SUPIR
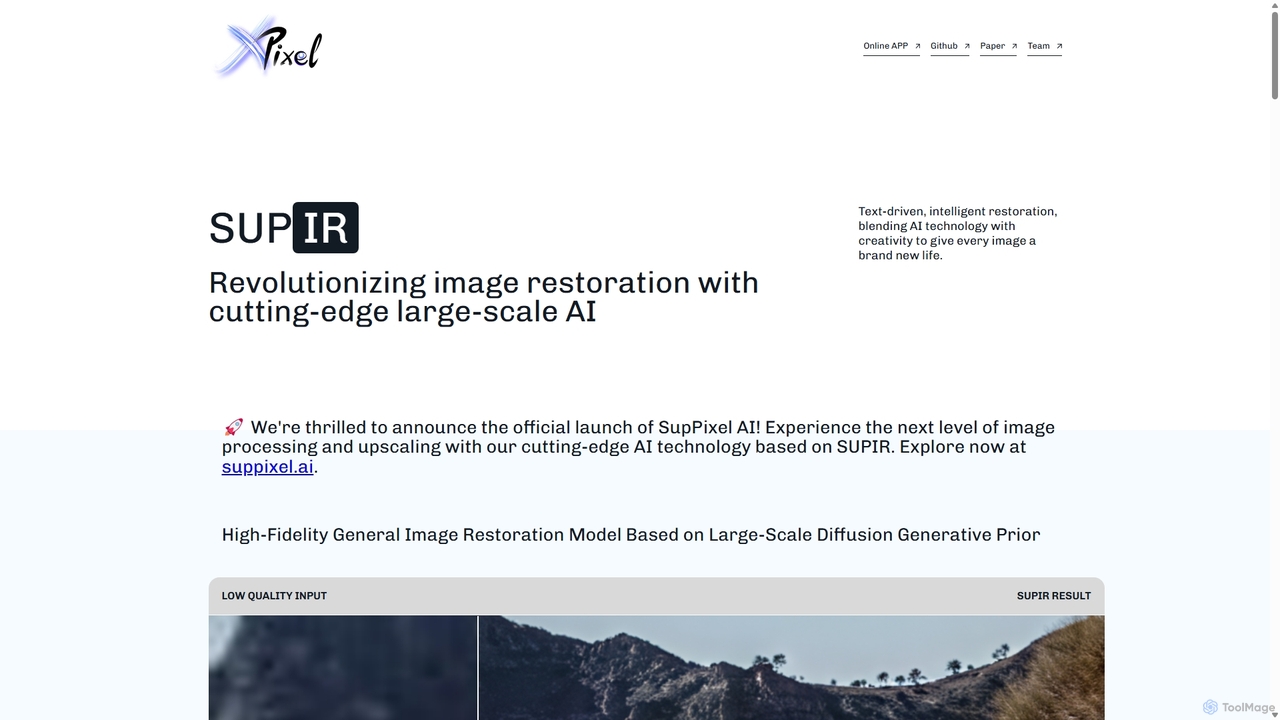
SUPIR(Scaling-up-Prior Image Restoration)は、最先端の高忠実度な汎用画像修復モデルです。大規模な拡散生成事前分布を活用し、驚くほどの鮮明さとディテールで画像をインテリジェントに修復・アップスケールします。古い写真からゲームアセットまで、SUPIRはあらゆる低品質画像に新たな命を吹き込みます。
SUPIR(Scaling-up-Prior Image Restoration)は、最先端の高忠実度な汎用画像修復モデルです。大規模な拡散生成事前分布を活用し、驚くほどの鮮明さとディテールで画像をインテリジェントに修復・アップスケールします。古い写真からゲームアセットまで、SUPIRはあらゆる低品質画像に新たな命を吹き込みます。
Vidu Studio AI
Vidu Studio AIは、テキストや画像をプロ品質のビデオに簡単に変換する最先端のAI搭載プラットフォームです。拡散モデルとトランスフォーマー技術の独自の融合を活用し、あらゆるスキルレベルのユーザーが簡単なプロンプトからリアルな物理演算とダイナミックなエフェクトを持つ高品質なビデオを作成できるようにし、ビデオ制作を迅速、簡単、かつアクセス可能にします。
Vidu Studio AIは、テキストや画像をプロ品質のビデオに簡単に変換する最先端のAI搭載プラットフォームです。拡散モデルとトランスフォーマー技術の独自の融合を活用し、あらゆるスキルレベルのユーザーが簡単なプロンプトからリアルな物理演算とダイナミックなエフェクトを持つ高品質なビデオを作成できるようにし、ビデオ制作を迅速、簡単、かつアクセス可能にします。
Flux1ai
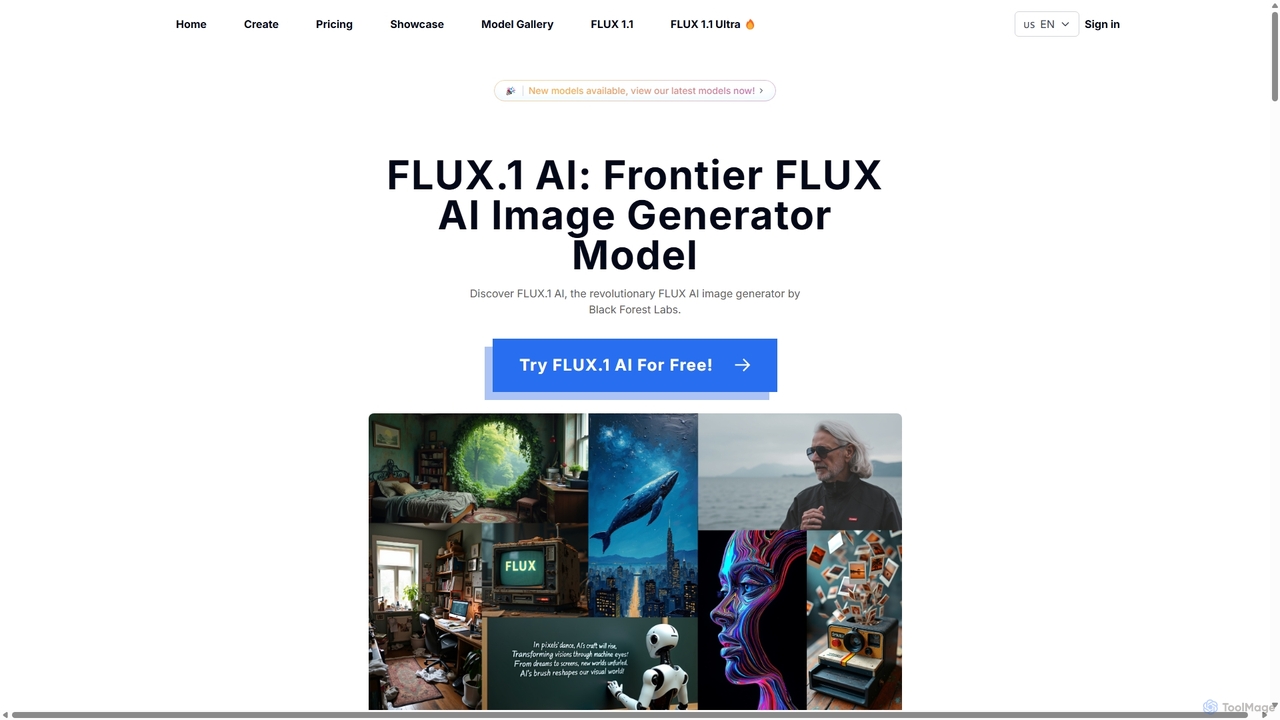
flux1aiは、Black Forest Labsによる革新的なテキストから画像を生成するAIジェネレーターです。迅速な生成からプロ級のフォトリアリズムまで、さまざまなニーズに合わせたモデル群を提供します。プロンプトの忠実度、視覚的な品質、スタイルの多様性に優れており、アーティスト、デザイナー、開発者にとって強力なツールです。
flux1aiは、Black Forest Labsによる革新的なテキストから画像を生成するAIジェネレーターです。迅速な生成からプロ級のフォトリアリズムまで、さまざまなニーズに合わせたモデル群を提供します。プロンプトの忠実度、視覚的な品質、スタイルの多様性に優れており、アーティスト、デザイナー、開発者にとって強力なツールです。

Decart
