Kubiks
Kubiksは、分散トレーシング、ロギング、カスタムダッシュボードを提供するAIパワードのフルスタック可観測性プラットフォームです。問題を自動的に検出し、根本原因を特定し、修正を含むプルリクエストを生成することで、エンジニアリングチームがより迅速にデバッグし、問題をプロアクティブに解決するのを支援します。
Kubiksは、分散トレーシング、ロギング、カスタムダッシュボードを提供するAIパワードのフルスタック可観測性プラットフォームです。問題を自動的に検出し、根本原因を特定し、修正を含むプルリクエストを生成することで、エンジニアリングチームがより迅速にデバッグし、問題をプロアクティブに解決するのを支援します。
サイト信頼性エンジニアリングについて
サイト信頼性エンジニアリング(SRE)は、ソフトウェアエンジニアリングの原則をインフラストラクチャと運用問題に適用し、高い信頼性とスケーラビリティを持つシステムを構築することを目的とした分野です。自動化、データ駆動型の意思決定、サービスレベル目標(SLO)への注力を活用し、重要なサービスの安定性とパフォーマンスを保証します。より広範な「運用」カテゴリの中核をなすSREツールは、チームがシステムの状態を積極的に管理し、インシデントに効率的に対応し、サービスの信頼性を継続的に向上させることを可能にします。
コア機能
- SLO/SLA監視: サービスレベル目標と合意を追跡・報告し、パフォーマンス目標が達成されていることを確認します。
- インシデント管理と自動化: 自動化されたワークフローを通じて、インシデントの検出、アラート、対応、解決プロセスを効率化します。
- エラーバジェット管理: 許容される信頼性のないレベルを定義・追跡し、開発と運用の優先順位を導きます。
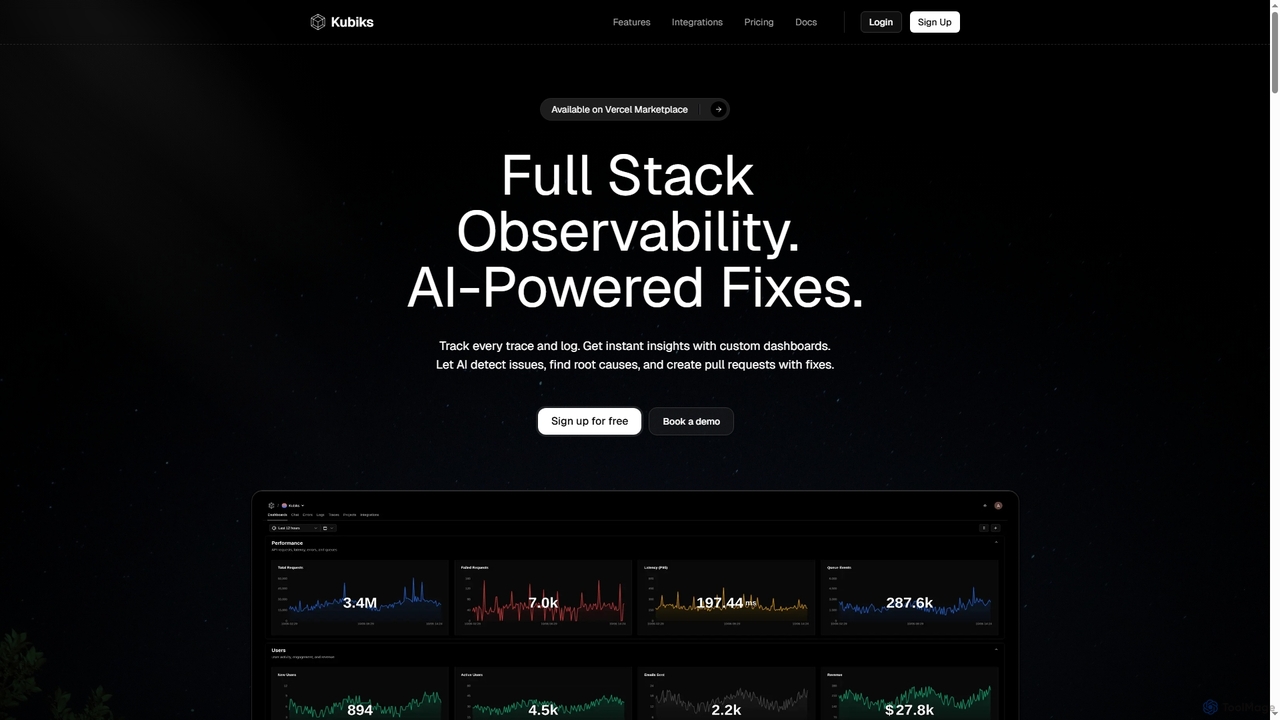
- 可観測性と監視: ログ、メトリクス、トレースを通じてシステム動作に関する包括的な洞察を提供し、問題の事前特定を可能にします。
- キャパシティプランニング: リソースのニーズを予測し、インフラストラクチャを最適化して、予想される負荷に対応し、停止を防ぎます。
適用シナリオ
SREツールは、大規模なEコマースプラットフォーム、SaaSプロバイダー、金融サービスなど、複雑な分散システムを運用する組織にとって不可欠です。SREチーム、DevOpsエンジニア、プラットフォームエンジニアが、高可用性を維持し、マイクロサービスの信頼性を管理し、重要な運用タスクを自動化することで、シームレスなユーザーエクスペリエンスとビジネス継続性を保証します。
選択のポイント
SREツールを選択する際は、堅牢な可観測性機能、既存のCI/CDパイプラインやクラウドプラットフォームとのシームレスな統合、包括的なインシデント管理機能を提供するソリューションを優先してください。ツールのスケーラビリティ、SLOコンプライアンスのためのレポート機能、エラーバジェット追跡をサポートする能力も考慮してください。ユーザーフレンドリーさとコミュニティサポートも、チームの効果的な導入には不可欠です。
