Nexa SDK
Nexa SDKは、最先端のAIモデルを含むあらゆるAIモデルを、モバイル、PC、IoT、自動車など、あらゆるデバイスに数分でデプロイできる強力なツールキットです。NPU、GPU、CPU全体でハードウェアアクセラレーションを備えた本番環境対応のオンデバイス推論を提供し、速度とエネルギー効率のために最適化されています。
Nexa SDKは、最先端のAIモデルを含むあらゆるAIモデルを、モバイル、PC、IoT、自動車など、あらゆるデバイスに数分でデプロイできる強力なツールキットです。NPU、GPU、CPU全体でハードウェアアクセラレーションを備えた本番環境対応のオンデバイス推論を提供し、速度とエネルギー効率のために最適化されています。
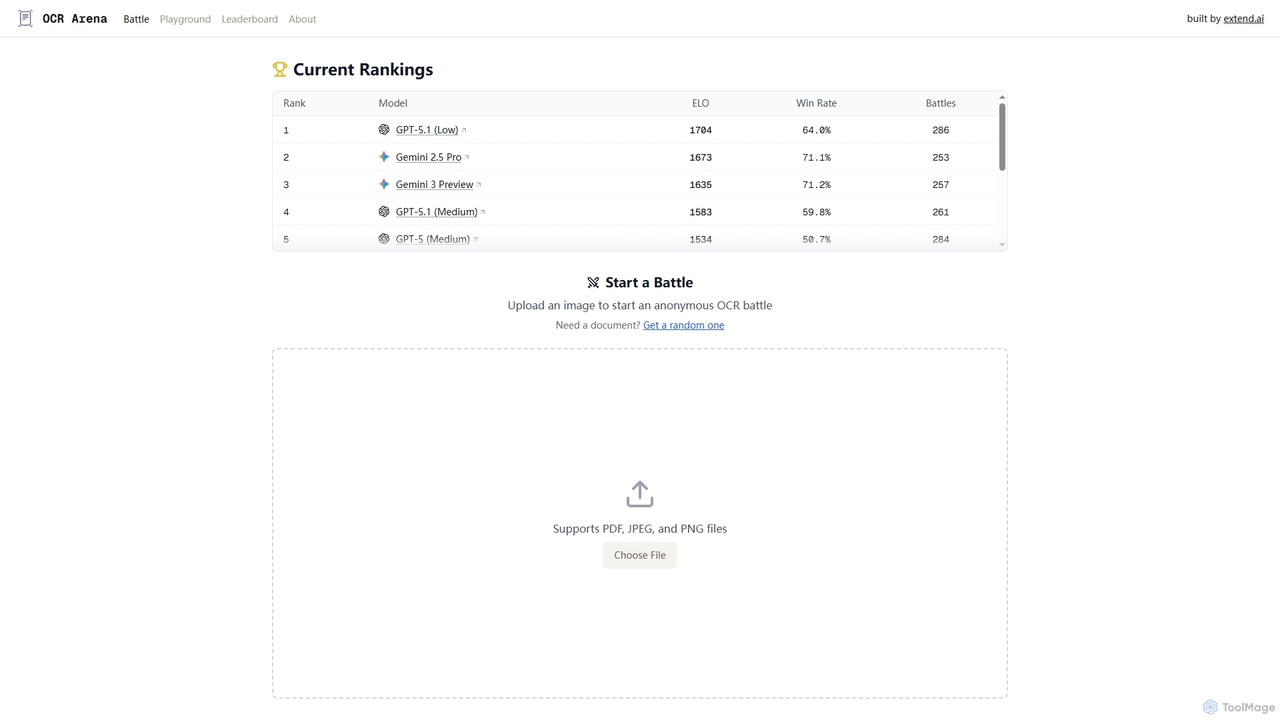
OCR Arena
OCR Arenaは、主要な基盤視覚言語モデル(VLM)およびオープンソースの光学文字認識(OCR)モデルをテストおよび評価するために設計された無料のオンラインプラットフォームです。ユーザーはドキュメントをアップロードし、精度を測定し、公開リーダーボードでモデルのパフォーマンスを比較できます。
OCR Arenaは、主要な基盤視覚言語モデル(VLM)およびオープンソースの光学文字認識(OCR)モデルをテストおよび評価するために設計された無料のオンラインプラットフォームです。ユーザーはドキュメントをアップロードし、精度を測定し、公開リーダーボードでモデルのパフォーマンスを比較できます。
Hakko
Hakkoは、ビジュアル言語モデル(VLM)を活用し、リアルタイムの音声ガイダンス、感情的な仲間、そして様々なゲームにおけるインテリジェントな支援を提供する高度なAIゲームコンパニオンです。シーン認識、知識検索、パーソナライズされたインタラクションでゲーム体験を向上させ、日常生活のシナリオにもサポートを拡大し、真に統合されたAIパートナーシップを実現します。
