Lumlax
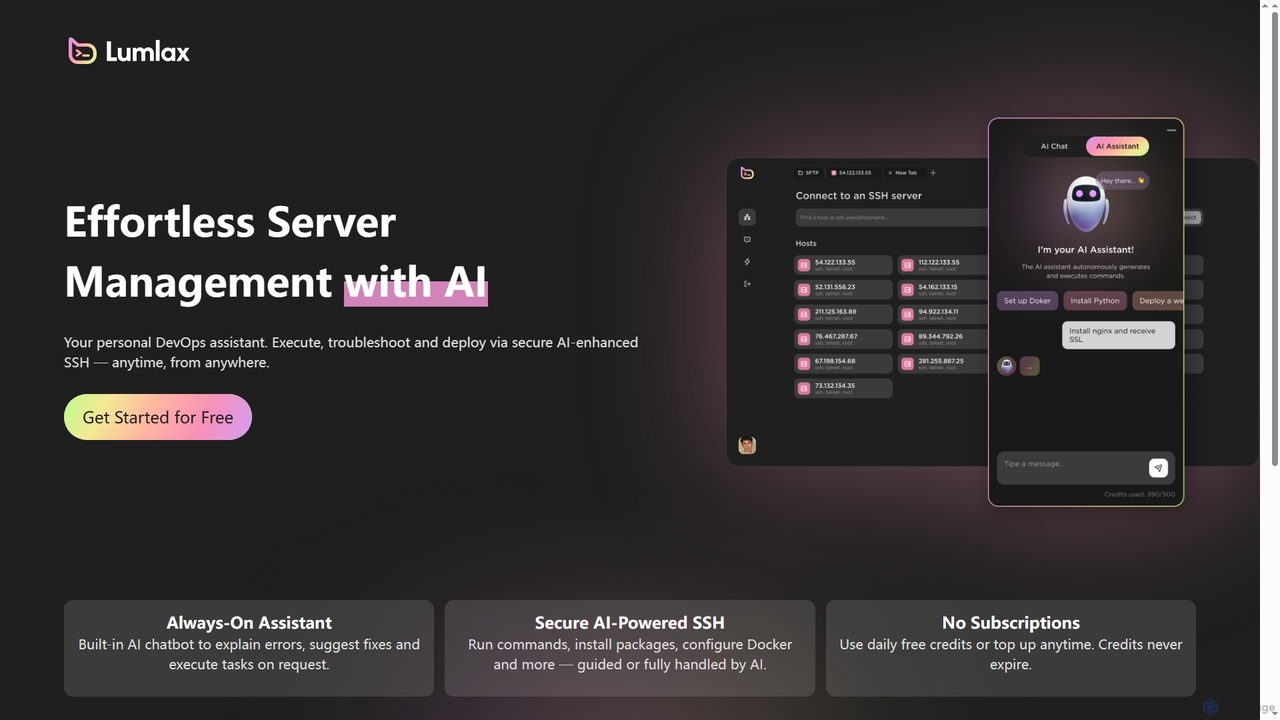
Lumlaxは、AIを活用したSSHアプリケーションで、サーバー管理を簡単にするために設計されています。個人のDevOpsアシスタントとして機能し、開発者がいつでもどこからでも安全にコマンドを実行し、問題をトラブルシューティングし、アプリケーションをデプロイできるようにします。内蔵のAIチャットボットにより、Lumlaxはエラーを説明し、修正案を提案し、タスクを自動化することで、運用を効率化し、生産性を向上させます。
Lumlaxは、AIを活用したSSHアプリケーションで、サーバー管理を簡単にするために設計されています。個人のDevOpsアシスタントとして機能し、開発者がいつでもどこからでも安全にコマンドを実行し、問題をトラブルシューティングし、アプリケーションをデプロイできるようにします。内蔵のAIチャットボットにより、Lumlaxはエラーを説明し、修正案を提案し、タスクを自動化することで、運用を効率化し、生産性を向上させます。
インフラストラクチャについて
AIインフラストラクチャツールは、機械学習モデルの構築、トレーニング、デプロイに必要なコンピューティングリソース、ソフトウェア環境、ワークフローを管理するための専門プラットフォームです。AI向けのIT運用の中心的な要素として、これらのツールはGPUやその他のハードウェアのプロビジョニングとスケーリングを自動化します。データ管理や実験追跡からモデルのサービング、モニタリングまで、MLOpsのライフサイクル全体を効率化します。これにより、チームは開発サイクルを加速し、リソースコストを最適化し、大規模なAIアプリケーションの信頼性の高いパフォーマンスを確保できます。
主な機能
- コンピューティングリソース管理:GPU、CPU、その他のアクセラレータの割り当て、スケジューリング、スケーリングを自動化します。
- モデルのデプロイとサービング:トレーニング済みモデルをスケーラブルで低遅延のAPIエンドポイントとしてデプロイするプロセスを簡素化します。
- MLOpsの自動化:モデルの継続的インテグレーション、デリバリー、トレーニング(CI/CD/CT)のための複雑なワークフローを編成します。
- 実験の追跡と再現性:すべてのトレーニング実行のパラメータ、メトリクス、アーティファクトを記録し、結果の再現性を確保します。
- 環境管理:依存関係を管理し、開発と本番のための一貫したコンテナ化環境を作成します。
利用シーン
これらのツールは、MLOpsエンジニア、データサイエンティスト、AI研究者にとって不可欠です。テクノロジー企業、金融サービス、研究機関で広く使用されており、大規模なモデルトレーニングの管理、アプリケーション向けのリアルタイム推論サービスのデプロイ、企業全体のAI開発のための中央集権型プラットフォームの構築に役立ちます。
選択のポイント
AIインフラストラクチャツールを選択する際は、クラウドプロバイダー(AWS、GCP、Azureなど)やオンプレミスのハードウェアとの互換性を考慮してください。好みの機械学習フレームワークのサポート、将来のワークロードに対応するスケーラビリティ、既存のデータおよびCI/CDパイプラインとの統合能力を評価します。また、データサイエンティストにとっての使いやすさと、DevOpsチームにとっての制御性のバランスも評価してください。
インフラストラクチャ利用シーン
研究チーム向けのGPUクラスタ管理の自動化
