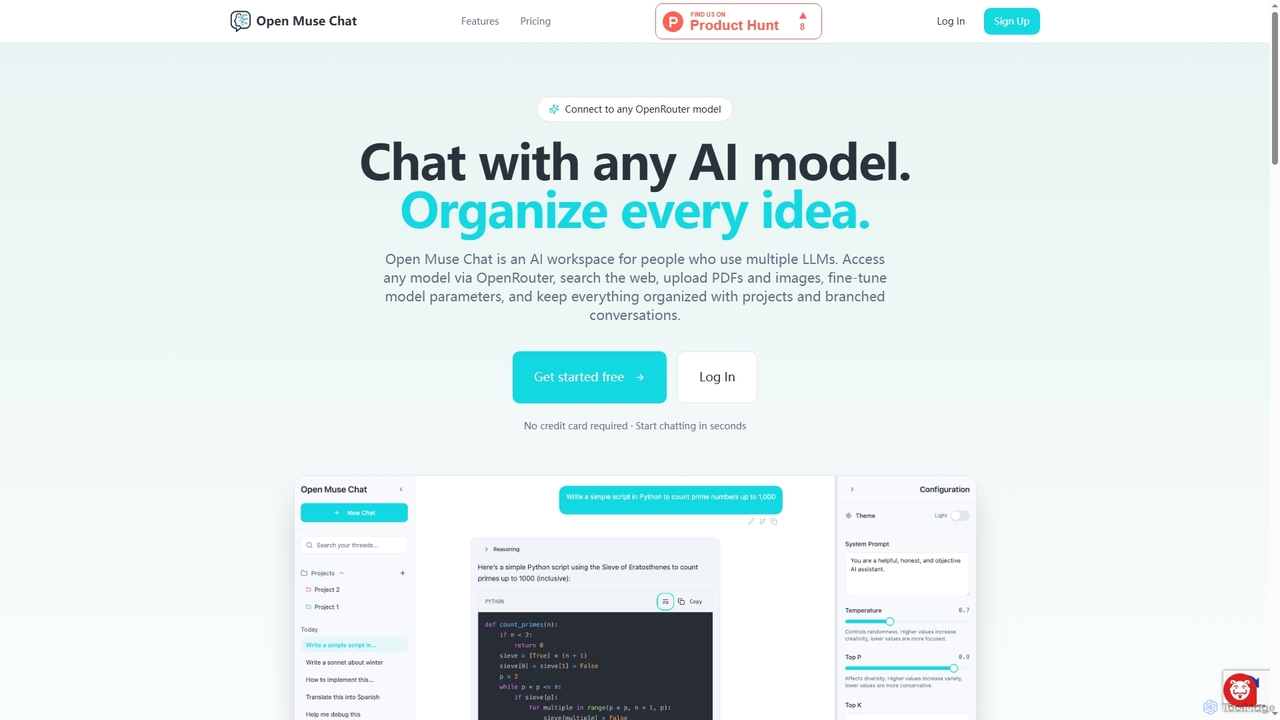
Open Muse Chat
Open Muse Chat é uma interface de chat AI multi-modelo avançada projetada para usuários que utilizam vários grandes …
Open Muse Chat é uma interface de chat AI multi-modelo avançada projetada para usuários que utilizam vários grandes modelos de linguagem (LLMs). Ele se conecta a qualquer modelo OpenRouter, oferece pesquisa na web, upload de arquivos (PDFs, imagens) para contexto e fornece controle granular sobre os parâmetros do modelo, tudo dentro de um espaço de trabalho organizado com projetos e conversas ramificadas.