Hakkoは、ビジュアル言語モデル(VLM)を活用し、リアルタイムの音声ガイダンス、感情的な仲間、そして様々なゲームにおけるインテリジェントな支援を提供する高度なAIゲームコンパニオンです。シーン認識、知識検索、パーソナライズされたインタラクションでゲーム体験を向上させ、日常生活のシナリオにもサポートを拡大し、真に統合されたAIパートナーシップを実現します。
Gabber
Gabberは、見て、聞いて、話すことができるリアルタイムのマルチモーダルAIアプリケーションを構築するための強力なプラットフォームです。VLM(Vision Language Models)、TTS(Text-to-Speech)、STT(Speech-to-Text)の低遅延推論と、迅速な開発とデプロイメントのためのグラフベースのオーケストレーションシステムを組み合わせて提供します。
Gabberは、見て、聞いて、話すことができるリアルタイムのマルチモーダルAIアプリケーションを構築するための強力なプラットフォームです。VLM(Vision Language Models)、TTS(Text-to-Speech)、STT(Speech-to-Text)の低遅延推論と、迅速な開発とデプロイメントのためのグラフベースのオーケストレーションシステムを組み合わせて提供します。
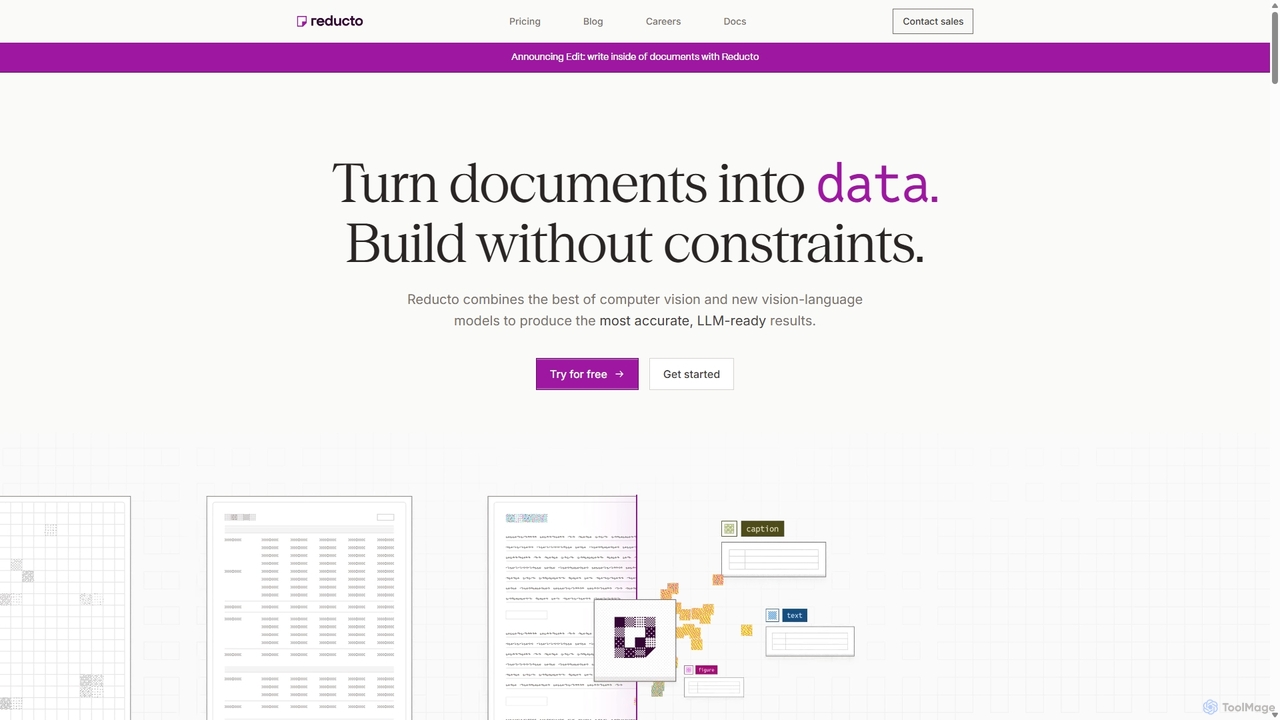
Reducto
Reductoは、開発者および企業向けの高度なドキュメント取り込みAPIです。Agentic OCRと視覚言語モデルを使用して、ドキュメントを正確に解析、分割、抽出し、編集まで行います。様々なファイル形式の非構造化データを、構造化されたLLM対応の入力に変換し、複雑なドキュメント処理ワークフローを高い精度とエンタープライズレベルのセキュリティで自動化します。
Reductoは、開発者および企業向けの高度なドキュメント取り込みAPIです。Agentic OCRと視覚言語モデルを使用して、ドキュメントを正確に解析、分割、抽出し、編集まで行います。様々なファイル形式の非構造化データを、構造化されたLLM対応の入力に変換し、複雑なドキュメント処理ワークフローを高い精度とエンタープライズレベルのセキュリティで自動化します。