Decartは、リアルタイム生成モデルを開発する先駆的なAI企業です。その中核製品であるMirage、Oasis、Sidekickは、リアルタイムのビデオツービデオ変換、ゲーム用の生成型オープンワールド作成、トークツービデオ体験に特化しており、ライブストリーミング、ゲーム、インタラクティブエンターテイメントなどの業界を革新することを目指しています。
Decartは、リアルタイム生成モデルを開発する先駆的なAI企業です。その中核製品であるMirage、Oasis、Sidekickは、リアルタイムのビデオツービデオ変換、ゲーム用の生成型オープンワールド作成、トークツービデオ体験に特化しており、ライブストリーミング、ゲーム、インタラクティブエンターテイメントなどの業界を革新することを目指しています。
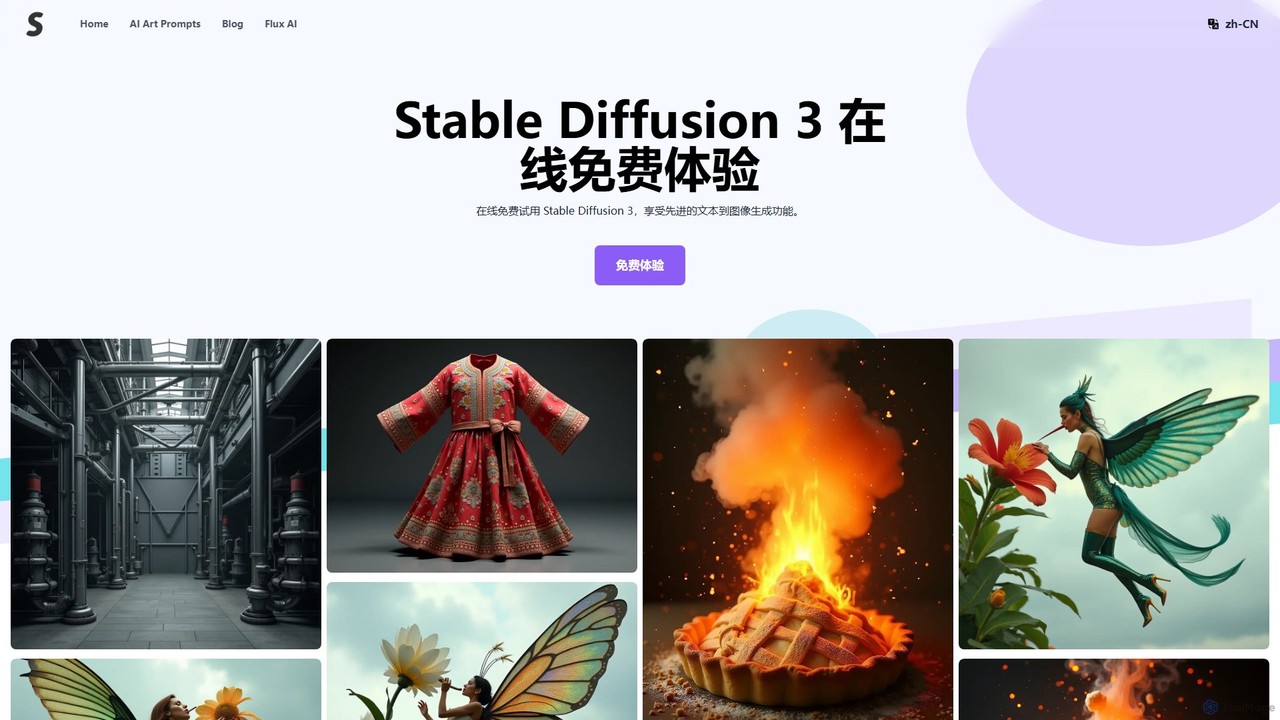
Stable Diffusion 3
Stable Diffusion 3は、Stability AIによる最先端のテキストから画像を生成するAIモデルです。画質、プロンプト追従性、特に画像内のテキスト描画が大幅に向上しています。また、Stable Video Diffusionによる画像から動画への変換機能も備えています。API、セルフホスティング、またはオンラインプラットフォームで無料トライアルが利用可能です。
Stable Diffusion 3は、Stability AIによる最先端のテキストから画像を生成するAIモデルです。画質、プロンプト追従性、特に画像内のテキスト描画が大幅に向上しています。また、Stable Video Diffusionによる画像から動画への変換機能も備えています。API、セルフホスティング、またはオンラインプラットフォームで無料トライアルが利用可能です。
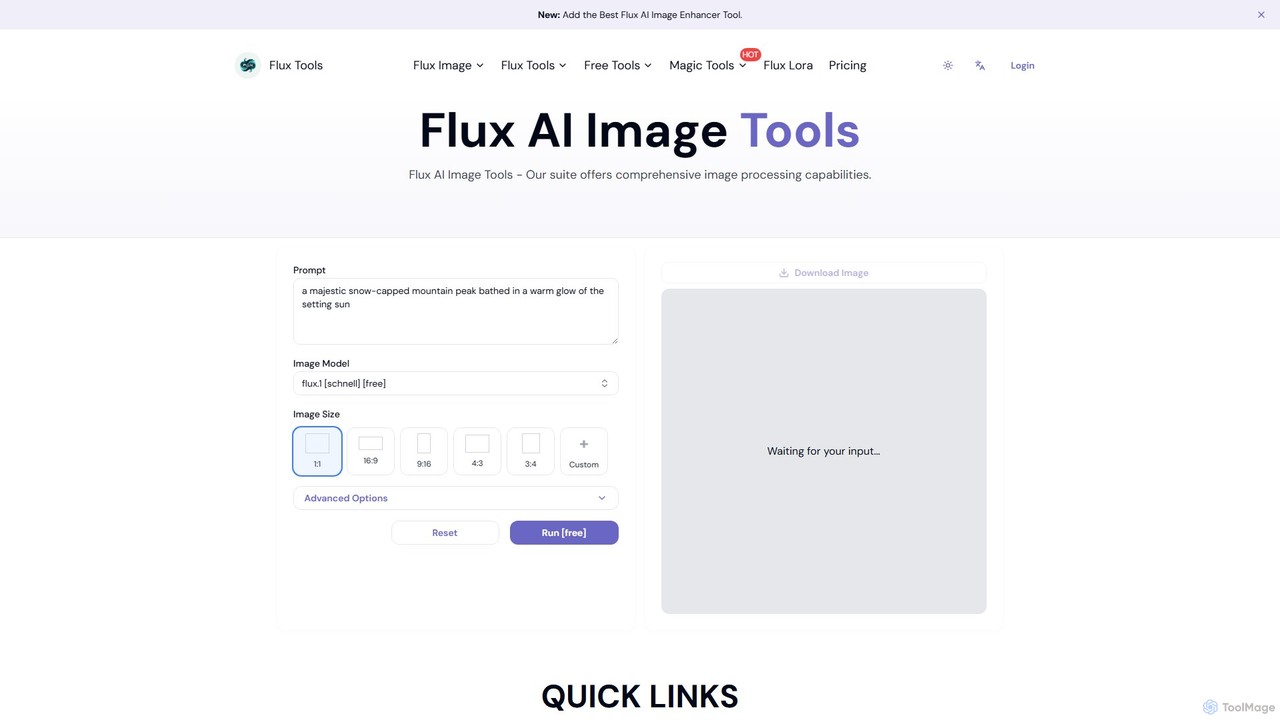
Fluxlora
Fluxloraは、LoRAモデルに特化した高度なAI画像生成スイートです。クリエイティブプロフェッショナルが、写実的な画像から抽象アートまで、高度に様式化され一貫性のあるビジュアルを制作できるようにします。Flux Toolsエコシステムの一部として、編集ツールとシームレスに統合され、完全なクリエイティブワークフローを提供します。
Fluxloraは、LoRAモデルに特化した高度なAI画像生成スイートです。クリエイティブプロフェッショナルが、写実的な画像から抽象アートまで、高度に様式化され一貫性のあるビジュアルを制作できるようにします。Flux Toolsエコシステムの一部として、編集ツールとシームレスに統合され、完全なクリエイティブワークフローを提供します。
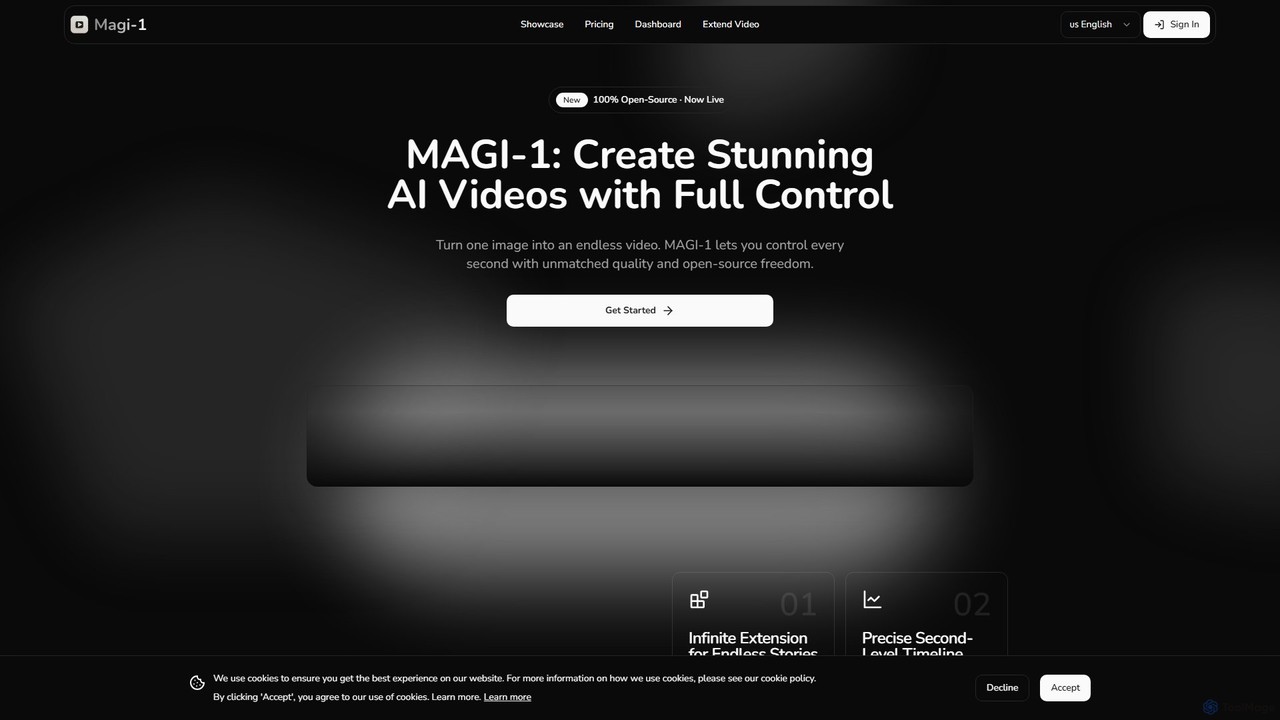
magi_1
