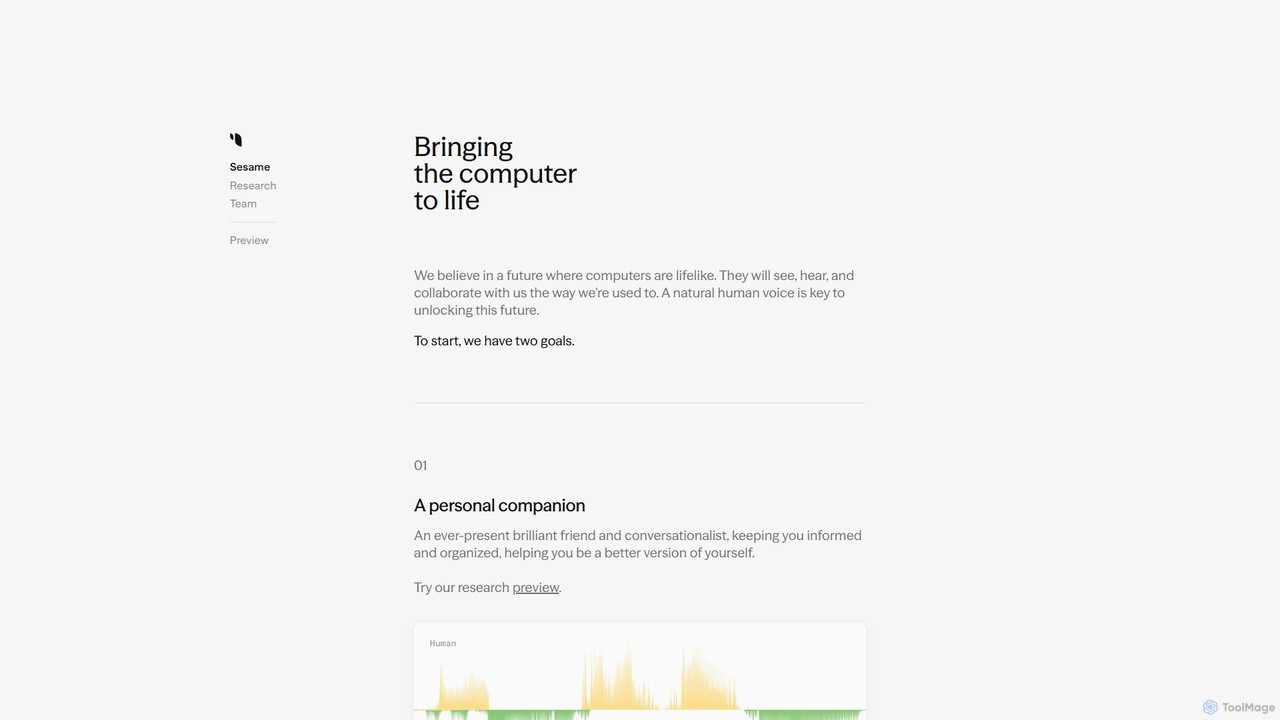
Sesame
Sesameは、自然で感情的に知的な会話を通じて対話するように設計された、生命感あふれるAIパーソナルコンパニオンを開発しています。「声の存在感」に焦点を当てることで、デジタル音声の「不気味の谷」を越えることを目指しています。このプラットフォームは、高度な対話型音声モデル(CSM)と軽量アイウェアのビジョンを組み合わせ、常にそばにいる協力的なパートナーを創造します。
Sesameは、自然で感情的に知的な会話を通じて対話するように設計された、生命感あふれるAIパーソナルコンパニオンを開発しています。「声の存在感」に焦点を当てることで、デジタル音声の「不気味の谷」を越えることを目指しています。このプラットフォームは、高度な対話型音声モデル(CSM)と軽量アイウェアのビジョンを組み合わせ、常にそばにいる協力的なパートナーを創造します。
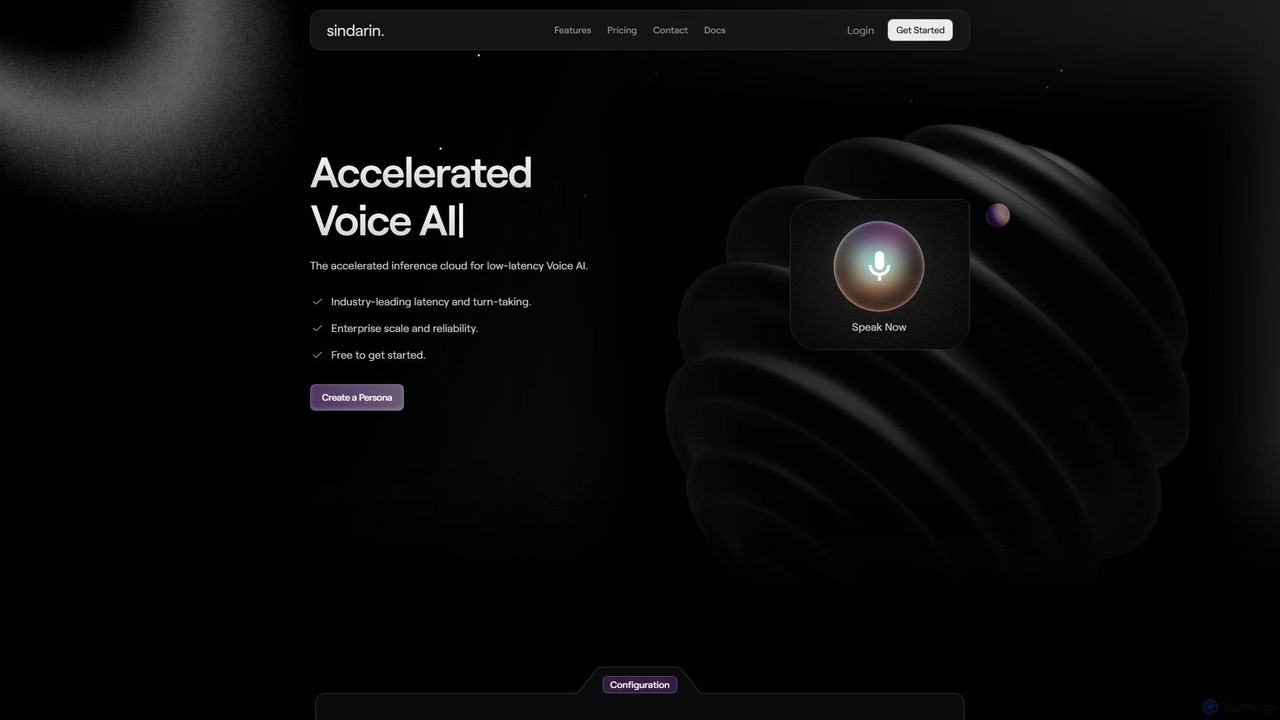
Sindarin
Sindarinは、開発者向けの低遅延・対話型音声AIを構築するための高速化されたクラウドプラットフォームです。APIとノーコードプラットフォームを提供し、応答性が高く自然な音声のAIペルソナを作成します。業界をリードするターンテーキングとシームレスな割り込み処理により、カスタマーサービス、ウェルネス、ゲームなどのアプリケーションで真の対話型音声体験を実現し、エンタープライズレベルのスケーラビリティと信頼性を提供します。
Sindarinは、開発者向けの低遅延・対話型音声AIを構築するための高速化されたクラウドプラットフォームです。APIとノーコードプラットフォームを提供し、応答性が高く自然な音声のAIペルソナを作成します。業界をリードするターンテーキングとシームレスな割り込み処理により、カスタマーサービス、ウェルネス、ゲームなどのアプリケーションで真の対話型音声体験を実現し、エンタープライズレベルのスケーラビリティと信頼性を提供します。
音声合成について
音声合成ツールは、テキスト読み上げ(TTS)ソフトウェアとも呼ばれ、書かれたテキストを人間のような聞き取りやすい音声に変換するAIアプリケーションの一種です。これらのツールは高度なディープラーニングモデルを活用し、自然なイントネーション、リズム、感情的なニュアンスを備えたリアルな音声を生成します。その主な価値は、ビデオやポッドキャスト、アクセシビリティ機能向けに高品質な音声コンテンツの作成を自動化し、手動での録音作業を不要にすることにあります。高度なプラットフォームでは、音声クローニングやブランドアイデンティティのため独自のカスタムボイスを作成する強力な機能も提供しています。
主な機能
