DreamOmni2
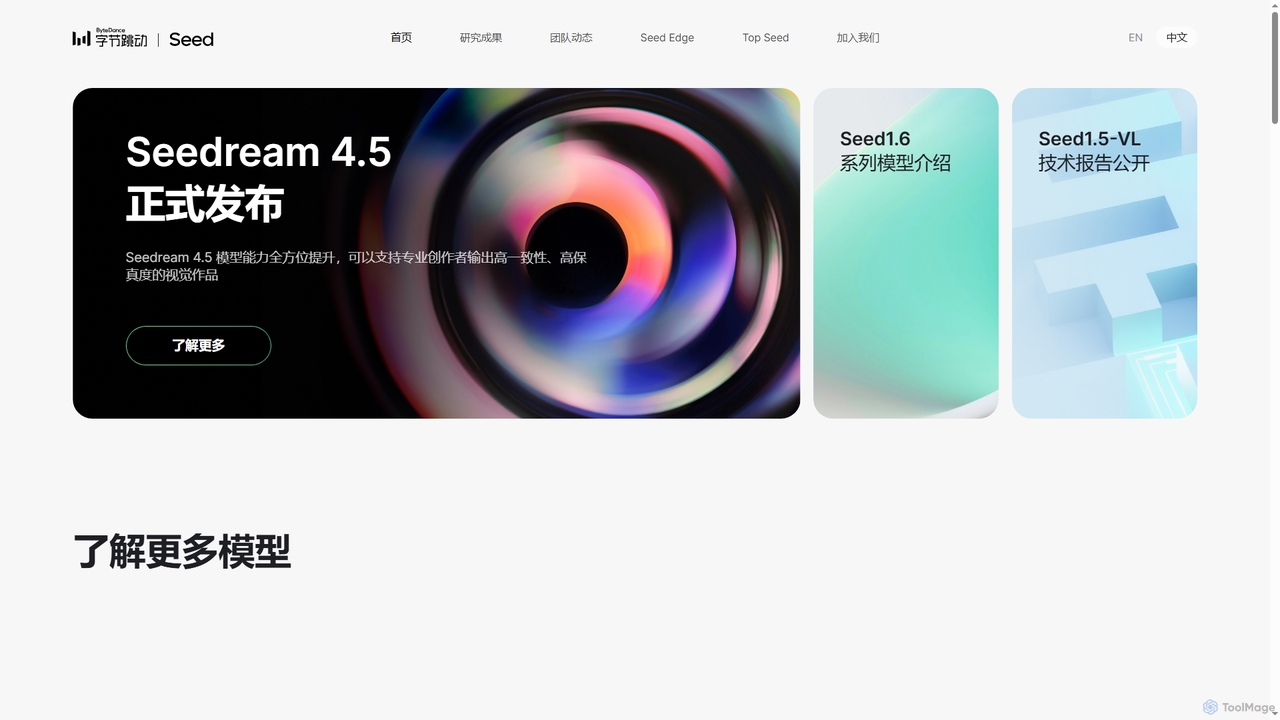
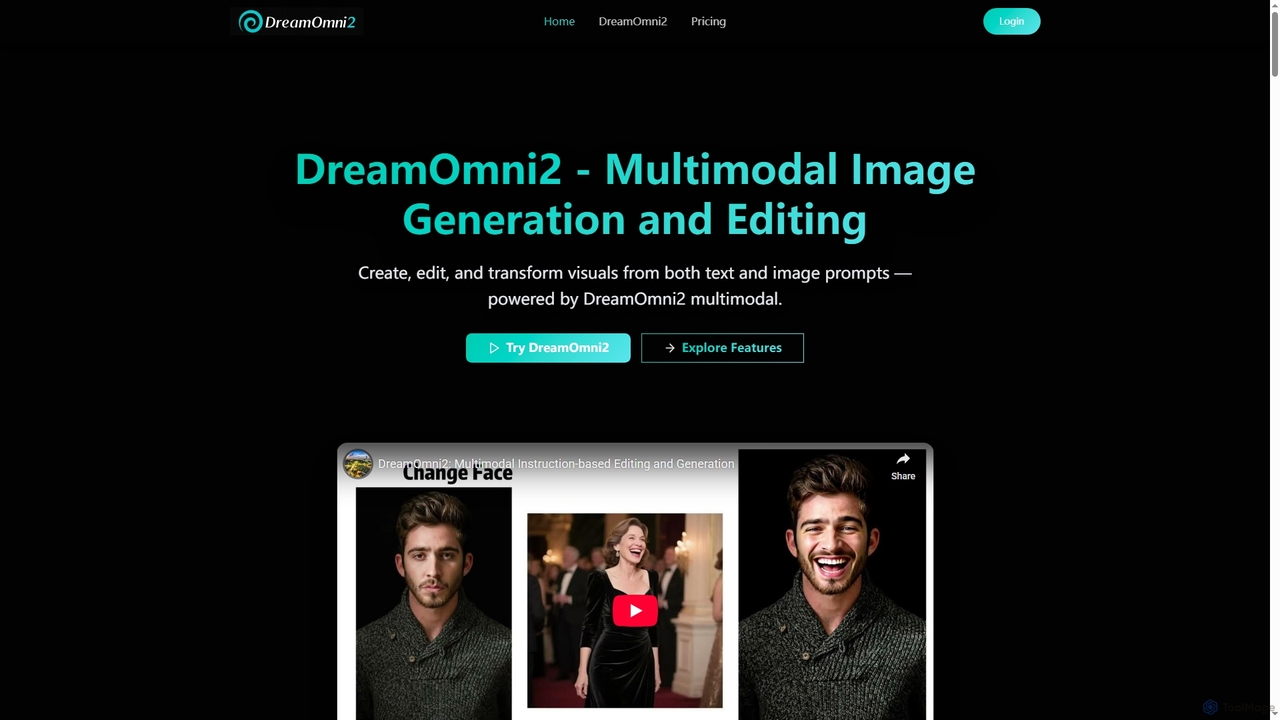
DreamOmni2は、高度な画像生成と編集のためのマルチモーダルAIツールです。テキストと画像の両方のプロンプトを使用してビジュアルを作成・変換でき、デザインから広告まで、多様なアプリケーションで優れた一貫性とクリエイティブな制御を保証します。
DreamOmni2は、高度な画像生成と編集のためのマルチモーダルAIツールです。テキストと画像の両方のプロンプトを使用してビジュアルを作成・変換でき、デザインから広告まで、多様なアプリケーションで優れた一貫性とクリエイティブな制御を保証します。
Primary
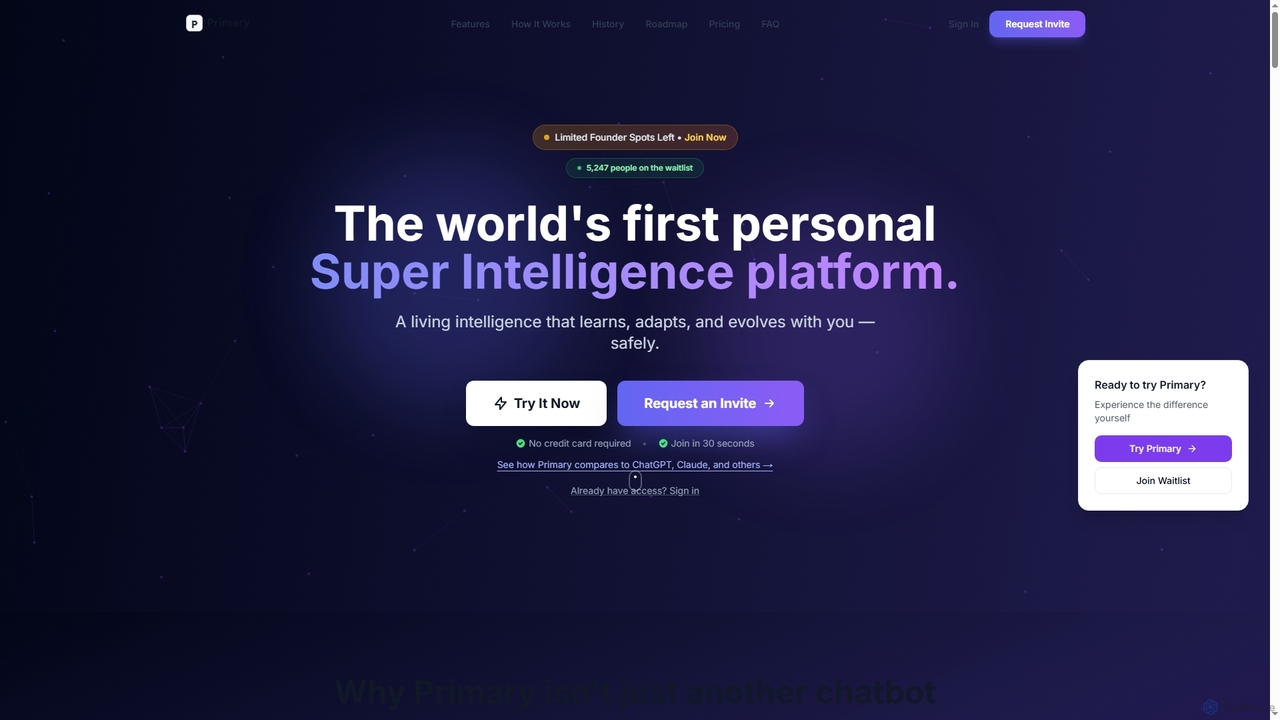
Primaryは、プライバシーを最優先しながら、ユーザーと共に学習し、適応し、進化するように設計された世界初のパーソナルスーパーインテリジェンスプラットフォームです。反復的なタスクを自動化し、複雑なワークフローを管理し、深いパーソナライゼーションを通じてユーザーの時間を週に10時間以上節約する、共生的なAIコンパニオンです。
Primaryは、プライバシーを最優先しながら、ユーザーと共に学習し、適応し、進化するように設計された世界初のパーソナルスーパーインテリジェンスプラットフォームです。反復的なタスクを自動化し、複雑なワークフローを管理し、深いパーソナライゼーションを通じてユーザーの時間を週に10時間以上節約する、共生的なAIコンパニオンです。
マルチモーダルAIについて
マルチモーダルAIとは、テキスト、画像、音声、動画など複数のデータモダリティからの情報を処理、理解、統合できるAI搭載ツールを指します。これらのツールは、ニューラルネットワークやTransformerモデルを含む高度な深層学習技術を活用して、多様な入力の統一された豊かな表現を作成し、複雑な現実世界のシナリオをより包括的かつ微妙に理解することを可能にします。人間の知覚と認知プロセスを模倣することで、マルチモーダルAIは人間とコンピューターのインタラクションを大幅に強化し、より豊かでダイナミックなコンテンツの生成を促進し、クリエイティブ産業から科学研究に至るまで幅広いアプリケーションで、より正確で文脈を意識した洞察を提供します。
