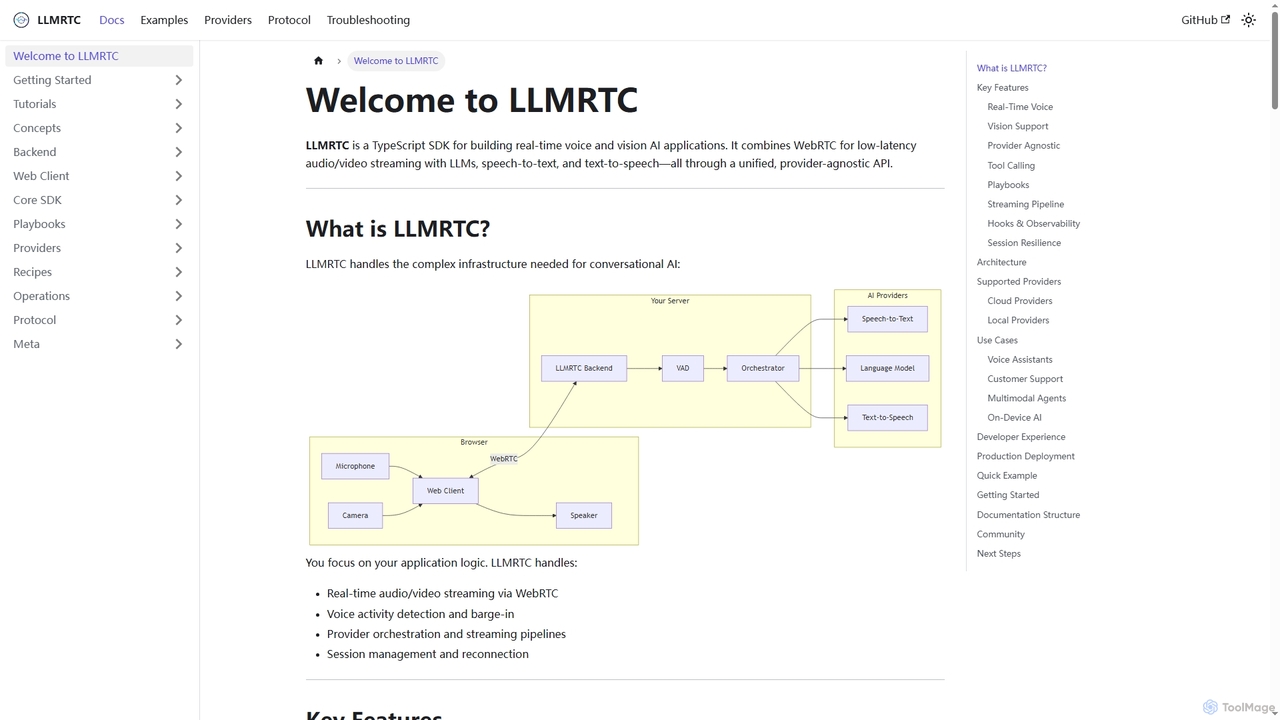
LLMRTC
LLMRTCは、リアルタイムの音声およびビジョンAIアプリケーション構築のためのTypeScript SDKです。WebRTCによる低遅延のオーディオ/ビデオストリーミングと、LLM、音声認識、音声合成技術を、統一されたプロバイダー非依存のAPIを通じてシームレスに統合します。開発者はアプリケーションロジックに集中でき、LLMRTCが複雑な会話型AIインフラストラクチャを処理します。
LLMRTCは、リアルタイムの音声およびビジョンAIアプリケーション構築のためのTypeScript SDKです。WebRTCによる低遅延のオーディオ/ビデオストリーミングと、LLM、音声認識、音声合成技術を、統一されたプロバイダー非依存のAPIを通じてシームレスに統合します。開発者はアプリケーションロジックに集中でき、LLMRTCが複雑な会話型AIインフラストラクチャを処理します。
Noiz
Noizは、テキスト読み上げ、音声クローニング、インスタント動画吹き替えのための高度なAI音声プラットフォームです。リアルな音声を生成し、3〜10秒の音声クリップから任意の声をクローンし、元の声の特徴を保ちながらコンテンツを多言語に翻訳します。コンテンツ制作者、マーケター、開発者に最適です。
Noizは、テキスト読み上げ、音声クローニング、インスタント動画吹き替えのための高度なAI音声プラットフォームです。リアルな音声を生成し、3〜10秒の音声クリップから任意の声をクローンし、元の声の特徴を保ちながらコンテンツを多言語に翻訳します。コンテンツ制作者、マーケター、開発者に最適です。
voiceisolator
オーディオ/ビデオファイルから高品質な音声分離、背景ノイズ除去、ステム分離を行うために設計されたAI搭載オンラインツールです。また、自然な音声のナレーションを作成するための多機能なテキスト読み上げ(TTS)ジェネレーターも備えています。ミュージシャン、コンテンツ制作者、ビデオ編集者に最適です。
オーディオ/ビデオファイルから高品質な音声分離、背景ノイズ除去、ステム分離を行うために設計されたAI搭載オンラインツールです。また、自然な音声のナレーションを作成するための多機能なテキスト読み上げ(TTS)ジェネレーターも備えています。ミュージシャン、コンテンツ制作者、ビデオ編集者に最適です。
CAMB.AI
CAMB.AIは、コンテンツ、エンターテイメント、スポーツ業界向けの先駆的なAIローカライゼーションプラットフォームです。150以上の言語で、感情を保持したリアルタイムの吹き替えと翻訳を提供します。IMAXやMLSなどの主要パートナーから信頼されており、クリエイターが元のトーンと信頼性を維持しながら、コンテンツを世界中で利用できるようにします。
CAMB.AIは、コンテンツ、エンターテイメント、スポーツ業界向けの先駆的なAIローカライゼーションプラットフォームです。150以上の言語で、感情を保持したリアルタイムの吹き替えと翻訳を提供します。IMAXやMLSなどの主要パートナーから信頼されており、クリエイターが元のトーンと信頼性を維持しながら、コンテンツを世界中で利用できるようにします。
Altered
Alteredは、リアルタイムのボイスチェンジとポストプロダクションの音声編集の両方を提供するプロフェッショナルなAI音声技術プラットフォームです。独自のSpeech-To-Speechモーフィング技術により、ユーザーは自分の声を厳選されたポートフォリオの声に変えたり、任何の声をクローンしたり、アクセントを変更したり、声の明瞭度を回復したりすることができます。コンテンツ制作者、ゲーマー、コールセンター、音声の変更や保護を求める個人にサービスを提供します。