- 高忠実度音声生成:人間の声と区別がつきにくいほど、クリアで自然な音声を生成します。
- 音声クローニングとカスタマイズ:特定の声のデジタルレプリカを作成したり、全く新しい独自の声をデザインしたりできます。
- 感情とスタイルの制御:感情的なトーン(例:喜び、悲しみ、怒り)や話し方(例:ニュースキャスター、対話風)を調整するオプションを提供します。
- 多言語・アクセント対応:グローバルなコンテンツ向けに、多数の言語や地域アクセントの幅広い音声を提供します。
- SSMLサポート:音声合成マークアップ言語(SSML)を使用して、発音、ピッチ、速度、間などを細かく制御できます。
利用シーン
音声合成ツールは、コンテンツ制作者がYouTubeビデオのナレーションやポッドキャストのナレーションを制作するために広く採用されています。企業環境では、eラーニングモジュールやプロフェッショナルなIVR(自動音声応答)システムの作成に使用されます。開発者はAPIを介してこの技術を統合し、音声対応アプリケーションを構築したり、視覚障害を持つユーザーのデジタルアクセシビリティを向上させたりします。
選び方のポイント
音声合成ツールを選ぶ際は、まず出力される音声の品質と自然さを評価してください。次に、音声クローニング、感情制御、言語サポートなどのカスタマイズオプションの範囲を検討します。開発者にとっては、APIの利用可能性とドキュメントが重要です。最後に、文字数ベース、サブスクリプション、API使用量など、さまざまな価格モデルを比較し、プロジェクトの規模に合ったものを見つけましょう。
音声合成利用シーン
プロフェッショナルなビデオナレーションの作成
コンテンツ制作者やマーケティングチームは、プロモーションビデオ、チュートリアル、ソーシャルメディアコンテンツ用に高品質のナレーションを必要とすることがよくあります。声優を雇ったりスタジオを予約したりする代わりに、音声合成ツールを使用します。スクリプトをアプリケーションに貼り付けるだけで、適切な声を選択し、トーンやペースを調整し、数分でクリーンな音声ファイルを生成できます。このプロセスにより、迅速なイテレーションとスクリプトの簡単な更新が可能になり、すべてのビデオアセットで一貫したブランドボイスを維持しながら、制作時間とコストを大幅に削減できます。
オーディオブックとポッドキャストコンテンツの生成
著者や出版社は、プロのナレーションにかかる高額な費用なしに、書かれた本を長編のオーディオブックに変換できます。原稿の章を音声合成プラットフォームに入力することで、何時間もの一貫した音声を制作できます。同様に、ブロガーやポッドキャスターは、記事を音声エピソードに変換し、読むよりも聞くことを好むオーディエンスにリーチを拡大できます。高度なツールでは、異なるキャラクターに異なる声を使用したり、ペースを制御して魅力的なリスニング体験を創出したりすることができ、コンテンツをよりアクセスしやすく、多用途にします。