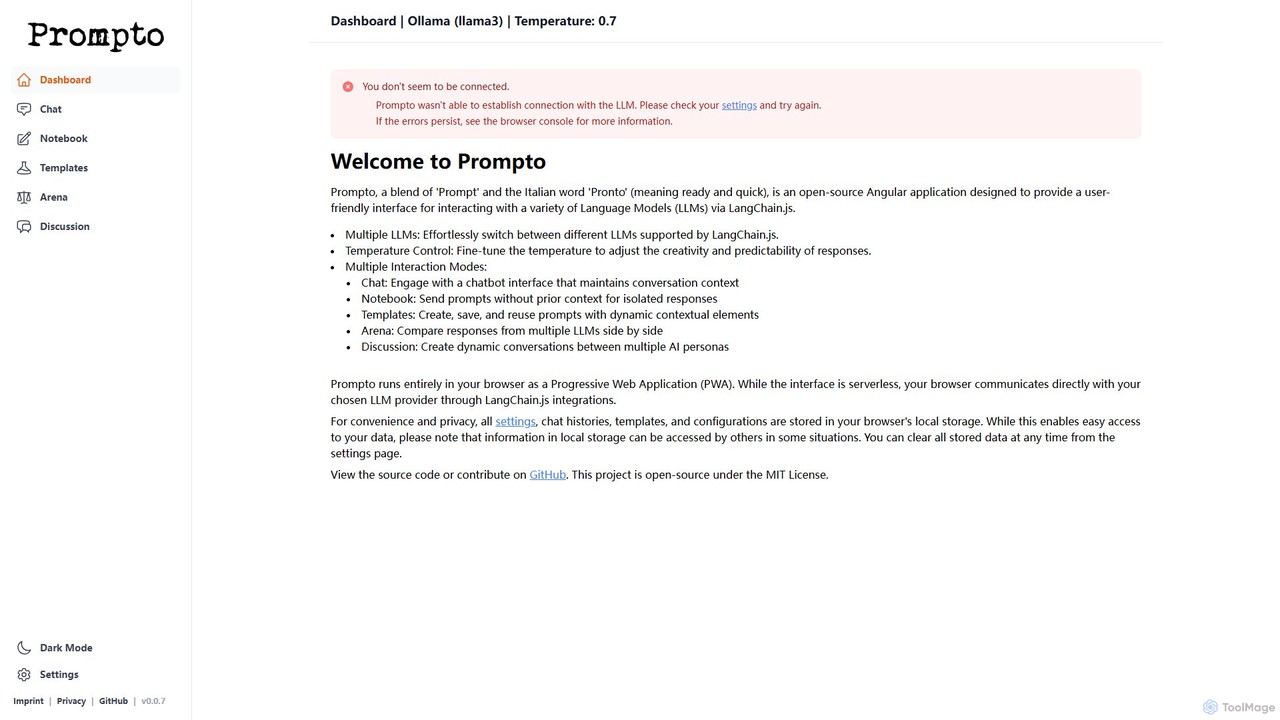
Prompto
Prompto é uma interface gratuita, de código aberto e baseada em navegador para interagir com uma vasta gama …
Prompto é uma interface gratuita, de código aberto e baseada em navegador para interagir com uma vasta gama de Modelos de Linguagem Grandes (LLMs). Ele utiliza o LangChain.js para se conectar diretamente a provedores como OpenAI, Anthropic e modelos locais via Ollama, oferecendo recursos avançados como uma Arena de comparação de modelos, modelos de prompt e discussões multi-IA, tudo isso priorizando a privacidade do usuário ao armazenar os dados localmente.
Sobre Interface LLM
Uma Interface LLM é uma ferramenta de desenvolvedor especializada que atua como um gateway unificado para acessar múltiplos Modelos de Linguagem Grandes (LLMs). Essas ferramentas fornecem uma API única e consistente, permitindo que os desenvolvedores interajam com diferentes modelos como GPT, Claude ou Llama sem escrever código específico do provedor. Essa camada de abstração simplifica o desenvolvimento, otimiza os custos e aumenta a resiliência da aplicação, permitindo a troca de modelos e fallbacks de forma transparente. Para desenvolvedores que constroem aplicações baseadas em IA, uma Interface LLM é um componente crucial para gerenciar a complexidade e melhorar a eficiência operacional.
Recursos Principais
- API Unificada: Conecte-se a vários LLMs de diferentes provedores através de um único endpoint de API padronizado.
- Roteamento de Modelos e Fallbacks: Direcione automaticamente as solicitações para o modelo mais adequado com base no custo ou desempenho, com mecanismos de fallback integrados.
- Rastreamento de Custo e Uso: Monitore despesas de API, uso de tokens e latência em todos os modelos conectados em um painel centralizado.
- Gerenciamento de Prompts: Crie, teste, versione e implante modelos de prompts centralmente para um comportamento consistente da aplicação.
- Cache de Requisições: Armazene e reutilize respostas para requisições idênticas para reduzir a latência e diminuir os custos de API.
Casos de Uso
As Interfaces LLM são usadas principalmente por desenvolvedores de software, engenheiros de IA e equipes de produto que constroem aplicações que exigem flexibilidade e confiabilidade. Elas são ideais para criar chatbots de múltiplos provedores, plataformas de geração de conteúdo que aproveitam os pontos fortes de diferentes modelos, ou agentes de IA complexos que precisam selecionar dinamicamente a melhor ferramenta para uma tarefa. As empresas também as utilizam para padronizar e governar o acesso a LLMs em toda a organização.
