Twillot
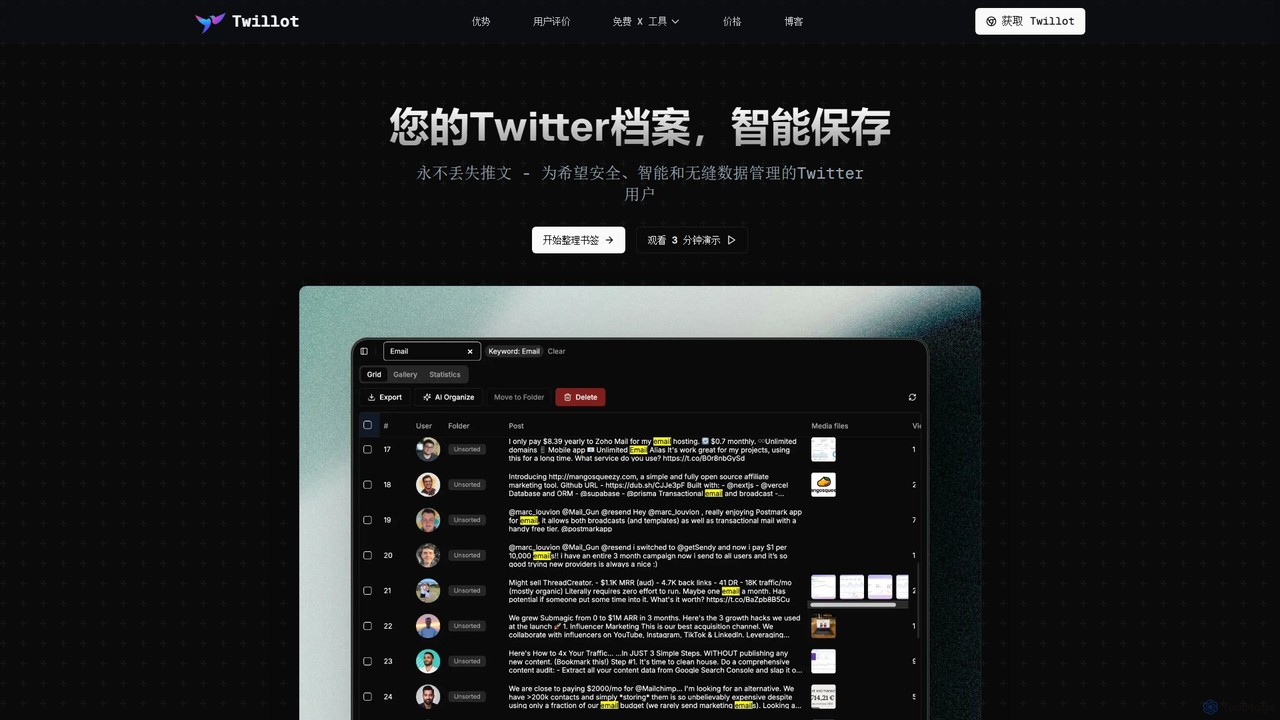
Twillotは、Twitter/X向けのAI搭載ブラウザ拡張機能で、Twitterアーカイブ全体をインテリジェントに保存、管理、検索するために設計されています。ブックマーク、ツイート、いいね、メディアをローカルで整理し、プライバシーを確保し、強力なデータエクスポートおよび分析ツールを提供します。
Twillotは、Twitter/X向けのAI搭載ブラウザ拡張機能で、Twitterアーカイブ全体をインテリジェントに保存、管理、検索するために設計されています。ブックマーク、ツイート、いいね、メディアをローカルで整理し、プライバシーを確保し、強力なデータエクスポートおよび分析ツールを提供します。
アーカイブについて
AIアーカイブツールは、データ管理の専門的なサブカテゴリであり、人工知能を活用してデジタル情報をインテリジェントに保存、管理、および長期的に検索します。これらのツールは、膨大なデータセットの分類、インデックス作成、重複排除、安全なストレージを自動化し、データの整合性と規制要件への準拠を保証します。これらは、履歴記録の保持、法的発見、および将来の分析ニーズに対する効率的なソリューションを提供し、受動的なストレージをアクティブで検索可能な知識ベースに変革します。
主要機能
- 自動分類とインデックス作成: AIアルゴリズムは、コンテンツ、メタデータ、およびコンテキストに基づいてデータを自動的に分類およびタグ付けし、効率的な整理と検索を可能にします。
- インテリジェントな重複排除: さまざまなストレージ場所にある冗長データを識別して排除し、ストレージスペースを最適化し、コストを削減します。
- コンプライアンスとガバナンス: データ保持ポリシーが満たされていることを確認し、法的保持要件をサポートし、規制コンプライアンスのための監査証跡を提供します。
- 高度な検索と取得: 自然言語処理と機械学習を利用して、非構造化データからでもアーカイブされた情報を迅速かつ正確に検索および取得できます。
- データ整合性とセキュリティ: 暗号化、アクセス制御、および整合性チェックを採用し、アーカイブされたデータを破損、不正アクセス、および損失から保護します。
利用シーン
さまざまな分野の組織が、AIアーカイブを利用して大量のデジタル資産を管理し、規制コンプライアンスを確保し、組織の知識を保存しています。これには、訴訟ファイルをアーカイブする法律事務所、患者記録を保持する医療提供者、取引履歴を保存する金融機関などが含まれます。
選択のポイント
