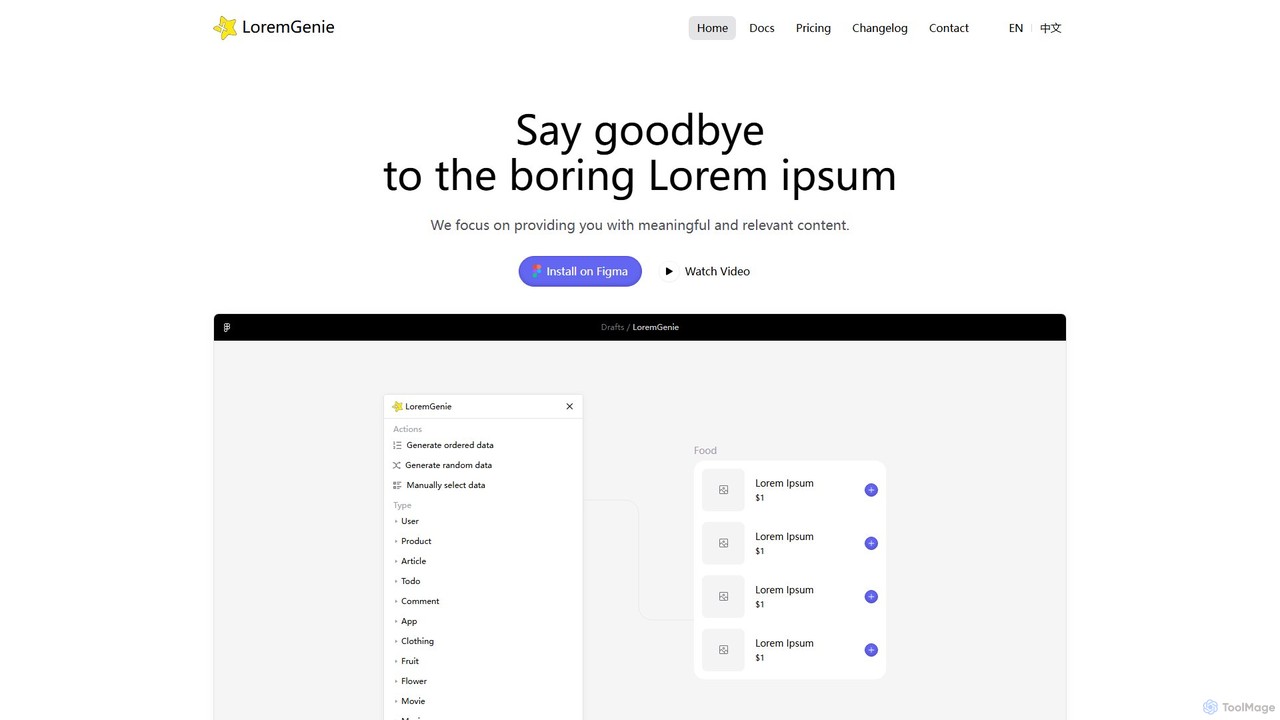
LoremGenie
LoremGenieは、一般的な「Lorem ipsum」を意味のあるリアルなAI生成データに置き換える高度なFigmaプラグインです。ユーザープロフィール、製品、記事など22以上のコンテンツカテゴリを提供し、デザイナーが非常にリアルで文脈に合ったモックアップを作成するのを助け、デザインワークフローを大幅に高速化します。
LoremGenieは、一般的な「Lorem ipsum」を意味のあるリアルなAI生成データに置き換える高度なFigmaプラグインです。ユーザープロフィール、製品、記事など22以上のコンテンツカテゴリを提供し、デザイナーが非常にリアルで文脈に合ったモックアップを作成するのを助け、デザインワークフローを大幅に高速化します。
データ生成について
データ生成ツールは、合成されたリアルで構造化されたデータを作成するために設計されたAI搭載アプリケーションの一種です。これらのツールは、GAN(敵対的生成ネットワーク)のような生成モデルを活用して、実際のデータセットの統計的パターンを学習し、機密情報を公開することなくその特性を模倣した新しいデータを生成します。その主な価値は、堅牢なソフトウェアテスト、プライバシーリスクなしでの機械学習モデルのトレーニング、製品デモンストレーション用の豊富なデータセットの作成を可能にすることにあります。開発者ツール内の重要なコンポーネントとして、オンデマンドで安全かつスケーラブルなデータを提供することにより、開発サイクルを加速させます。
主な機能
- 合成データ作成:現実世界の特性と関係を反映した構造化(表形式、JSON、XML)または非構造化データを生成します。
- プライバシー保護:個人を特定できる情報(PII)を削除または置換しつつ、統計的完全性を保持したデータを作成します。
- カスタマイズ可能なスキーマとルール:ユーザーが特定のデータ構造、制約、ビジネスロジックを定義して、カスタマイズされたデータセットを生成できます。
- スケーラブルなボリューム生成:単体テスト用の数レコードから、大規模なパフォーマンステスト用の数百万レコードまで、あらゆるサイズのデータセットを生成します。
利用シーン
これらのツールは、ソフトウェア開発者、QAエンジニア、データサイエンティストによって広く使用されています。主な用途には、開発およびテストデータベースのデータ投入、実際のデータが不足しているか機密性が高い場合のAI/MLモデルのトレーニング、セールスデモやユーザーオンボーディングチュートリアル用の魅力的でリアルなデータの作成などがあります。
選択のポイント
データ生成ツールを選択する際には、サポートするデータの種類(例:表形式、時系列、テキスト)を考慮してください。生成されたデータのリアリズムと統計的忠実度を評価します。また、ニーズに合わせたスケーラビリティと、CI/CDパイプライン内でデータ作成を自動化するためのAPIアクセスなどの統合機能も評価してください。
データ生成利用シーン
プライバシー準拠のMLモデルのトレーニング
金融機関のデータサイエンティストが、不正検出モデルを構築する必要があります。GDPRのような厳格なプライバシー規制のため、実際の顧客取引データをトレーニングに使用することはできません。データ生成ツールを使用して、匿名化された実データのサンプルを入力します。ツールは統計的分布と相関関係を学習し、大規模で忠実度の高い合成データセットを生成します。これにより、チームは機密性の高い顧客情報を一切公開することなく、堅牢な機械学習モデルをトレーニング、テスト、検証でき、完全なコンプライアンスを確保できます。