主要機能
- クロスモーダル理解:異なるデータタイプ間の関係と意味を解釈し、AIが結合された入力から文脈と意図を推測できるようにします(例:音声の手がかり、視覚的な表情、話し言葉の両方を分析して動画の感情を理解する)。
- 統一表現学習:さまざまなモダリティからの情報がマッピングされる共有埋め込み空間を開発し、AIモデルが結合された、意味的に整合されたデータから推論、比較、学習できるようにします。
- マルチモーダル生成:あるモダリティを別のモダリティに変換したり、複数のモダリティにわたって新しいコンテンツを同時に生成したりすることで、新しいコンテンツを作成します(例:テキスト記述からリアルな動画を生成したり、与えられた画像に合わせて音楽を作曲したりする)。
- 強化されたインタラクション:音声コマンド、ジェスチャー、顔の表情、テキストなどの多様な入力を同時に処理することで、より自然で直感的な人間とAIのコミュニケーションを促進し、より応答性が高くインテリジェントなシステムにつながります。
- 欠損データに対する堅牢性:多くの場合、他のモダリティからの洞察や文脈的な手がかりを活用することで、欠損情報を推測でき、不完全またはノイズの多いデータセットを持つ現実世界のシナリオでのパフォーマンスと信頼性を大幅に向上させます。
適用シナリオ
マルチモーダルAIは、単一モーダルシステムの限界を超え、情報の全体的な理解と統合を必要とする分野でますます重要になっています。コンテンツクリエイターによって、マーケティングビジュアルからインタラクティブな物語まで、多様なメディアアセットを生成するために広く使用されています。医療専門家は、医療画像、電子カルテ、生理学的センサーデータを統合して、より正確な診断と個別化された治療計画のために包括的な患者分析に利用しています。