大学の研究室では、複数の学生やプロジェクトのために共有GPUクラスタへのオンデマンドアクセスを提供する必要があります。IT管理者はAIインフラストラクチャツールを使用して、リソースのスケジューリングを自動化する中央集権型プラットフォームを構築します。研究者は手動設定なしでトレーニングジョブを投入でき、プラットフォームは利用可能なGPUを自動的に割り当て、ジョブをキューに入れ、需要に応じてリソースをスケーリングします。これにより、リソースの競合が解消され、高価なハードウェアの利用率が最大化されます。
AIスタートアップのためのモデルデプロイの効率化
あるAIスタートアップが新しい推薦エンジンを開発し、それをウェブアプリケーション用の高可用性APIとしてデプロイする必要があります。MLOpsチームはAIインフラストラクチャプラットフォームを使用して、モデルをコンテナにパッケージ化し、単一のコマンドでデプロイします。プラットフォームはトラフィックの急増を管理するための自動スケーリングを処理し、リアルタイムのパフォーマンス監視を提供し、ゼロダウンタイムでのシームレスなモデル更新を可能にし、デプロイ時間を数週間から数時間に短縮します。
大規模モデルトレーニングのためのクラウドコストの最適化
大企業のデータサイエンスチームは、クラウド上で長時間かつ高コストのモデルトレーニングジョブを頻繁に実行します。彼らはスポットインスタンスをサポートするAIインフラストラクチャツールを導入します。このツールは、トレーニング用に安価なスポットインスタンスを自動的にプロビジョニングし、ジョブのチェックポイント設定と再開によって中断を管理し、アイドル時にはクラスタをゼロにスケールダウンします。この戦略により、パフォーマンスを犠牲にすることなく、モデルトレーニングのクラウドコンピューティングコストを最大80%削減できます。
中央集権型エンタープライズMLOpsプラットフォームの確立
ある金融サービス会社が、異なる部門間で機械学習の開発プロセスを標準化したいと考えています。彼らはAIインフラストラクチャプラットフォームを導入し、すべてのデータサイエンスチームのために統一された環境を構築します。このプラットフォームは、実験追跡、モデルのバージョン管理、セキュリティコンプライアンスのための標準化されたツールを提供します。これにより、チームは効果的に協力し、コンポーネントを再利用し、本番環境にデプロイされるすべてのモデルが会社のガバナンスとセキュリティ基準を満たすことを保証できます。
サーバーレス推論によるAI製品開発の加速
モバイルアプリ開発者が、画像認識のような新しいAI搭載機能を追加したいと考えていますが、複雑なサーバーインフラを管理したくありません。彼らはサーバーレスAIインフラストラクチャツールを使用してモデルをデプロイします。トレーニング済みのモデルをアップロードするだけで、プラットフォームがAPIエンドポイントを提供します。プラットフォームは、基盤となるすべてのコンピューティングリソースを自動的に管理し、ゼロから毎秒数千のリクエストを処理できるようにスケーリングします。これにより、開発者はインフラ管理ではなく、アプリケーションロジックに集中できます。
科学計算における再現性の確保
計算生物学のチームが、実験結果の再現が発表に不可欠な複雑なプロジェクトに取り組んでいます。彼らはAIインフラストラクチャツールを使用して、ワークフローのあらゆる側面を追跡します。このツールは、各実験のコードバージョン、データセット、ハイパーパラメータ、およびソフトウェア環境を自動的に記録します。これにより不変の記録が作成され、どのチームメンバーも数か月後に以前の結果を完全に再現できるようになり、科学的な妥当性と共同作業が保証されます。