アクセシブルなアプリケーションの開発
ソフトウェア開発者やUXデザイナーは、音声合成APIを使用して、製品にアクセシビリティ機能を組み込みます。たとえば、ニュースアプリケーションに「記事を聞く」ボタンを統合し、視覚障害のあるユーザーやマルチタスク中のユーザーのためにテキストを読み上げることができます。教育アプリでは、TTSが言語学習者に発音のガイダンスを提供できます。合成APIを活用することで、開発者は複雑な音声技術をゼロから構築することなく、アプリケーションが包括的でWCAGなどのアクセシビリティ基準に準拠していることを保証し、すべてのユーザーにより良い体験を提供できます。
カスタムブランドボイスの作成
独自のブランドアイデンティティを目指す企業は、音声クローニング機能を使用して、独占的なブランドボイスを作成できます。企業は声優を一度の録音セッションのために雇い、その後、音声合成ツールを使用してその声をクローンします。このデジタルボイスは、広告、IVRシステム、アプリ内アシスタントなど、すべてのタッチポイントで一貫して使用できます。このアプローチは、俳優を繰り返し雇うよりも費用対効果が高く、完全に一貫性があり認識可能なオーディオブランドアイデンティティを保証し、任何の新しいコンテンツに即座に展開できます。
企業eラーニングナレーションの自動化
大企業のインストラクショナルデザイナーは、多数のトレーニングモジュールの作成と更新を担当しています。各モジュールの音声をを手動で録音するのは時間がかかり、特に更新が必要な場合に一貫性を保つのが困難です。音声合成ツールを使用することで、すべてのコースに対して標準化されたクリアなナレーションを生成できます。ポリシーや手順が変更された場合、テキストを更新して音声を再生成するだけで、すべてのトレーニング資料が最新かつ統一されていることを保証できます。これにより、eラーニング開発ライフサイクル全体が合理化され、異なる言語へのローカライズがはるかに効率的になります。
音声ユーザーインターフェース(VUI)のプロトタイピング
スマートスピーカーのスキルや車載アシスタントなど、音声起動アプリケーションを作成するデザイナーや開発者は、会話フローをテストする必要があります。各イテレーションで複雑なコードを実装する代わりに、音声合成ツールを使用してスクリプトを迅速に音声に変換します。これにより、チームは対話がリアルタイムでどのように聞こえるかを確認し、不自然な表現を特定し、リアルな音声出力でユーザーエクスペリエンスをテストできます。この迅速なプロトタイピング手法は、設計プロセスを加速し、最終的なVUIの品質を向上させ、開発に着手する前に、よりユーザー中心のイテレーションを可能にします。