さらに、開発者は、高度なロボット工学や自律走行車など、物理世界とシームレスに相互作用するインテリジェントシステムを構築するためにマルチモーダルAIを採用しています。さまざまな情報源から一貫した洞察を合成するその比類のない能力は、複雑な意思決定、高度な自動化、および多数の産業における革新的なユーザーエクスペリエンスの育成に不可欠な技術となっています。
選択のポイント
マルチモーダルAIツールまたはソリューションを選択する際は、特定の運用ニーズと戦略目標に合致していることを確認するために、いくつかの重要な要素を考慮することが不可欠です。まず、それがサポートする特定のモダリティ(例:テキスト、画像、音声、動画)と、データ環境との関連性を評価します。次に、既存のワークフロー、API、およびプラットフォームとの統合能力を評価し、シームレスな展開とデータフローを確保します。第三に、特にさまざまなデータ条件下での精度、遅延、スケーラビリティなどのパフォーマンス指標を綿密に調査します。第四に、使いやすさ、モデルの微調整のためのカスタマイズオプションの利用可能性、および基盤となるモデルの新しいデータと進化する要件への適応性を考慮します。最後に、価格モデル、必要な計算リソース、ベンダーが提供する技術サポートの品質と応答性を含む総所有コストを考慮に入れます。
マルチモーダルAI利用シーン
顧客サービス向けインテリジェント仮想アシスタント
顧客サービスチームは、テキストチャットだけでなく、音声コマンドも処理し、声のトーンから顧客の感情を分析し、ビデオ通話からの視覚的な手がかりさえも解釈できるマルチモーダルAI搭載の仮想アシスタントを導入できます。これにより、アシスタントは複雑な問い合わせを理解し、より共感的な応答を提供し、問題を適切にエスカレートできるようになり、解決時間の短縮と顧客満足度の向上につながります。
マーケティングキャンペーン向け自動コンテンツ作成
マーケティング担当者は、マルチモーダルAIを活用して、単一の入力から多様なコンテンツアセットを生成できます。たとえば、製品説明を提供することで、AIは魅力的なソーシャルメディアキャプションを同時に作成し、関連する製品画像や短いビデオクリップを生成し、さらにはBGMを作曲することもできます。これにより、コンテンツ制作サイクルが大幅に加速され、プラットフォーム全体でのブランドの一貫性が確保されます。