MAGI-1は、AIビデオ生成のための革新的なオープンソース自己回帰拡散モデルです。ユーザーは簡単なテキストプロンプトから、驚くほどリアルで高解像度(最大1440p QHD)のビデオを作成できます。ビデオ拡張、詳細なパラメータ制御、リアルタイムストリーミングサポートなどの高度な機能を備え、MAGI-1はビジュアルコンテンツの限界を押し広げたいクリエイター、開発者、マーケター向けに設計されています。
MAGI-1は、AIビデオ生成のための革新的なオープンソース自己回帰拡散モデルです。ユーザーは簡単なテキストプロンプトから、驚くほどリアルで高解像度(最大1440p QHD)のビデオを作成できます。ビデオ拡張、詳細なパラメータ制御、リアルタイムストリーミングサポートなどの高度な機能を備え、MAGI-1はビジュアルコンテンツの限界を押し広げたいクリエイター、開発者、マーケター向けに設計されています。
imagenmia
imagenmiaは、テキスト記述を見事な高品質のビジュアルに変換する強力なAI画像ジェネレーターです。高度な拡散モデルを活用し、クリエイター、マーケター、デザイナーがデジタルアート、コンセプトデザインからマーケティング資料、ソーシャルメディアコンテンツまで、あらゆる目的でユニークでロイヤリティフリーの画像を制作できるようにします。
imagenmiaは、テキスト記述を見事な高品質のビジュアルに変換する強力なAI画像ジェネレーターです。高度な拡散モデルを活用し、クリエイター、マーケター、デザイナーがデジタルアート、コンセプトデザインからマーケティング資料、ソーシャルメディアコンテンツまで、あらゆる目的でユニークでロイヤリティフリーの画像を制作できるようにします。
Story Diffusion
Story Diffusionは、単一のプロンプトから一貫性のある一連の画像を生成するために設計された強力なAIモデルです。複数のフレームにわたってキャラクターとスタイルの一貫性を維持することで、AI画像生成における重要な課題を解決し、ビジュアルナラティブ、コミック、ストーリーボードの作成に優れています。
Story Diffusionは、単一のプロンプトから一貫性のある一連の画像を生成するために設計された強力なAIモデルです。複数のフレームにわたってキャラクターとスタイルの一貫性を維持することで、AI画像生成における重要な課題を解決し、ビジュアルナラティブ、コミック、ストーリーボードの作成に優れています。

aikiustudio
Aikiu Studioは、中小企業やスタートアップ向けに設計されたAI搭載のロゴジェネレーターです。デザインスキルがなくても、数分でユニークでプロフェッショナルなロゴを作成できます。このプラットフォームは、高度なAIモデルを使用して無数のオリジナルロゴアイデアを生成し、完全なカスタマイズ、高解像度ファイル、および完全な商用利用権を提供します。無料で始めることができ、デザインに完全に満足した場合にのみ料金が発生します。