Moondream
Moondreamは、非常に軽量かつ高速な、強力なオープンソースの視覚言語モデル(VLM)です。わずか1GBの小さなフットプリントで、エッジデバイスからラップトップまでどこでも動作します。開発者は、複雑なトレーニングや重いインフラを必要とせず、簡単なテキストプロンプトで画像を理解し、キャプション生成、物体検出、OCR、視覚的な質問応答などのタスクを実行できます。シンプルさ、多機能性、手頃な価格を追求して設計されています。
Moondreamは、非常に軽量かつ高速な、強力なオープンソースの視覚言語モデル(VLM)です。わずか1GBの小さなフットプリントで、エッジデバイスからラップトップまでどこでも動作します。開発者は、複雑なトレーニングや重いインフラを必要とせず、簡単なテキストプロンプトで画像を理解し、キャプション生成、物体検出、OCR、視覚的な質問応答などのタスクを実行できます。シンプルさ、多機能性、手頃な価格を追求して設計されています。
Prism Replay
Prism Replayは、ユーザーセッションリプレイを自動的に視聴、要約、分析するAIネイティブの製品分析プラットフォームです。手作業なしで実用的なインサイトを提供し、製品チームがコンバージョンを最適化し、ユーザー行動を理解し、問題点を特定するのを支援します。
Prism Replayは、ユーザーセッションリプレイを自動的に視聴、要約、分析するAIネイティブの製品分析プラットフォームです。手作業なしで実用的なインサイトを提供し、製品チームがコンバージョンを最適化し、ユーザー行動を理解し、問題点を特定するのを支援します。
Oda Studio
Oda Studioは、複雑な非構造化データを実用的なインサイトに変換するためのオーダーメイドAIソリューションを提供します。ビジョン言語モデル(VLM)とカスタムデータパイプラインを専門とし、建設、金融、メディアなどの業界にサービスを提供しています。専門家チームがデータ注釈からモデル展開までエンドツーエンドのサービスを提供し、企業がより賢く、より迅速な意思決定を行えるよう支援します。