AIアーカイブツールを選択する際には、既存システムとの統合機能、将来のデータ増加に対応するスケーラビリティ、特定の業界規制に対するコンプライアンス機能、および検索と取得機能の堅牢性を考慮してください。セキュリティ対策、データ整合性チェック、およびストレージと取得操作の費用対効果を評価します。
アーカイブ利用シーン
法務文書の自動アーカイブ
法律事務所や企業の法務部門は、AIアーカイブツールを使用して、契約書、訴訟ファイル、通信文などの膨大な量の法務文書を自動的に分類、インデックス作成、および保存します。AIは保持ポリシーへの準拠を保証し、高度な検索による迅速な電子開示を促進し、不変の監査証跡を維持することで、手作業と法的リスクを大幅に削減します。
医療患者記録の保持
医療提供者は、AIアーカイブを活用して、HIPAAなどの厳格なプライバシー規制を遵守しながら、電子カルテ(EHR)や医療画像を数十年にわたって安全に保存および管理します。AIは多様なデータタイプの分類を支援し、患者ケア、研究、規制監査のための長期的なアクセス可能性を確保するとともに、機密性の高い患者情報を不正アクセスから保護します。
金融取引履歴の保存
金融機関は、AIアーカイブソリューションを採用して、金融規制(例:SEC、FINRA)への準拠のために数十億の取引記録、通信、および規制報告書を保持します。これらのツールはデータをインテリジェントにインデックス化し、異常を検出し、不変のストレージを提供することで、監査、詐欺調査、および履歴分析のための迅速な検索を可能にし、コンプライアンスリスクを最小限に抑えます。
企業メールと通信のアーカイブ
企業はAIアーカイブを利用して、すべての企業メール、インスタントメッセージ、および共同作業プラットフォームの通信を自動的にキャプチャ、分類、および保存します。これにより、法的発見、内部調査、およびデータ保持ポリシーへの準拠のための包括的な記録保持が保証され、必要に応じて特定の会話や添付ファイルを効率的に検索および取得できます。
研究データと科学記録の保存
研究機関や科学組織は、AIアーカイブを使用して、実験、シミュレーション、研究から生成された大規模なデータセットを管理および保存します。AIは非構造化データの構造化を支援し、長期的なアクセス可能性、研究の再現性、および資金提供機関の要件への準拠を保証し、貴重な科学データを将来の分析と共同作業に利用できるようにします。
メディアアーカイブのデジタル資産管理
メディア企業や放送局は、AIアーカイブを展開して、ビデオ映像、オーディオ録音、画像の膨大なライブラリをインテリジェントに保存、タグ付け、および管理します。AIはメタデータを自動的に抽出し、コンテンツ(例:顔、オブジェクト、話し言葉)を識別し、正確な検索と取得を可能にすることで、生のメディア資産を将来の制作と収益化のための高度に整理されたアクセス可能なアーカイブに変革します。