Aikiu Studioは、中小企業やスタートアップ向けに設計されたAI搭載のロゴジェネレーターです。デザインスキルがなくても、数分でユニークでプロフェッショナルなロゴを作成できます。このプラットフォームは、高度なAIモデルを使用して無数のオリジナルロゴアイデアを生成し、完全なカスタマイズ、高解像度ファイル、および完全な商用利用権を提供します。無料で始めることができ、デザインに完全に満足した場合にのみ料金が発生します。
Diffusion Chat
拡散モデルと直接対話することで、魅力的なビジュアルを作成・洗練できる会話型AI画像ジェネレーター。アイデアをチャットするだけで、それが形になるのを見ることができます。直感的で反復的な創造プロセスを求めるアーティスト、デザイナー、クリエイターに最適です。
拡散モデルと直接対話することで、魅力的なビジュアルを作成・洗練できる会話型AI画像ジェネレーター。アイデアをチャットするだけで、それが形になるのを見ることができます。直感的で反復的な創造プロセスを求めるアーティスト、デザイナー、クリエイターに最適です。
Fine Pixel
Fine Pixelは、ビジュアルを強化、生成、編集するオールインワンのAI搭載イメージスイートです。印刷品質(300+ DPI)を実現する高解像度画像アップスケーラー、即座の創造性を可能にするテキストから画像へのジェネレーター(DaVinci Diffusion XL)、写真からオブジェクトをシームレスに追加・削除するインペインティングツールを備えています。マーケターやデザイナーから個人ユーザーまで、あらゆるスキルレベルのユーザー向けに設計されており、プロ級の画像操作を数秒で実現します。
Fine Pixelは、ビジュアルを強化、生成、編集するオールインワンのAI搭載イメージスイートです。印刷品質(300+ DPI)を実現する高解像度画像アップスケーラー、即座の創造性を可能にするテキストから画像へのジェネレーター(DaVinci Diffusion XL)、写真からオブジェクトをシームレスに追加・削除するインペインティングツールを備えています。マーケターやデザイナーから個人ユーザーまで、あらゆるスキルレベルのユーザー向けに設計されており、プロ級の画像操作を数秒で実現します。

EDGE
EDGE(Editable Dance Generation from Music)は、あらゆる音楽トラックからリアルで物理的に妥当な、編集可能な3Dダンスアニメーションを作成する強力なAIモデルです。トランスフォーマーベースの拡散モデルを使用し、オーディオと完全に同期した高忠実度のモーションを保証します。