Como Escolher
Ao selecionar uma Interface LLM, considere o seguinte: Primeiro, avalie a lista de LLMs suportados e a velocidade com que novos modelos são integrados. Segundo, avalie as métricas de desempenho, como a sobrecarga de latência e as garantias de confiabilidade. Terceiro, examine os recursos de observabilidade, como a qualidade do registro, os painéis de rastreamento de custos e as análises. Por fim, revise a experiência do desenvolvedor, incluindo a qualidade da documentação e a disponibilidade de SDKs para suas linguagens de programação preferidas.
Interface LLMCenários de aplicação
Construindo um Chatbot de IA Resiliente com Fallbacks de Modelo
Um líder técnico de atendimento ao cliente precisa garantir que seu chatbot de suporte mantenha um alto tempo de atividade. Usando uma Interface LLM, eles configuram um modelo principal como o GPT-4 para respostas de alta qualidade e um modelo secundário e econômico como o Claude 3 Sonnet como fallback. Se a API do modelo principal sofrer uma interrupção ou alta latência, a interface redireciona automaticamente todas as solicitações recebidas para o modelo de fallback. Isso garante que o chatbot permaneça operacional e responsivo aos usuários, evitando a interrupção do serviço sem exigir intervenção manual da equipe de engenharia.
Teste A/B de Prompts para um Gerador de Textos de Marketing
Um tecnólogo de marketing visa encontrar o prompt mais eficaz para gerar títulos de anúncios. Usando o sistema de gerenciamento de prompts da Interface LLM, eles criam duas variações de um prompt ('Prompt A' e 'Prompt B'). A interface é configurada para rotear 50% das solicitações de geração para cada versão do prompt. O painel de análise integrado rastreia métricas-chave como taxas de cliques e engajamento do usuário para os títulos gerados por cada prompt. Após analisar os dados, a equipe pode implantar com confiança o prompt vencedor para 100% do tráfego com um único clique, otimizando o desempenho de sua campanha.
Otimizando Custos de API para um Serviço de Resumo de Conteúdo
A ferramenta de resumo de uma startup precisa gerenciar os custos da API LLM de forma eficaz. Eles usam uma Interface LLM para implementar o roteamento inteligente. Solicitações simples, como resumir um parágrafo curto, são enviadas para um modelo rápido e de baixo custo. Tarefas mais complexas, como resumir um documento de 20 páginas, são roteadas para um modelo poderoso e de alta capacidade. O painel de acompanhamento de custos da interface fornece uma visão em tempo real dos gastos por modelo, permitindo que a equipe ajuste suas regras de roteamento e estratégia de cache para permanecer dentro do orçamento, mantendo uma saída de alta qualidade para todos os usuários.
Padronizando o Acesso a LLMs em uma Grande Empresa
Um arquiteto de TI corporativo precisa fornecer aos desenvolvedores acesso seguro e governado a vários LLMs. Eles implantam uma Interface LLM central como um gateway. Isso permite que eles gerenciem todas as chaves de API em um cofre seguro, definam limites de gastos e cotas de uso para diferentes equipes e apliquem políticas de privacidade de dados. A interface registra cada solicitação, fornecendo uma trilha de auditoria completa para fins de conformidade. Essa abordagem centralizada capacita as equipes de desenvolvimento a inovar com diferentes modelos, garantindo que a organização mantenha o controle sobre segurança, custos e governança.
Prototipagem Rápida de um Recurso Alimentado por IA
Uma equipe de produto está construindo rapidamente um protótipo para um novo recurso de IA. Em vez de escrever integrações separadas para OpenAI, Anthropic e Google, eles usam um único SDK de Interface LLM. Isso permite que eles alternem entre GPT-4, Claude e Gemini alterando apenas uma linha de código de configuração. Eles podem testar rapidamente qual modelo oferece a melhor qualidade, velocidade e custo-benefício para seu caso de uso específico. Isso acelera drasticamente a fase de prototipagem, permitindo que validem sua ideia e passem para a produção muito mais rápido.
Cache de Respostas para um Sistema de P&R de Alto Tráfego
Um desenvolvedor está construindo um bot de FAQ para um site de e-commerce popular que recebe muitas perguntas repetitivas. Eles ativam o recurso de cache em sua Interface LLM. Quando uma pergunta como 'Qual é a sua política de devolução?' é feita pela primeira vez, o LLM gera uma resposta e a interface armazena esse par de pergunta-resposta em um cache. Para todas as perguntas idênticas subsequentes, a resposta é servida diretamente do cache em milissegundos. Essa estratégia reduz significativamente as chamadas de API para o provedor de LLM, diminuindo os custos em mais de 70% e fornecendo respostas quase instantâneas aos usuários para consultas comuns.