負荷テストのためのデータベースへのデータ投入
QAチームが新しいeコマースアプリケーションのローンチを準備しています。50万人のユーザーと200万の商品をパフォーマンスの低下なく処理できることを確認する必要があります。このデータを手動で作成することは不可能です。チームはデータ生成ツールを使用して、ユーザー、商品、注文のスキーマを定義します。単一のコマンドで、ステージングデータベースに数百万のリアルなレコードを投入します。これにより、本番稼働前に包括的な負荷テストを実行し、ボトルネックを特定し、データベースクエリを最適化することができ、コストのかかるダウンタイムを防ぎます。
リアルな製品デモの作成
SaaS企業のセールスエンジニアが、潜在的な企業クライアントに新しい分析ダッシュボードをデモンストレーションする必要があります。空のダッシュボードや、一般的な「テストユーザー」データしかないものを表示しても、印象に残りません。デモの前に、エンジニアはデータ生成ツールを使用して、クライアントの業界に関連する10,000人の架空の従業員、売上高、およびプロジェクトのタイムラインのデータセットを作成します。その結果、データが入力されたダッシュボードは活気に満ちてリアルに見え、クライアントは製品の価値を即座に理解し、自社のデータでどのように機能するかを視覚化できます。
開発のための本番データの匿名化
開発者は、本番データのパターンでのみ発生する複雑なバグをデバッグする必要があります。本番データベースを直接ローカルマシンにコピーすることは、重大なセキュリティリスクであり、データ保護ポリシーに違反します。代わりに、DevOpsチームはデータ生成ツールを使用して本番データベースに接続し、そのスキーマを読み取り、完全に匿名化された新しいデータベースを生成します。この新しいデータベースは、すべてのPII(名前、メールアドレス、住所)をリアルな合成値に置き換え、テーブル間の参照整合性を維持します。これにより、開発者は本番データのように動作するデータをローカルで安全にデバッグできます。
堅牢なテストのためのエッジケースデータの生成
ソフトウェアテスターが新しいユーザー登録フォームを検証しています。その堅牢性を確保するため、実データではまれなエッジケースを含む多種多様な入力でテストする必要があります。データ生成ツールを使用して、特殊文字を含む名前、珍しいが有効な形式のメールアドレス、未来の生年月日、さまざまな国際形式の住所を含むデータセットを作成します。この体系的なアプローチにより、手動テストでは見逃されがちな入力検証やデータ処理ロジックのバグを発見でき、より回復力のあるアプリケーションにつながります。
API開発とテストの加速
バックエンド開発者が、フロントエンドアプリケーションで消費される新しいREST APIを構築しています。フロントエンドチームは作業を開始するためにサンプルデータを必要としていますが、バックエンドはまだ実際のデータベースに接続されていません。バックエンド開発者はデータ生成ツールを使用して、APIの仕様に従ってリアルなJSONデータを提供するモックデータサーバーを迅速に作成します。これにより、フロントエンドチームとバックエンドチームが並行して作業できるようになり、開発サイクルが大幅に短縮されます。また、一貫性のある予測可能なデータセットで自動APIテストを可能にします。