Sinkove
Sinkove é uma plataforma de IA que gera dados de radiologia sintéticos de alta qualidade. Ajuda pesquisadores médicos …
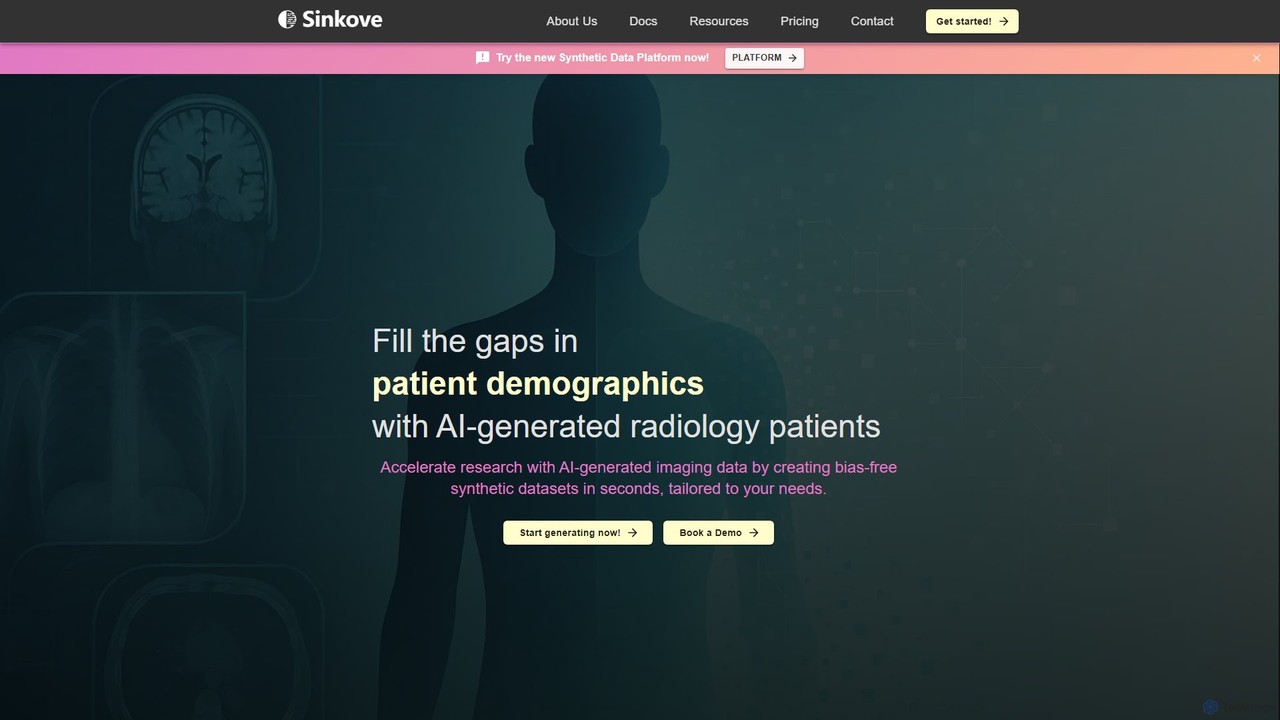
Sinkove é uma plataforma de IA que gera dados de radiologia sintéticos de alta qualidade. Ajuda pesquisadores médicos e clínicos a acelerar a pesquisa, eliminar o viés de dados e reduzir custos, criando conjuntos de dados de imagem personalizados, diversos e de nível regulatório em segundos.

maketafi
A Tafi é uma fornecedora líder de conjuntos de dados de personagens 3D de nível empresarial para treinamento …
A Tafi é uma fornecedora líder de conjuntos de dados de personagens 3D de nível empresarial para treinamento de IA, simulação e criação de conteúdo. Oferece personagens 3D escaláveis, com topologia consistente e gerados parametricamente, completos com metadados ricos, para alimentar modelos avançados de IA em robótica, jogos, XR e aprendizado multimodal.
Sobre Geração de Dados Sintéticos
As ferramentas de Geração de Dados Sintéticos são uma classe de aplicações de IA que criam programaticamente dados artificiais que espelham as propriedades estatísticas de dados do mundo real. Essas ferramentas frequentemente utilizam modelos avançados de aprendizado de máquina, como Redes Geradoras Adversariais (GANs), para aprender padrões de um conjunto de dados original e, em seguida, produzir novos pontos de dados inexistentes. O valor principal reside em permitir o treinamento robusto de modelos de IA e testes de software em situações onde os dados reais são escassos, sensíveis ou restringidos por regulamentações de privacidade. Esta abordagem oferece uma maneira escalável e compatível com a privacidade para aumentar conjuntos de dados e explorar casos extremos sem expor informações reais.
Recursos Principais
- Síntese de Tipos de Dados: Gera vários formatos de dados, incluindo dados tabulares, de séries temporais, de imagem e de texto, para atender a necessidades específicas.
- Fidelidade Estatística: Garante que os dados sintéticos mantenham as mesmas distribuições estatísticas, correlações e padrões dos dados originais.
- Preservação da Privacidade: Implementa técnicas como Privacidade Diferencial para garantir que os dados gerados não possam ser rastreados até nenhum indivíduo real.
- Aumento de Dados: Cria variações de pontos de dados existentes para equilibrar conjuntos de dados desbalanceados ou expandir conjuntos de treinamento para melhorar a robustez do modelo.
- Simulação de Cenários: Permite a criação de dados que representam cenários específicos, raros ou hipotéticos que não estão presentes no conjunto de dados original.
