ezML
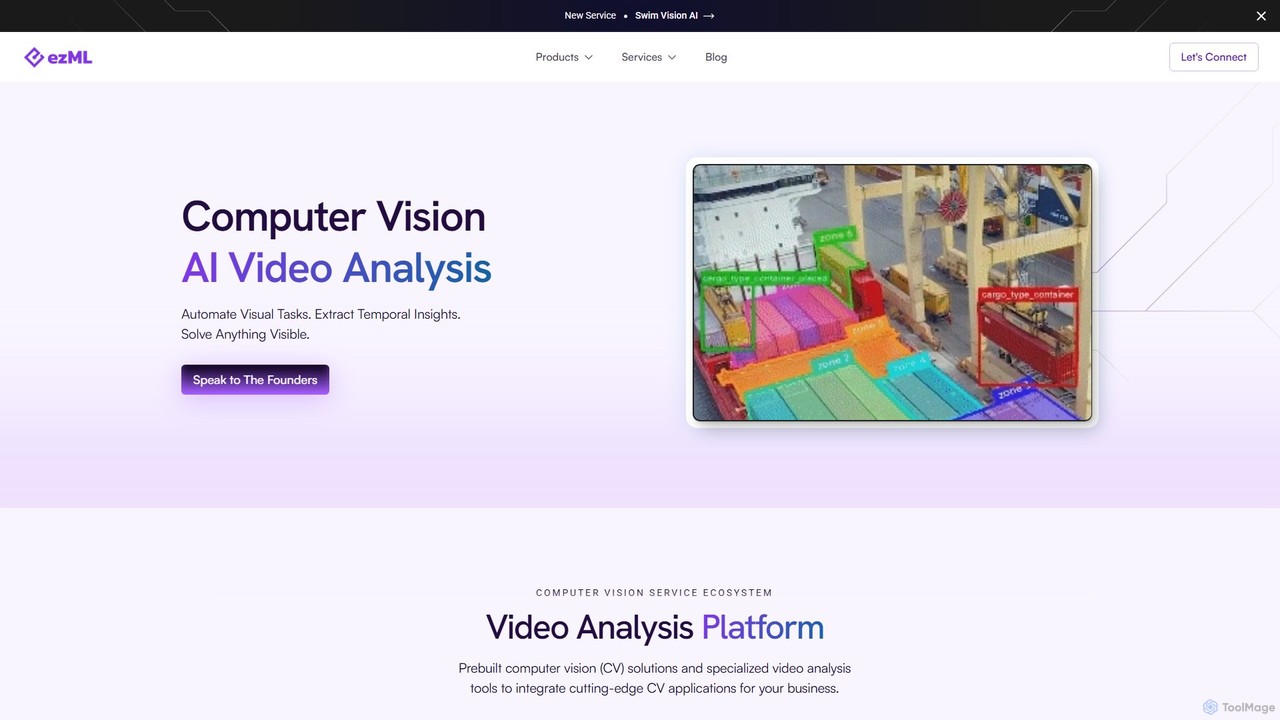
ezMLは、高度なビデオ分析を専門とするエンタープライズ向けのコンピュータビジョン・プラットフォームです。事前構築済みモデル、マルチモーダル検索、合成データ生成、カスタムCVソリューションなどのツール群を提供します。Swim Vision AIのようなスポーツ分析に重点を置き、企業が視覚タスクを自動化し、ビデオデータから深い洞察を抽出し、高性能でスケーラブルなCVアプリケーションを導入するのを支援します。
ezMLは、高度なビデオ分析を専門とするエンタープライズ向けのコンピュータビジョン・プラットフォームです。事前構築済みモデル、マルチモーダル検索、合成データ生成、カスタムCVソリューションなどのツール群を提供します。Swim Vision AIのようなスポーツ分析に重点を置き、企業が視覚タスクを自動化し、ビデオデータから深い洞察を抽出し、高性能でスケーラブルなCVアプリケーションを導入するのを支援します。
データ生成について
データ生成ツールは、新しい合成データセットを作成するAIを活用したソリューションです。これらのツールは、敵対的生成ネットワーク(GANs)や変分オートエンコーダ(VAEs)などの高度なアルゴリズムを活用し、実世界のデータの統計的特性やパターンを模倣した新しいデータを生成します。データ不足への対処、プライバシーの強化、機械学習モデルのトレーニングとテストのための多様で偏りのないデータセットの生成に不可欠です。複雑なデータ分布をシミュレートすることで、機密性の高いまたは限られた実データにのみ依存することなく、堅牢な開発を可能にします。
コア機能
- 合成データ作成: 画像、テキスト、表形式データなど、さまざまなモダリティにわたる現実的で統計的に類似したデータポイントを生成します。
- プライバシー保護: 分析的有用性を維持しつつ、機密情報を匿名化または保護するデータを作成します。
- データ拡張: 既存のデータセットを多様なバリエーションで拡張し、モデルの堅牢性と汎化能力を向上させます。
- バイアス軽減: 実世界のデータに存在する固有のバイアスを軽減するために、バランスの取れたデータセットを生成し、より公平なAIモデルを構築します。
- カスタマイズ可能なパラメータ: データの特性、量、分布、および特定の生成シナリオを指定するための制御機能を提供します。
適用シナリオ
データ生成ツールは、機械学習エンジニア、データサイエンティスト、ソフトウェアテスターに広く採用されています。データが不足しているドメインで堅牢なAIモデルをトレーニングしたり、プライバシーを侵害することなくアプリケーション用の現実的なテストデータを作成したり、医療や金融などの規制業界でコンプライアンスに準拠した匿名データセットを生成したりするのに不可欠です。
選択のポイント
データ生成ツールを選択する際は、必要なデータタイプと忠実度を考慮し、ユースケースに十分な現実性のあるデータを生成できることを確認してください。機密情報に対するプライバシーおよびセキュリティ機能を評価し、大量のデータを効率的に生成するためのスケーラビリティとパフォーマンスを検討します。最後に、データの特性や特定のシナリオを制御するためのカスタマイズオプションを確認してください。
データ生成利用シーン
AIモデルトレーニング用の合成画像データを生成
機械学習エンジニアは、コンピュータビジョンモデルをトレーニングするために大量の多様な画像データを必要としますが、実データの収集はコストがかかり、プライバシーの制限を受けることがよくあります。データ生成ツールは、少量の実画像または特定の記述に基づいて、背景、照明、ポーズ、特徴が異なる数百万枚の合成画像を自動的に作成できます。これにより、データ不足が解消されるだけでなく、多様性を導入することで実世界アプリケーションにおけるモデルの汎化能力と堅牢性が向上し、モデル開発サイクルが大幅に加速されます。