EDGE(Editable Dance Generation from Music)は、あらゆる音楽トラックからリアルで物理的に妥当な、編集可能な3Dダンスアニメーションを作成する強力なAIモデルです。トランスフォーマーベースの拡散モデルを使用し、オーディオと完全に同期した高忠実度のモーションを保証します。
fluxaionline
Fluxaionlineは、Black Forest Labsの高度なFLUX.1モデルを搭載した高速AI画像ジェネレーターです。テキストプロンプトを数秒で高品質で多様な画像に変換します。プロのデザインから迅速な制作まで、さまざまなニーズに対応する複数のモデルを提供し、使いやすいインターフェース、豊富な無料プラン、柔軟な従量課金制を備えており、初心者からプロのアーティストまで幅広く利用できます。
Fluxaionlineは、Black Forest Labsの高度なFLUX.1モデルを搭載した高速AI画像ジェネレーターです。テキストプロンプトを数秒で高品質で多様な画像に変換します。プロのデザインから迅速な制作まで、さまざまなニーズに対応する複数のモデルを提供し、使いやすいインターフェース、豊富な無料プラン、柔軟な従量課金制を備えており、初心者からプロのアーティストまで幅広く利用できます。
Genfluence
Genfluenceは、バーチャルインフルエンサーやデジタルキャラクターを作成・生成するためのAI搭載プラットフォームです。高度な拡散技術を使用し、ユーザーは外見、服装から特定のポーズまで詳細にカスタマイズして、ユニークで高品質なキャラクターを簡単にデザインできます。従来の撮影コストなしで独自のデジタルプレゼンスを構築したいマーケター、コンテンツクリエーター、ブランドに最適です。
Genfluenceは、バーチャルインフルエンサーやデジタルキャラクターを作成・生成するためのAI搭載プラットフォームです。高度な拡散技術を使用し、ユーザーは外見、服装から特定のポーズまで詳細にカスタマイズして、ユニークで高品質なキャラクターを簡単にデザインできます。従来の撮影コストなしで独自のデジタルプレゼンスを構築したいマーケター、コンテンツクリエーター、ブランドに最適です。
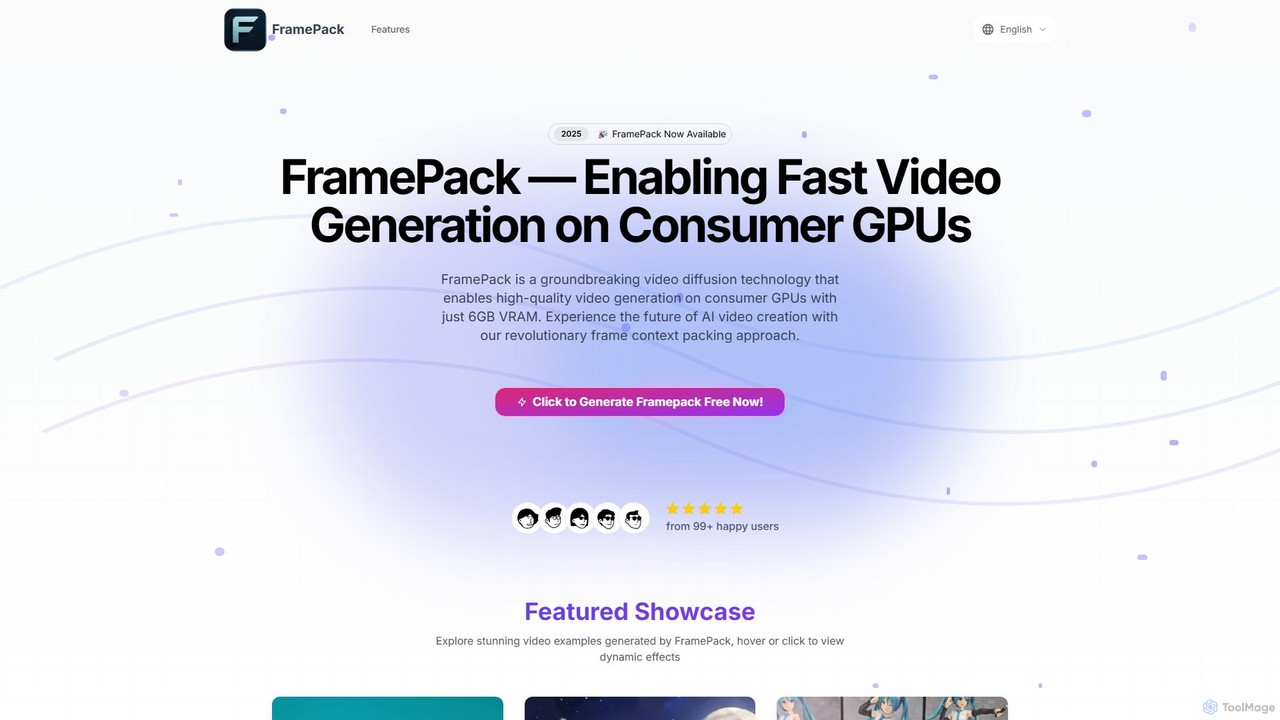
FramePack
FramePackは、わずか6GBのVRAMを搭載したローカルのコンシューマー向けGPUで高品質なAIビデオ生成を可能にする、画期的なオープンソースのビデオ拡散技術です。クリエイター、アニメーター、研究者が高価なクラウドサービスに頼ることなく、一貫性のある長いビデオシーケンスを制作するための、コスト効率が高く、プライベートでカスタマイズ可能なソリューションを提供します。