Oda Studioは、複雑な非構造化データを実用的なインサイトに変換するためのオーダーメイドAIソリューションを提供します。ビジョン言語モデル(VLM)とカスタムデータパイプラインを専門とし、建設、金融、メディアなどの業界にサービスを提供しています。専門家チームがデータ注釈からモデル展開までエンドツーエンドのサービスを提供し、企業がより賢く、より迅速な意思決定を行えるよう支援します。
OpalAi
OpalAiは、複雑な空間、視覚、テキスト、音声データを企業向けの実用的なインサイトに変換する高度な空間AIプラットフォームです。視覚言語モデル(VLM)や3D再構築などの最先端技術を活用し、PropTech、InsurTech、交通、山火事管理などの業界に特化したソリューションを提供し、データ駆動型の意思決定を加速させます。
OpalAiは、複雑な空間、視覚、テキスト、音声データを企業向けの実用的なインサイトに変換する高度な空間AIプラットフォームです。視覚言語モデル(VLM)や3D再構築などの最先端技術を活用し、PropTech、InsurTech、交通、山火事管理などの業界に特化したソリューションを提供し、データ駆動型の意思決定を加速させます。
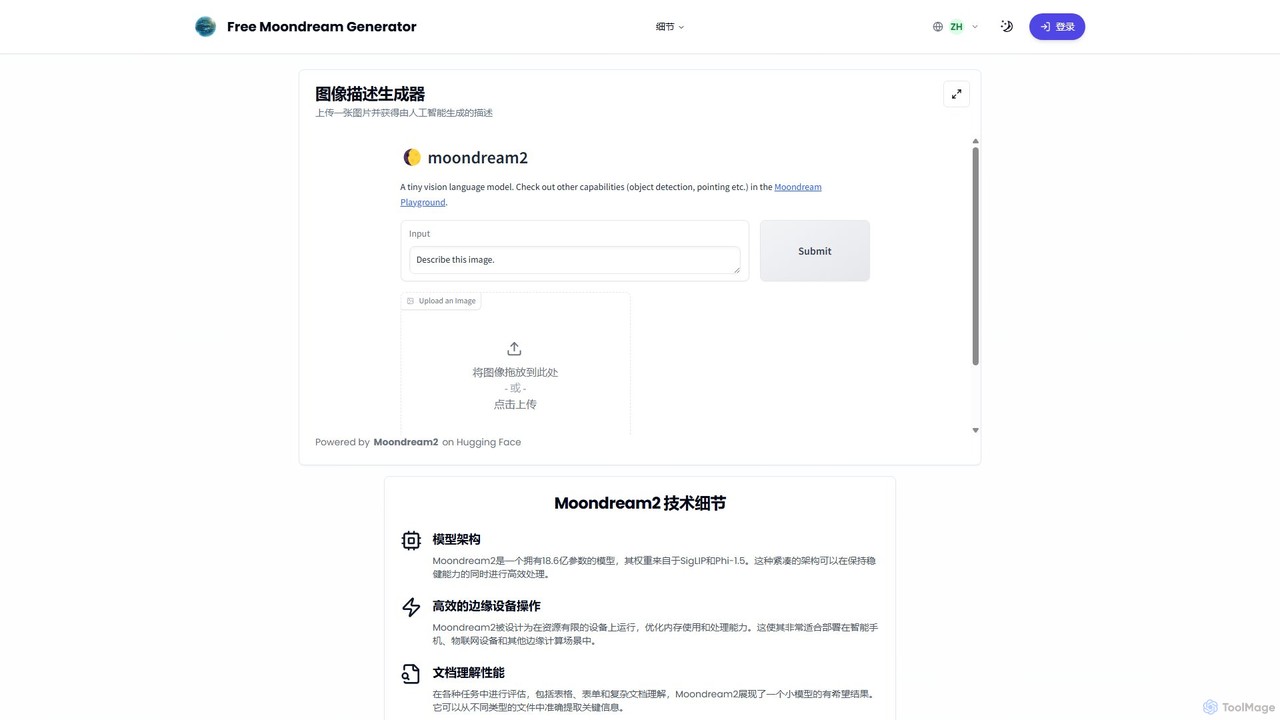
moondream2
moondream2は、エッジデバイスでの高効率を目指して設計された、軽量なオープンソースの視覚言語モデル(VLM)です。画像の説明生成、複雑な文書の理解、視覚的な質疑応答に優れており、リソースが限られたモバイルアプリケーションやIoTシナリオに最適です。
moondream2は、エッジデバイスでの高効率を目指して設計された、軽量なオープンソースの視覚言語モデル(VLM)です。画像の説明生成、複雑な文書の理解、視覚的な質疑応答に優れており、リソースが限られたモバイルアプリケーションやIoTシナリオに最適です。