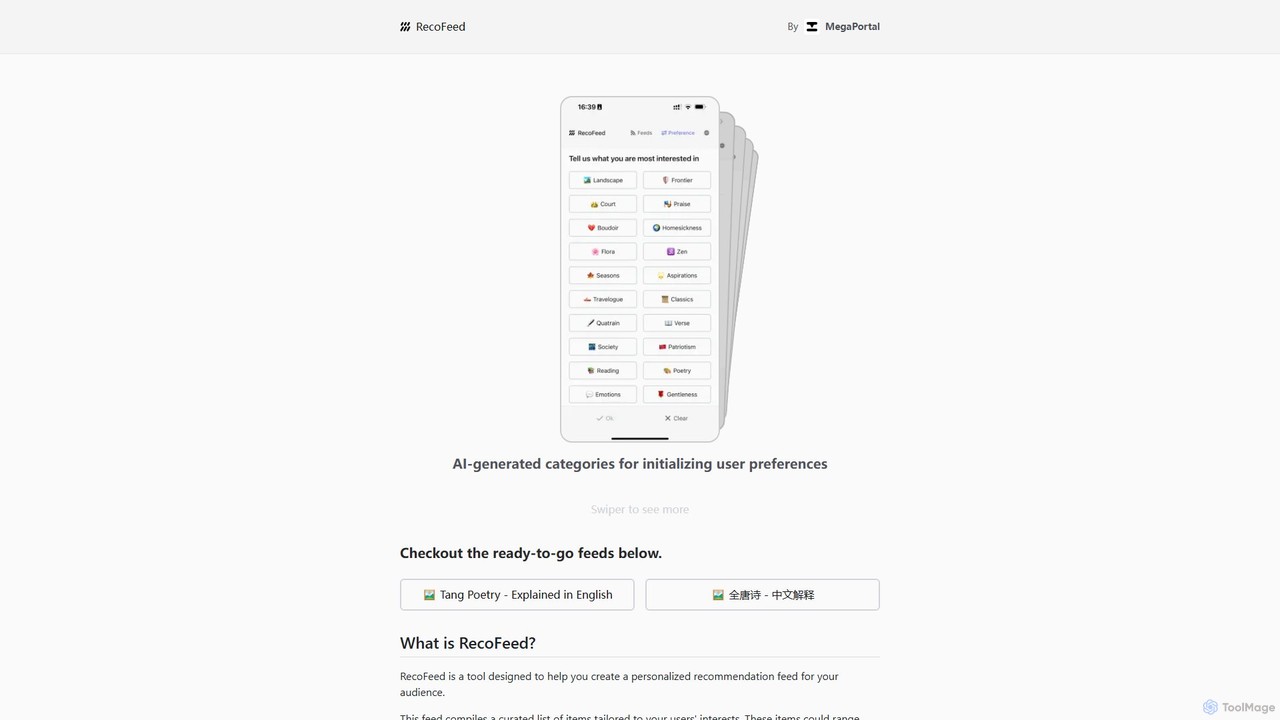
RecoFeed
RecoFeed é uma ferramenta focada em desenvolvedores para criar feeds de recomendação personalizados. Utiliza um banco de dados …
RecoFeed é uma ferramenta focada em desenvolvedores para criar feeds de recomendação personalizados. Utiliza um banco de dados vetorial no dispositivo, o CloseVector, para gerar sugestões em tempo real localmente no dispositivo do usuário, garantindo máxima privacidade de dados e baixa latência. É projetado para aplicativos e sites em vários setores como e-commerce, plataformas de conteúdo e mídias sociais.
Sobre Banco de Dados Vetorial
Um Banco de Dados Vetorial é um sistema de banco de dados especializado projetado para armazenar, gerenciar e pesquisar eficientemente embeddings vetoriais de alta dimensão. Diferente dos bancos de dados tradicionais que indexam dados com base em valores exatos, os bancos de dados vetoriais usam algoritmos de Vizinho Mais Próximo Aproximado (ANN) para encontrar os itens mais similares com base em suas representações vetoriais. Essa capacidade é fundamental para impulsionar aplicações avançadas de IA, como busca semântica, motores de recomendação e geração aumentada por recuperação (RAG) para grandes modelos de linguagem. Eles oferecem velocidade e escalabilidade excepcionais para tarefas de busca por similaridade em conjuntos de dados massivos e não estruturados, como texto, imagens e áudio.
Recursos Principais
- Indexação de Vetores de Alta Dimensão: Organiza eficientemente dados vetoriais usando algoritmos como HNSW ou IVF para recuperação rápida.
- Busca por Similaridade: Realiza buscas com base na proximidade vetorial (por exemplo, similaridade de cosseno, distância euclidiana) para encontrar itens semanticamente semelhantes.
- Escalabilidade e Desempenho: Projetado para lidar com bilhões de vetores e altas cargas de consulta com baixa latência, crucial para aplicações em tempo real.
- Filtragem de Metadados: Combina a busca por similaridade vetorial com a filtragem de metadados tradicional para resultados mais precisos e contextuais.
Casos de Uso
Bancos de dados vetoriais são essenciais para engenheiros de IA/ML, cientistas de dados e desenvolvedores que criam aplicações que exigem a compreensão de relações semânticas nos dados. Eles são amplamente utilizados no comércio eletrônico para busca visual e recomendações, em sistemas empresariais para busca inteligente em bases de conhecimento e em IA generativa para fornecer contexto factual a grandes modelos de linguagem, reduzindo imprecisões.