FramePackは、わずか6GBのVRAMを搭載したローカルのコンシューマー向けGPUで高品質なAIビデオ生成を可能にする、画期的なオープンソースのビデオ拡散技術です。クリエイター、アニメーター、研究者が高価なクラウドサービスに頼ることなく、一貫性のある長いビデオシーケンスを制作するための、コスト効率が高く、プライベートでカスタマイズ可能なソリューションを提供します。
AI Photos
AI Photosは、テキスト記述を驚くほど高品質な写真やデジタルアートに変換する強力なAI画像生成プラットフォームです。高度な拡散モデルを活用し、アーティスト、デザイナー、マーケターに広範な創造的コントロールを提供し、フォトリアルな画像から様式化されたイラストまで、ユニークなビジュアルを数秒で生成します。
AI Photosは、テキスト記述を驚くほど高品質な写真やデジタルアートに変換する強力なAI画像生成プラットフォームです。高度な拡散モデルを活用し、アーティスト、デザイナー、マーケターに広範な創造的コントロールを提供し、フォトリアルな画像から様式化されたイラストまで、ユニークなビジュアルを数秒で生成します。
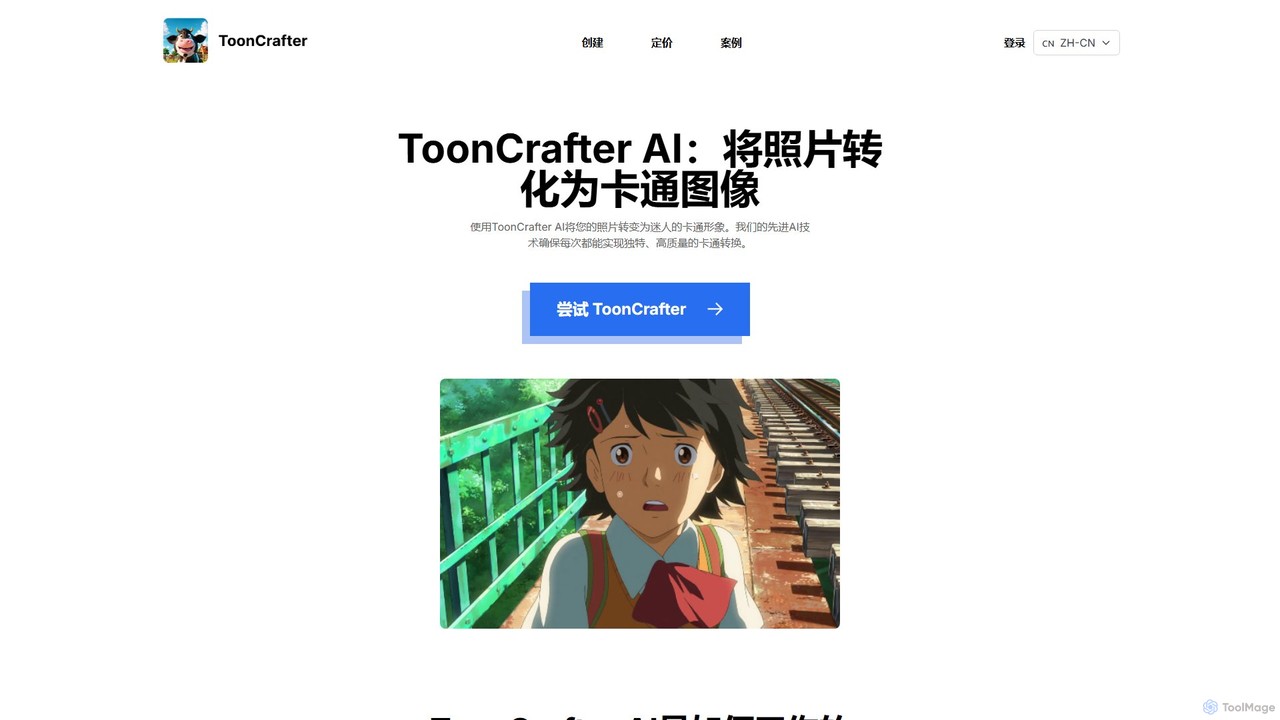
ToonCrafter
ToonCrafterは、静止画像を動的なカートゥーンアニメーションに変換する革新的なAIツールです。高度な画像から動画への拡散モデルを活用し、2つのキーフレーム間をシームレスに補間することで、ユーザーはスケッチや写真から流れるような視覚的な物語を作成できます。アニメーター、コンテンツ制作者、アーティストが最小限の労力でキャラクターに命を吹き込むのに最適です。
ToonCrafterは、静止画像を動的なカートゥーンアニメーションに変換する革新的なAIツールです。高度な画像から動画への拡散モデルを活用し、2つのキーフレーム間をシームレスに補間することで、ユーザーはスケッチや写真から流れるような視覚的な物語を作成できます。アニメーター、コンテンツ制作者、アーティストが最小限の労力でキャラクターに命を吹き込むのに最適です。
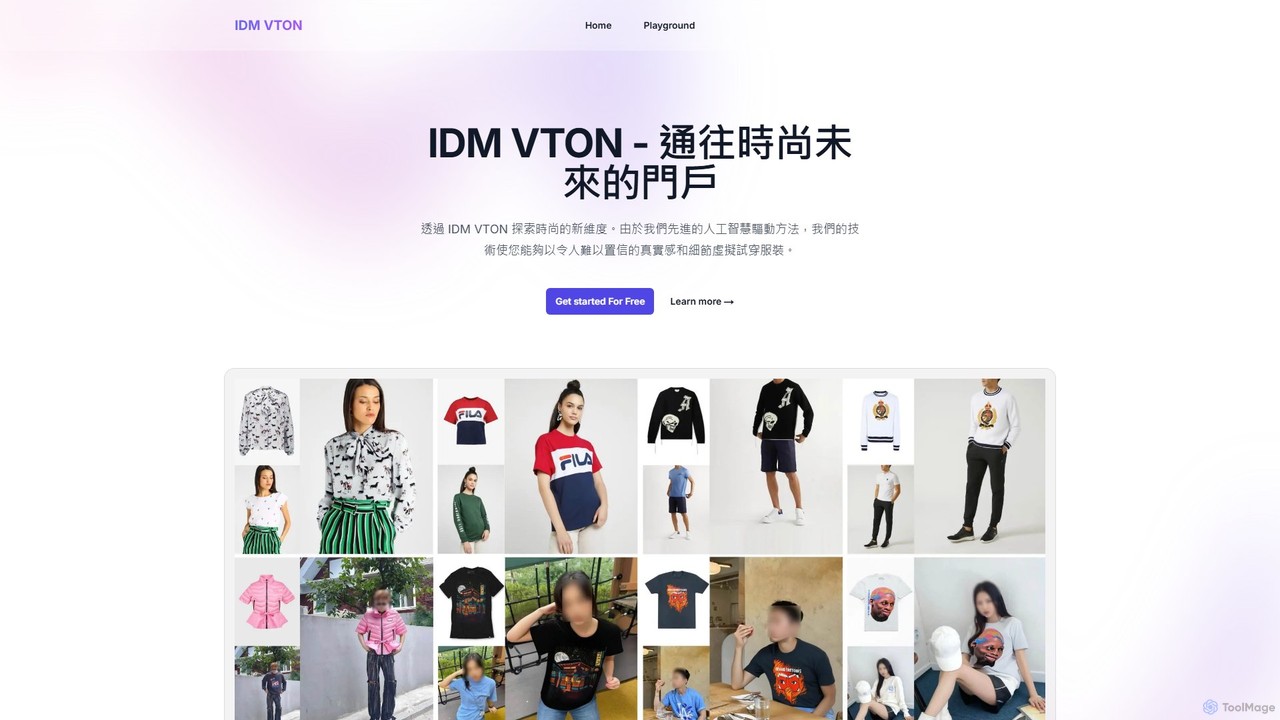
IDM VTON
IDM VTONは、AIを活用した仮想試着プラットフォームで、ユーザーは写真1枚でリアルに服を試着できます。高度な拡散モデルを利用し、様々な体型や服装スタイルに対応するシームレスで包括的な体験を提供し、消費者とEコマースビジネス双方のオンラインファッションショッピング体験を革新します。
IDM VTONは、AIを活用した仮想試着プラットフォームで、ユーザーは写真1枚でリアルに服を試着できます。高度な拡散モデルを利用し、様々な体型や服装スタイルに対応するシームレスで包括的な体験を提供し、消費者とEコマースビジネス双方のオンラインファッションショッピング体験を革新します。