サイト信頼性エンジニアリング利用シーン
インシデント対応ワークフローの自動化
オンコールエンジニアやSREチーム向けに、AIを活用したSREツールは分散システム全体での異常や重大なインシデントの検出を自動化します。これにより、アラートのトリガー、診断スクリプトの開始、さらには過去のデータに基づいた修復手順の提案が可能になり、平均復旧時間(MTTR)を大幅に短縮し、重大な停止時のサービス中断を最小限に抑えます。
サービスレベル目標(SLO)の監視と実施
SREチームはこれらのツールを活用して、重要なサービスのサービスレベル目標(SLO)を定義、監視、実施します。ツールは継続的にメトリクス(例:レイテンシ、エラー率、可用性)を収集・分析し、SLOが危険にさらされた際にリアルタイムのダッシュボードとアラートを提供することで、ユーザーに影響が及ぶ前にパフォーマンス低下に proactively 対処することを可能にします。
プロアクティブなキャパシティプランニングとリソース最適化
インフラストラクチャアーキテクトとSREは、SREツールをデータ駆動型のキャパシティプランニングに活用します。過去の使用パターンを分析し、将来の需要を予測することで、これらのツールはリソース割り当てを最適化し、ボトルネックを防ぎ、トラフィックの急増に対応するためにシステムが効率的にスケールできるようにします。これにより、コストのかかる過剰プロビジョニングや、リソース不足によるサービス停止を回避します。
非難のない事後分析の実施
インシデント発生後、SREツールは様々なソースからのログ、メトリクス、トレースを集約することで、包括的な事後分析を促進します。これにより、SREおよび開発チームは根本原因を特定し、寄与要因を理解し、責任を追及することなく学んだ教訓を文書化できます。これは継続的な改善の文化を育み、同様の問題の再発を防ぎます。
エラーバジェットの実装と管理
プロダクトオーナーとSREは、これらのツールを使用してエラーバジェットを実装・管理します。エラーバジェットは、サービスに許容される信頼性のない量を定量化するものです。ツールはエラーバジェットの消費をリアルタイムで追跡し、製品およびエンジニアリングチームに対し、新機能開発よりも信頼性作業を優先すべき時期について明確なシグナルを提供し、イノベーションと安定性のバランスを取ります。
複雑な分散システムにおける可観測性の向上
プラットフォームエンジニアとSREは、これらのツールを展開して、マイクロサービスアーキテクチャとクラウドネイティブアプリケーションに対する深い可観測性を獲得します。数百または数千のサービスにわたるメトリクス、ログ、トレースを相関させることで、ツールはシステムの状態の統一されたビューを提供し、迅速なデバッグ、パフォーマンスチューニング、およびシステム動作の全体的な理解を可能にします。