Como Escolher
Ao selecionar um banco de dados vetorial, avalie seus algoritmos de indexação e benchmarks de desempenho para o seu tipo de dado específico. Considere o modelo de implantação — serviços gerenciados em nuvem oferecem facilidade de uso, enquanto opções auto-hospedadas fornecem mais controle. Verifique também a existência de SDKs robustos em suas linguagens de programação preferidas e integrações com frameworks de IA populares como LangChain ou LlamaIndex. Por fim, avalie sua escalabilidade e modelo de preços para garantir que atenda às suas necessidades de longo prazo.
Banco de Dados VetorialCenários de aplicação
Potencializando Chatbots de IA com Geração Aumentada por Recuperação (RAG)
Um desenvolvedor de IA tem a tarefa de construir um chatbot de suporte ao cliente que deve fornecer respostas precisas a partir de uma base de conhecimento privada, como manuais de produtos e FAQs internos. Para conseguir isso, os documentos são segmentados, convertidos em embeddings vetoriais e armazenados em um banco de dados vetorial. Quando um usuário faz uma pergunta, sua consulta é vetorizada e usada para pesquisar no banco de dados os trechos de documentos mais relevantes. Esses trechos recuperados são então passados para um Grande Modelo de Linguagem (LLM) como contexto, permitindo que o chatbot gere respostas precisas e cientes do contexto com base em dados proprietários e reduza significativamente o risco de alucinações.
Implementando a Busca Semântica para Documentos Internos
Um gestor de conhecimento em uma grande corporação precisa melhorar a forma como os funcionários encontram informações em milhares de relatórios internos e documentos de políticas. A busca tradicional por palavras-chave é ineficiente, muitas vezes falhando em apresentar conteúdo conceitualmente relacionado. Ao implementar um banco de dados vetorial, todos os documentos são vetorizados para capturar seu significado semântico. Os funcionários agora podem pesquisar usando perguntas em linguagem natural. O sistema realiza uma busca por similaridade para recuperar documentos com base na relevância conceitual, não apenas em correspondências de palavras-chave. Isso leva a uma melhoria de 80% na velocidade de recuperação de informações, impulsionando a produtividade e o compartilhamento de conhecimento.
Construindo um Mecanismo de Busca Visual para E-commerce
Um desenvolvedor de e-commerce para uma varejista de moda online quer criar um recurso de 'compre o look', permitindo que os clientes encontrem produtos ao enviar uma imagem. Para habilitar isso, todo o catálogo de imagens de produtos é processado por um modelo de visão para gerar embeddings vetoriais, que são então armazenados em um banco de dados vetorial. Quando um usuário envia uma imagem, ela é convertida de forma semelhante em um vetor. O banco de dados então realiza uma busca de similaridade de alta velocidade para encontrar e exibir as imagens de produtos com os vetores mais próximos. Essa experiência de busca intuitiva melhora significativamente a descoberta de produtos e demonstrou aumentar as taxas de conversão ao ajudar os clientes a encontrar itens visualmente semelhantes instantaneamente.
Criando Sistemas de Recomendação de Conteúdo Personalizado
Um cientista de dados em um serviço de streaming de mídia visa aumentar o engajamento do usuário fornecendo recomendações de conteúdo altamente relevantes. Eles representam cada peça de conteúdo (por exemplo, filmes, artigos) e o perfil de cada usuário como vetores de alta dimensão. Quando um usuário interage com o conteúdo, seu vetor de perfil é atualizado. Um banco de dados vetorial é usado para realizar buscas de similaridade em tempo real, encontrando os vetores de conteúdo mais próximos do vetor de interesse de um usuário. Isso permite que a plataforma entregue recomendações dinâmicas e personalizadas que se adaptam aos gostos em evolução do usuário, resultando em durações de sessão mais longas e maior retenção de usuários.
Detectando Anomalias no Tráfego de Rede de Cibersegurança
Um analista de cibersegurança precisa identificar ameaças potenciais em vastas quantidades de dados de tráfego de rede em tempo real. Dados operacionais normais, como entradas de log e pacotes de rede, são convertidos em embeddings vetoriais para estabelecer um cluster de base de atividade 'normal' no espaço vetorial. Um banco de dados vetorial ingere continuamente novos dados, converte-os em vetores e os compara com essa linha de base. Qualquer ponto de dados cujo vetor se afaste muito do cluster normal é instantaneamente sinalizado como uma anomalia. Essa abordagem permite a detecção rápida de ameaças de dia zero ou falhas de sistema que não correspondem a assinaturas conhecidas, fornecendo uma camada crítica de segurança proativa.
Desduplicação de Conjuntos de Dados de Imagens em Grande Escala
Um engenheiro de aprendizado de máquina está preparando um conjunto de dados massivo de imagens para treinar um modelo de visão computacional. Para garantir a qualidade dos dados e evitar o viés do modelo, é crucial remover imagens duplicadas ou quase duplicadas. Cada imagem no conjunto de dados é convertida em um embedding vetorial e indexada em um banco de dados vetorial. O engenheiro então executa uma busca de similaridade para cada imagem para encontrar outras dentro de um limiar de distância muito pequeno. Este processo identifica e sinaliza eficientemente todos os conjuntos de quase duplicatas para remoção, resultando em um conjunto de dados de treinamento mais limpo e diversificado. Isso melhora a precisão e as capacidades de generalização do modelo final.