Flux Image Generator
Flux Image Generatorは、テキスト記述を驚異的な速度と精度で高品質な画像に変換する最先端のAIツールです。多様なニーズに応えるため、Schnell(高速&無料)、Dev(開発者向け)、Pro(プロ向け)の3つの異なるモデルを提供しています。ハイブリッドアーキテクチャを活用し、プロンプトの忠実度、写実的な品質、手やテキストなどの複雑なディテールのレンダリングに優れており、他の主要な画像生成ツールに代わる強力な選択肢となります。
Flux Image Generatorは、テキスト記述を驚異的な速度と精度で高品質な画像に変換する最先端のAIツールです。多様なニーズに応えるため、Schnell(高速&無料)、Dev(開発者向け)、Pro(プロ向け)の3つの異なるモデルを提供しています。ハイブリッドアーキテクチャを活用し、プロンプトの忠実度、写実的な品質、手やテキストなどの複雑なディテールのレンダリングに優れており、他の主要な画像生成ツールに代わる強力な選択肢となります。

Inception Labs
Inception Labsは、従来のモデルより最大10倍高速かつ低コストな新世代の拡散型大規模言語モデル(dLLM)を発表します。並列的な拡散ベースのアプローチを活用し、テキストとコードの生成において前例のない速度、品質、制御性を提供し、エンタープライズレベルのアプリケーションに最適です。
Inception Labsは、従来のモデルより最大10倍高速かつ低コストな新世代の拡散型大規模言語モデル(dLLM)を発表します。並列的な拡散ベースのアプローチを活用し、テキストとコードの生成において前例のない速度、品質、制御性を提供し、エンタープライズレベルのアプリケーションに最適です。
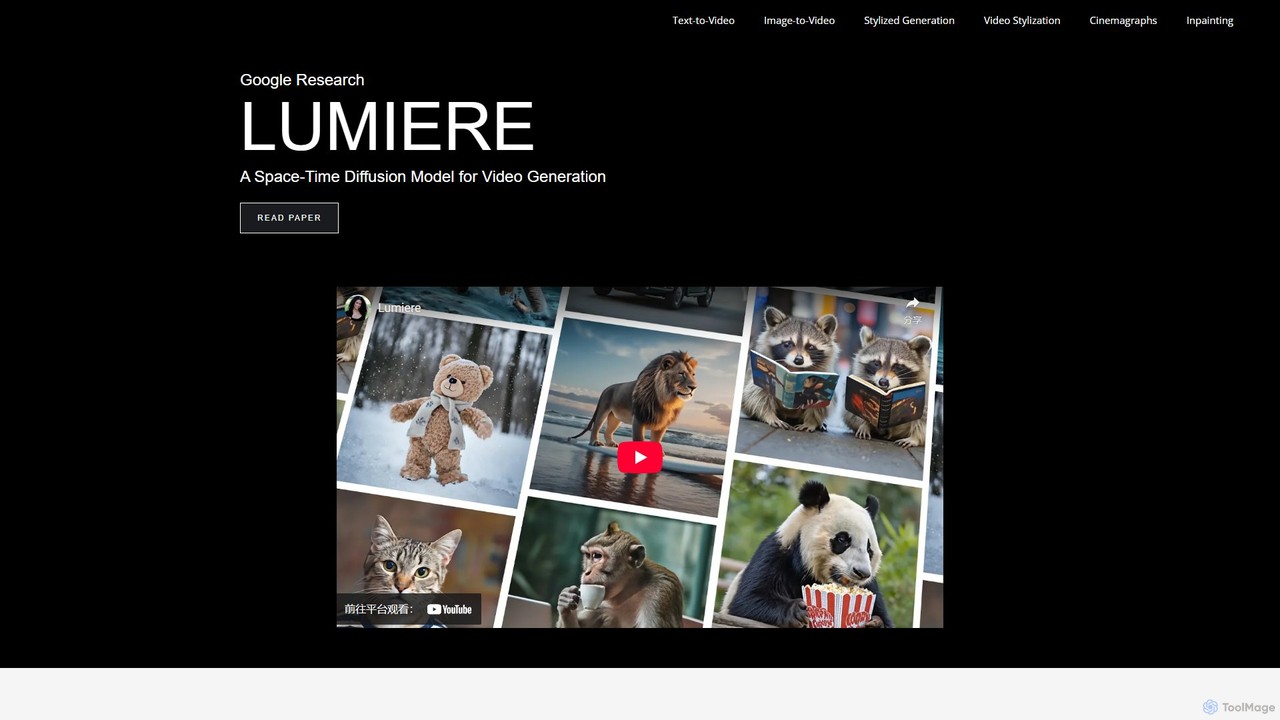
Lumiere
Lumiereは、Google Researchによる最先端のテキストからビデオへの拡散モデルです。リアルで多様、かつ一貫性のある動きを持つビデオを生成するために設計されています。独自のSpace-Time U-Netアーキテクチャは、ビデオの全持続時間を一度のパスで生成し、卓越した時間的整合性を確保し、幅広いビデオ作成および編集タスクを可能にします。
Lumiereは、Google Researchによる最先端のテキストからビデオへの拡散モデルです。リアルで多様、かつ一貫性のある動きを持つビデオを生成するために設計されています。独自のSpace-Time U-Netアーキテクチャは、ビデオの全持続時間を一度のパスで生成し、卓越した時間的整合性を確保し、幅広いビデオ作成および編集タスクを可能にします。

OmniGen AI