Alteredは、リアルタイムのボイスチェンジとポストプロダクションの音声編集の両方を提供するプロフェッショナルなAI音声技術プラットフォームです。独自のSpeech-To-Speechモーフィング技術により、ユーザーは自分の声を厳選されたポートフォリオの声に変えたり、任何の声をクローンしたり、アクセントを変更したり、声の明瞭度を回復したりすることができます。コンテンツ制作者、ゲーマー、コールセンター、音声の変更や保護を求める個人にサービスを提供します。

neoformai
neoformaiは、アフリカの方言に特化した自動音声認識(ASR)やテキスト読み上げ(TTS)などの高度なAIモデルを提供します。これにより、開発者や企業は包括的なアプリケーションを構築し、言語の壁を乗り越え、アフリカ全土の何百万人もの人々にデジタル体験を届けることができます。
neoformaiは、アフリカの方言に特化した自動音声認識(ASR)やテキスト読み上げ(TTS)などの高度なAIモデルを提供します。これにより、開発者や企業は包括的なアプリケーションを構築し、言語の壁を乗り越え、アフリカ全土の何百万人もの人々にデジタル体験を届けることができます。
AudioPod
AudioPodは、クリエイター向けに包括的なツールスイートを提供するプロフェッショナルなAIオーディオスタジオです。高度な音声クローン、多言語の音声から音声への翻訳(AIダビング)、高精度の話者分離、音楽のステム分離、ノイズリダクション、自動文字起こし機能を備えています。ポッドキャスター、コンテンツクリエイター、ミュージシャン、企業のオーディオおよびビデオ制作ワークフローを合理化し、プロ級のオーディオ処理をアクセスしやすく効率的にします。
AudioPodは、クリエイター向けに包括的なツールスイートを提供するプロフェッショナルなAIオーディオスタジオです。高度な音声クローン、多言語の音声から音声への翻訳(AIダビング)、高精度の話者分離、音楽のステム分離、ノイズリダクション、自動文字起こし機能を備えています。ポッドキャスター、コンテンツクリエイター、ミュージシャン、企業のオーディオおよびビデオ制作ワークフローを合理化し、プロ級のオーディオ処理をアクセスしやすく効率的にします。
テキスト読み上げについて
テキスト読み上げ(Text To Speech、TTS)ツールは、書かれたテキストを自然な音声に変換するAIソフトウェアの一種です。深層学習モデルを活用し、人間のような声を合成し、ピッチ、トーン、速度を精密に制御します。デジタルコンテンツのアクセシビリティ向上、記事の音声版作成、ビデオやポッドキャストのナレーション提供に不可欠です。現代のTTS技術は、ロボット的な音声をはるかに超え、リアルな声、多言語対応、感情表現の幅広さを提供します。
主な機能
- 多様な音声と言語:多数の言語やアクセントに対応した、男性、女性、子供の多様な音声ライブラリにアクセスできます。
- 音声のカスタマイズ:話速、ピッチ、音量などの音声パラメータを調整し、自然な話し方のためにポーズを追加できます。
- SSMLサポート:音声合成マークアップ言語(SSML)を利用して、発音、強調、イントネーションを細かく制御します。
- 音声エクスポート形式:生成された音声をMP3やWAVなどの一般的な形式でダウンロードし、様々な用途に利用できます。
- APIアクセス:TTS機能をアプリケーションやウェブサイトに直接統合し、リアルタイムの音声生成を実現します。
適用シーン
これらのツールは、コンテンツ制作者によるビデオのナレーション、作家によるオーディオブックの制作、開発者によるアプリへの音声機能の統合に広く利用されています。また、企業研修のeラーニングモジュールや、カスタマーサービスの動的IVRシステムでも重要な役割を果たします。
選択のポイント
テキスト読み上げツールを選ぶ際は、まず音声の品質とリアルさを評価します。利用可能な言語とアクセントの範囲を考慮してください。SSMLサポートなど、カスタマイズと制御のレベルを評価します。最後に、価格モデルを確認し、自社製品にサービスを統合する必要がある場合はAPIの利用可能性を確認します。