プライバシー規制に準拠した顧客取引テストデータを作成
金融機関は、新製品の開発やシステムのテストを行う際に、機能および性能検証のために大量の顧客取引データを必要とします。しかし、実際の顧客データを使用すると、厳格なプライバシーコンプライアンスのリスクが生じます。データ生成ツールは、既存の取引データの統計パターンに基づいて、同じ構造と特性を持つ完全に匿名化された合成取引データを生成できます。これにより、開発チームは安全でコンプライアンスに準拠した環境で包括的なテストを実施でき、データ漏洩のリスクを回避しつつテストの有効性を確保できます。
ソフトウェアテスト用のユーザー行動データを自動生成
ソフトウェアテスターは、ユーザーインターフェース(UI)およびユーザーエクスペリエンス(UX)テストのために、アプリケーション内でのさまざまなユーザーインタラクション行動をシミュレートする必要があります。これらの複雑な行動パスを手動で作成することは時間がかかり、すべてのエッジケースをカバーできないことがよくあります。データ生成ツールは、事前設定されたユーザー行動パターンまたは履歴ログに基づいて、クリック、入力、ナビゲーションなどの一連のユーザーアクションをシミュレートする合成データを自動的に生成できます。これにより、テストカバレッジと効率が大幅に向上し、潜在的なバグやパフォーマンスのボトルネックを発見するのに役立ちます。
リソースの少ないテキストデータセットを拡張してNLPモデルの性能を向上
自然言語処理(NLP)モデルは、リソースの少ない言語や特定のドメイン(例:法律、医療)においてデータ量不足に直面することが多く、モデルの性能低下につながります。コンテンツ作成者やAI研究者は、データ生成ツールを活用して、少量のシードテキストと言語ルールに基づいて、文法的に正しく意味的に一貫性のある大量の合成テキストデータを生成できます。このデータは、NLPモデルの事前学習やファインチューニングに使用でき、データ不足を効果的に緩和し、リソースの少ない言語環境における翻訳、感情分析、Q&Aシステムなどのタスクの精度を大幅に向上させます。
自動運転システム向けに多様なセンサーシミュレーションデータを生成
自動運転車の開発には、知覚および意思決定モデルをトレーニングするために、膨大な量のセンサーデータ(レーダー、ライダー、カメラなど)が必要です。実世界のデータ収集は非常にコストがかかり、すべての極端なシナリオやまれなシナリオをカバーすることは困難です。データ生成ツールは、複雑な交通環境、気象条件、障害物をシミュレートし、現実的な合成センサーデータを生成できます。これにより、エンジニアは仮想環境で自動運転アルゴリズムを安全かつ効率的にテストおよび検証でき、技術の反復を加速し、安全性を向上させます。
欠損データを補完またはデータセットのバランスを調整してモデルのバイアスを軽減
多くの実世界のデータセットでは、データ欠損やクラスの不均衡の問題があり、これがAIモデルのバイアスや性能低下につながる可能性があります。データアナリストやデータサイエンティストは、データ生成ツールを使用して、既存のデータ分布パターンに基づいて欠損値をインテリジェントに補完したり、少数クラスの合成データを生成したりできます。より完全でバランスの取れたデータセットを作成することで、これらのツールはモデルトレーニングにおけるバイアスを効果的に軽減し、モデルの公平性と予測精度を向上させます。これは特に医療診断や金融リスク評価などの分野で重要です。