OmniGen AIは、テキストから画像生成、画像編集、制御された生成を単一のフレームワークに統合した、強力なオープンソースのAI画像生成プラットフォームです。高度なDiffusion TransformerモデルとOminiControl技術を活用し、ユーザーはテキストプロンプトから高品質なビジュアルを作成し、既存の画像を精密に編集し、バーチャル試着、背景除去、被写体主導の生成などの機能をかつてない容易さと制御性で利用できます。
OmniGen AIは、テキストから画像生成、画像編集、制御された生成を単一のフレームワークに統合した、強力なオープンソースのAI画像生成プラットフォームです。高度なDiffusion TransformerモデルとOminiControl技術を活用し、ユーザーはテキストプロンプトから高品質なビジュアルを作成し、既存の画像を精密に編集し、バーチャル試着、背景除去、被写体主導の生成などの機能をかつてない容易さと制御性で利用できます。
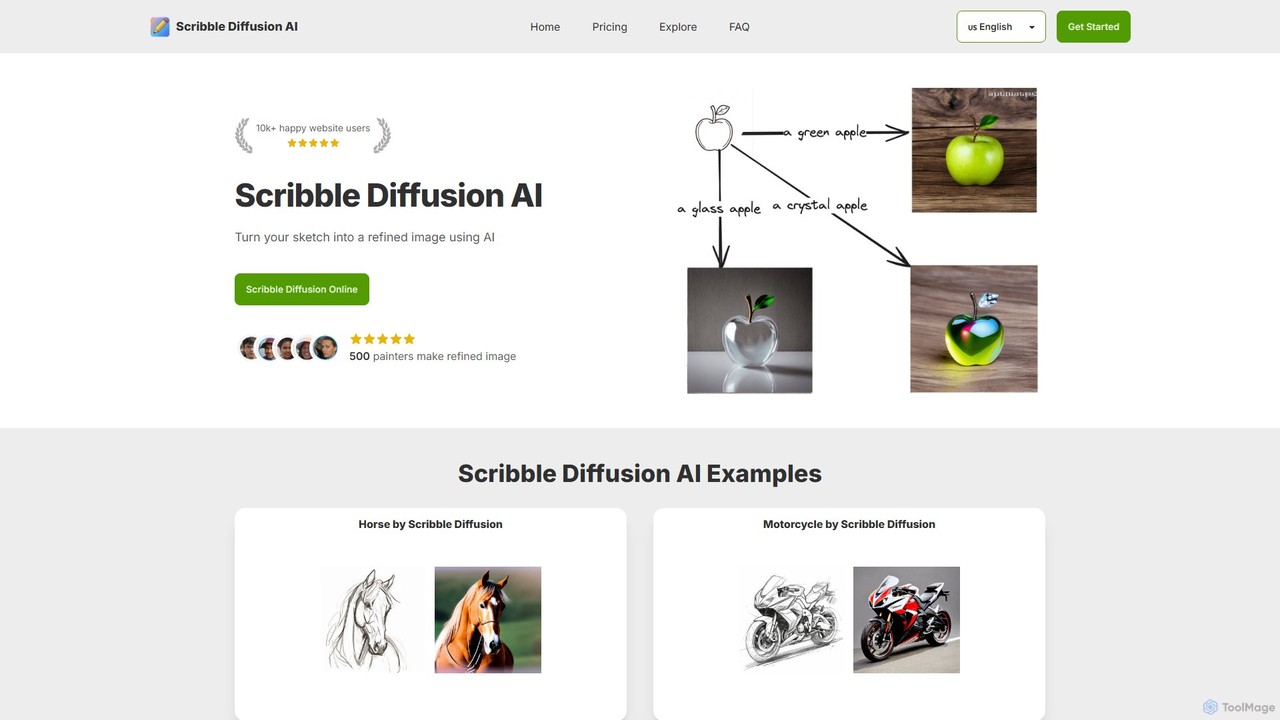
Scribble Diffusion
Scribble Diffusionは、簡単なスケッチとテキストプロンプトを、精細で高品質な画像に変換するAI搭載ツールです。アーティスト、デザイナー、趣味で絵を描く人が、アイデアを素早く視覚化し、コンセプトアートを作成し、想像力を簡単に形にできるよう設計されています。無料で始めて、あなたの落書きを傑作に変えましょう。
Scribble Diffusionは、簡単なスケッチとテキストプロンプトを、精細で高品質な画像に変換するAI搭載ツールです。アーティスト、デザイナー、趣味で絵を描く人が、アイデアを素早く視覚化し、コンセプトアートを作成し、想像力を簡単に形にできるよう設計されています。無料で始めて、あなたの落書きを傑作に変えましょう。
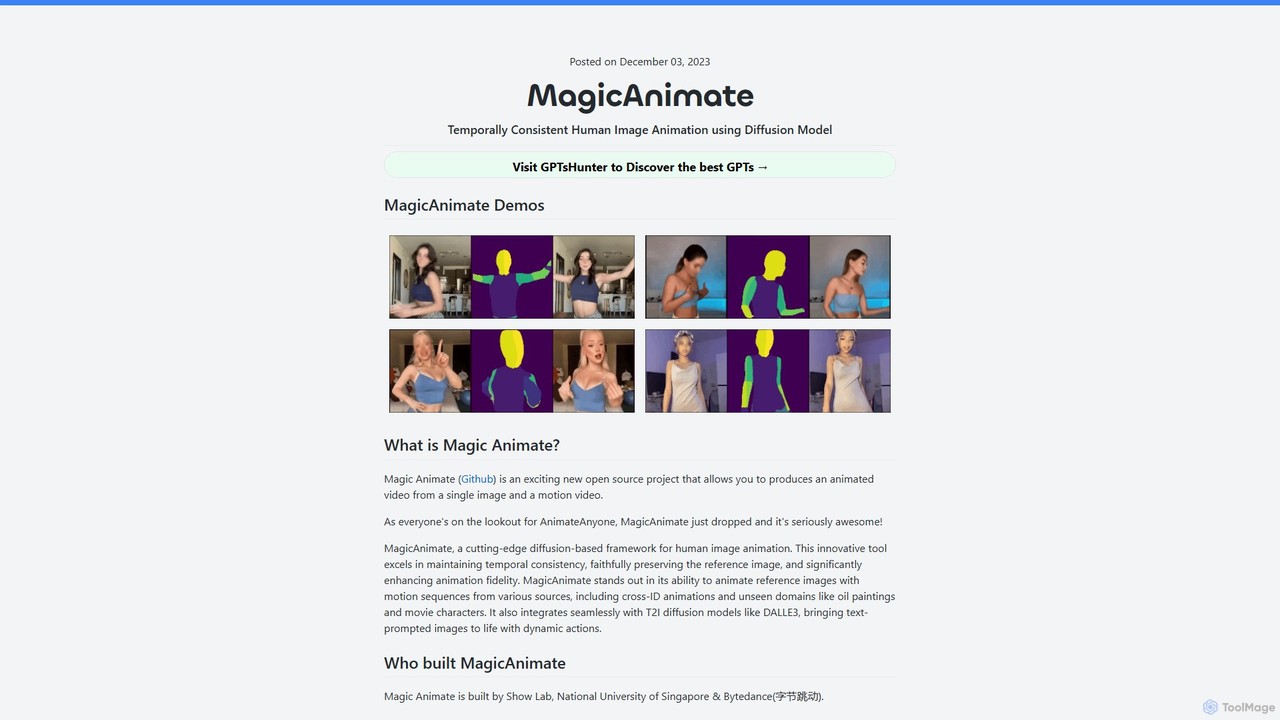
MagicAnimate
MagicAnimateは、ビデオのモーションシーケンスを使用して人物画像をアニメーション化する強力なオープンソースAIフレームワークです。ByteDanceとシンガポール国立大学の研究者によって開発され、拡散モデルを使用して時間的に一貫性のある高忠実度のアニメーションを作成し、動的な動きを適用しながら被写体のアイデンティティを保持します。
MagicAnimateは、ビデオのモーションシーケンスを使用して人物画像をアニメーション化する強力なオープンソースAIフレームワークです。ByteDanceとシンガポール国立大学の研究者によって開発され、拡散モデルを使用して時間的に一貫性のある高忠実度のアニメーションを作成し、動的な動きを適用しながら被写体のアイデンティティを保持します。