テキスト読み上げ利用シーン
ビデオコンテンツのナレーション作成
コンテンツ制作者やビデオマーケターは、一連の解説ビデオのために、声優を雇う高額な費用をかけずに、一貫性のあるプロフェッショナルなナレーションを必要としています。彼らはスクリプトをテキスト読み上げツールに貼り付け、適切な声と言語を選択し、速度を調整したりポーズを追加したりして話し方を微調整できます。最終的な音声はMP3ファイルとしてエクスポートされ、ビデオ映像と同期されます。このプロセスにより、制作時間と予算が大幅に削減され、コンテンツ作成が迅速化し、スクリプトが変更された際のナレーションの更新も容易になります。
eラーニングおよびトレーニングモジュールの開発
インストラクショナルデザイナーが、グローバルな従業員向けのオンラインコースを作成しています。コンテンツをより魅力的でアクセスしやすくするために、彼らはテキスト読み上げツールを使用して画面上のテキストをナレーションします。APIを使用することで、ナレーションを動的に生成でき、コース教材への更新が即座に音声に反映されるようになります。このアプローチは、さまざまな学習スタイルに対応し、読書が困難な従業員を支援し、異なる声を選択するだけでコースを多言語で簡単に制作できるため、全体的な学習体験が向上します。
オーディオブックとポッドキャストの制作
独立系の作家が、より広い読者層にリーチするために電子書籍をオーディオブックに変換したいと考えていますが、プロの録音スタジオの予算がありません。テキスト読み上げジェネレーターを使用すると、原稿全体をアップロードし、本のトーンに合ったナレーターの声を選択し、各章ごとに高品質の音声ファイルを生成できます。これにより、従来のコストの数分の一でAudibleやSpotifyなどのプラットフォームで公開できます。同様に、ポッドキャスターはTTSを使用して、物語形式の番組で一貫したイントロ、アウトロ、さらには異なるキャラクターの音声セグメントを作成できます。
ウェブサイトと記事のアクセシビリティ向上
デジタル出版社や報道機関は、WCAG基準に準拠し、視覚障害や読書障害のあるユーザーがオンライン記事にアクセスできるようにしたいと考えています。彼らはウェブサイトにテキスト読み上げウィジェットを統合することができます。これにより、訪問者は「聞く」ボタンをクリックするだけで、記事のテキストが即座に高品質の音声に変換されます。これはアクセシビリティとユーザーエクスペリエンスを向上させるだけでなく、通勤中やマルチタスク中に音声でコンテンツを消費したいユーザーにも対応します。これにより、ウェブサイトのリーチが広がり、包括性への取り組みが示されます。
音声ユーザーインターフェース(VUI)のプロトタイピング
UXデザイナーやアプリ開発者が、スマートアシスタントや車載ナビゲーションシステムなどの音声制御アプリケーションを構築しています。プレースホルダーの音声を録音する代わりに、テキスト読み上げツールを使用してプロトタイプの音声応答を迅速に生成します。これにより、現実的なユーザーテスト環境でさまざまなフレーズ、トーン、応答時間をテストできます。テキストを即座に変更して音声を再生成できるため、設計の反復プロセスが迅速かつコスト効率よく行え、より洗練されたユーザーフレンドリーな最終的な音声インターフェースにつながります。
IVRシステムによるカスタマーサービスの自動化
コールセンターのマネージャーは、会社の対話型音声応答(IVR)システムを新しいメニューオプションやプロモーションメッセージで更新する必要があります。小さな変更のたびに声優を雇う代わりに、テキスト読み上げサービスを使用します。彼らは単に「営業時間が変更されました」などの新しいプロンプトを入力し、クリアでプロフェッショナルな音声ファイルを生成します。これにより、会社の電話システムは常に最新の情報を持ち、一貫したブランドの声を維持できると同時に、手動での録音セッションと比較して大幅な時間とリソースを節約できます。