Casos de Uso
Essas ferramentas são amplamente utilizadas em setores que lidam com informações sensíveis, como saúde para criar registros de pacientes anônimos para pesquisa, e finanças para modelar padrões de fraude sem usar dados de transações reais. Elas também são essenciais para empresas de tecnologia, particularmente no treinamento de veículos autônomos, simulando condições raras de direção, e para desenvolvedores de software que precisam de dados de usuário realistas para testar aplicações sem comprometer a privacidade.
Como Escolher
Ao selecionar uma ferramenta de Geração de Dados Sintéticos, primeiro considere os tipos de dados que ela suporta (por exemplo, tabular, imagem, texto). Avalie a qualidade e a fidelidade dos dados gerados, verificando as métricas de similaridade estatística. Avalie a força de seus recursos de preservação de privacidade, como o suporte à Privacidade Diferencial. Por fim, considere sua escalabilidade para grandes conjuntos de dados e se oferece uma interface amigável ou requer conhecimento técnico aprofundado por meio de uma API.
Geração de Dados SintéticosCenários de aplicação
Treinando Modelos de IA com Dados Sensíveis à Privacidade
Uma instituição de pesquisa em saúde precisa desenvolver um modelo de aprendizado de máquina para prever surtos de doenças, mas é restringida por leis rigorosas de privacidade do paciente como a HIPAA. Usar dados reais de pacientes não é uma opção. Cientistas de dados usam uma ferramenta de geração de dados sintéticos para analisar a estrutura estatística dos registros confidenciais dos pacientes. A ferramenta então gera um novo conjunto de dados totalmente artificial que imita os padrões, correlações e distribuições dos dados originais sem conter nenhuma informação de saúde pessoal real. Isso permite que os pesquisadores treinem, testem e validem seus modelos preditivos de forma eficaz e segura, acelerando a pesquisa médica e garantindo a total confidencialidade do paciente.
Aumentando Conjuntos de Dados Desbalanceados para Detecção de Fraude
Uma empresa de serviços financeiros está construindo um modelo para detectar transações fraudulentas. O desafio é que os casos fraudulentos são extremamente raros em comparação com os legítimos, criando um conjunto de dados altamente desbalanceado que enviesa o modelo. Um engenheiro de ML emprega uma ferramenta de geração de dados sintéticos para criar exemplos realistas e de alta qualidade de transações fraudulentas. Ao sobreamostrar a classe minoritária (fraude) com esses dados sintéticos, eles criam um conjunto de treinamento balanceado. O modelo resultante torna-se significativamente mais preciso na identificação de padrões raros de fraude, reduzindo perdas financeiras sem aumentar os falsos positivos em transações legítimas.
Simulando Casos Extremos para Treinamento de Veículos Autônomos
Uma empresa automotiva está desenvolvendo o sistema de percepção de um carro autônomo. O sistema precisa ser treinado em inúmeros cenários, especialmente 'casos extremos' raros e perigosos, como um pedestre aparecendo de repente atrás de um ônibus ou condições climáticas extremas. É impraticável e inseguro capturar dados do mundo real suficientes para todas essas situações. Os engenheiros usam uma plataforma de geração de dados sintéticos para criar simulações fotorrealistas desses casos extremos específicos. Isso lhes permite gerar grandes quantidades de dados de treinamento para eventos raros, melhorando drasticamente a confiabilidade e a segurança da IA em situações críticas antes de qualquer implantação no mundo real.
Acelerando Testes de Software e Garantia de Qualidade
Uma equipe de desenvolvimento de software está criando uma nova plataforma de gerenciamento de relacionamento com o cliente (CRM). Para garantir que o software seja robusto, eles precisam testá-lo com um banco de dados grande e diversificado de perfis de usuário, interações e históricos. Criar esses dados manualmente é lento e muitas vezes carece de realismo. A equipe de QA usa uma ferramenta de dados sintéticos para gerar rapidamente milhares de contas de usuário realistas, mas totalmente fictícias, completas com nomes, detalhes de contato e registros de atividades. Isso lhes permite realizar testes de carga abrangentes, caça a bugs e validação de recursos em uma ampla gama de cenários de dados, levando a um lançamento de produto de maior qualidade.
Criando Dados Realistas para Demonstrações de Produtos
Uma empresa de software B2B precisa apresentar sua poderosa plataforma de análise de dados a clientes em potencial. Usar dados reais de clientes em uma demonstração ao vivo é um grande risco de segurança e privacidade. As equipes de marketing e vendas usam um gerador de dados sintéticos para criar um conjunto de dados rico e verossímil que reflete sua indústria-alvo. Este conjunto de dados preenche o ambiente de demonstração com nomes de clientes realistas, números de vendas e métricas de engajamento. Como resultado, eles podem oferecer demonstrações de produtos atraentes e interativas que destacam todas as capacidades da plataforma sem nunca expor informações sensíveis, construindo confiança com clientes em potencial.
Modelando Cenários Futuros para Análise de Risco Financeiro
Uma equipe de gerenciamento de risco em um banco de investimento precisa testar o estresse de seus portfólios contra possíveis quebras de mercado ou eventos econômicos imprevistos. Os dados históricos são limitados e podem não cobrir cenários novos. A equipe usa uma ferramenta de geração de dados sintéticos para criar dados de séries temporais que simulam várias condições de mercado de alto estresse, como inflação rápida ou o estouro repentino de uma bolha de ativos. Ao executar seus modelos de risco com esses dados sintéticos, eles podem entender melhor as vulnerabilidades potenciais em suas estratégias de investimento e desenvolver planos financeiros mais resilientes, melhorando sua preparação para a volatilidade futura do mercado.