医療診断と患者モニタリングの強化
医療提供者は、マルチモーダルAIを利用して、医療画像(X線、MRI)、電子カルテ(テキスト)、検査結果、さらにはリアルタイムセンサーデータ(ウェアラブル)など、さまざまな情報源からの患者データを統合できます。AIはこれらのモダリティ全体で微妙なパターンと相関関係を特定し、医師がより正確な疾患診断、個別化された治療計画、および早期介入のための継続的な患者モニタリングを支援します。
スマート監視と異常検出
警備員は、ビデオフィード、音声入力(例:ガラスの割れる音、警報)、さらには環境センサーデータを同時に分析するマルチモーダルAIシステムを導入できます。これにより、視覚的なイベントと異常な音や環境の変化を相互参照することで、公共スペースでの不審な行動や不正アクセスを特定するなど、より正確な異常検出が可能になり、誤報を減らし、応答効率を向上させます。
パーソナライズされた教育コンテンツ配信
教育者やeラーニングプラットフォームは、マルチモーダルAIを使用して、個々の学生のニーズに合わせて学習教材を調整できます。学生のテキスト応答、インタラクティブセッション中の声のトーン、さらにはコンテンツを閲覧中のアイトラッキングデータを分析することで、AIは学習スタイル、理解度、エンゲージメントを特定できます。その後、提示形式(テキスト、音声、動画)と難易度を動的に調整し、真にパーソナライズされた学習体験を作成します。
ロボット工学と自律ナビゲーション
ロボットや自律走行車を開発するエンジニアは、マルチモーダルAIを統合して、環境とのより洗練されたインタラクションを可能にできます。ロボットは、カメラからの視覚データ、LiDARからの深度情報、マイクからの音声キュー、センサーからの触覚フィードバックを組み合わせて、複雑な地形をナビゲートし、物体を識別し、人間のコマンドを理解し、より高い精度と安全性で繊細な操作タスクを実行できます。