可能になります。
主な機能
- テキスト読み上げ(TTS)変換:テキスト入力をMP3やWAVなどの形式の音声ファイルに変換する基本的な機能。
- 音声クローニング:短い音声サンプルから特定の声のデジタルレプリカを作成し、一貫性のあるパーソナライズされたナレーションを可能にする機能。
- 多言語・アクセント対応:グローバルなコンテンツ制作のために、多数の言語と地域のアクセントで構築済みの音声ライブラリを提供。
- プロソディと感情の制御:ピッチ、速度、音量、感情的なトーン(例:喜び、悲しみ、興奮)などの音声特性を細かく制御。
- SSMLサポート:音声合成マークアップ言語(SSML)を利用して高度なカスタマイズを行い、開発者が発音、間、強調を正確に制御できるようにする。
利用シーン
音声合成ツールは、YouTubeビデオのナレーション、ポッドキャスト、オーディオブックの制作にコンテンツ制作者によって広く採用されています。ビジネスでは、eラーニングモジュール、企業研修ビデオ、マーケティング資料のプロフェッショナルなナレーションを作成するために使用されます。開発者はまた、APIを介してこれらのツールを統合し、自動音声応答(IVR)システム、アプリ内アシスタント、視覚障害者向けのスクリーンリーダーなどのアクセシビリティ機能を強化します。
選び方のポイント
音声合成ツールを選ぶ際は、まず音声の品質とリアリズムを評価します。サンプルを聞いて基準を満たしているか確認してください。次に、感情の制御や音声クローニング機能を含むカスタマイズオプションの範囲を検討します。ターゲットオーディエンスをカバーしているか、利用可能な言語とアクセントのライブラリを評価します。最後に、技術的なニーズと予算に合ったソリューションを見つけるために、統合機能(APIアクセス)と価格モデル(文字ごと、サブスクリプションなど)を検討します。
音声合成利用シーン
ビデオコンテンツのナレーション作成
YouTuberやマーケティングチームなどのコンテンツ制作者は、ビデオにクリアで一貫性のあるナレーションを付けるために音声合成を頻繁に利用します。録音機材や声優に時間とお金を費やす代わりに、スクリプトをツールに入力または貼り付けるだけです。その後、適切な声を選択し、ビデオの雰囲気に合わせてペースやトーンを調整し、数分で高品質の音声ファイルを生成できます。このプロセスにより、制作ワークフローが大幅に高速化され、編集も容易になります。スクリプトが変更された場合でも、再録音セッションなしで即座に音声を再生成できます。
対話型音声応答(IVR)システムの開発
企業や開発者は、音声合成APIを使用して、より自然で魅力的な顧客サポート用のIVRシステムを構築します。ロボットのような事前に録音されたプロンプトを使用する代わりに、リアルタイムで動的で人間らしい応答を生成できます。たとえば、システムは発信者の名前を呼んだり、特定の口座情報を心地よくクリアな声で読み上げたりすることができます。これにより、対話がよりパーソナルでイライラの少ないものになり、顧客体験が向上します。また、すべての音声プロンプトを手動で再録音することなく、コールフローやスクリプトを簡単に更新できます。
オーディオブックとeラーニングコンテンツの制作
インストラクショナルデザイナーや個人作家は、音声合成を活用して、書かれた資料を魅力的なオーディオ形式に変換します。作家は、プロのナレーターを雇う高額な費用をかけずに、自分の電子書籍をオーディオブックにすることができます。同様に、企業の研修担当者は、従業員向けのナレーション付きeラーニングモジュールを作成できます。音声クローニング機能を使えば、自分の声のデジタル版を使用して個人的なタッチを加えることさえ可能です。これにより、コンテンツがよりアクセスしやすくなり、人々は通勤中や運動中に聞きながら学習することができます。
アクセシビリティ機能の作成
ウェブ開発者やソフトウェアエンジニアは、視覚障害や読書障害を持つユーザーがデジタル製品をより利用しやすくするために音声合成を使用します。TTSエンジンを統合することで、ウェブサイトやアプリケーションは画面上のテキストを音声に変換する「読み上げ」機能を提供できます。これにより、ユーザーは記事、通知、インターフェースの指示を音声で聞くことができます。ここでは高品質な合成音声が非常に重要です。自然な響きの声は、聞くことによる疲労を軽減し、ユーザーにとってより快適で効果的な体験をもたらします。
音声ユーザーインターフェース(VUI)のプロトタイピング
スマートアシスタントや車載システムなどの音声起動アプリケーションを作成するデザイナーや開発者は、迅速なプロトタイピングのために音声合成を使用します。考えられるすべての対話に対してプレースホルダーの音声を録音する代わりに、TTSツールを使用してその場で応答を生成できます。これにより、会話フロー、ユーザーコマンド、システムフィードバックを迅速にテストできます。最終的な音声制作に着手する前に、さまざまな声、トーン、言葉遣いを試して最も効果的なユーザーエクスペリエンスを見つけ出すことができ、設計段階で大幅な時間とリソースを節約できます。
ゲーム内キャラクターの動的な対話生成
ゲーム開発者は、ノンプレイヤーキャラクター(NPC)の対話を作成するために、音声合成をますます利用しています。これは、ロールプレイングゲーム(RPG)のような膨大な量のテキストを持つゲームで特に役立ちます。声優ですべてのセリフを録音するのは法外に高価になるためです。TTSを使えば、開発者はすべてのNPCに声を与えることができ、ゲームの世界をより生き生きと没入感のあるものに感じさせることができます。高度なツールでは、ゲーム内のイベントに基づいて特定の感情的なトーンで対話を生成することさえ可能で、プレイヤーにとってよりダイナミックで応答性の高い体験を生み出します。