Kubiks
Kubiks é uma plataforma de observabilidade full-stack alimentada por IA que oferece rastreamento distribuído, registro e painéis personalizados. …
Kubiks é uma plataforma de observabilidade full-stack alimentada por IA que oferece rastreamento distribuído, registro e painéis personalizados. Ela detecta automaticamente problemas, identifica causas-raiz e gera pull requests com correções, ajudando equipes de engenharia a depurar mais rápido e resolver problemas proativamente.
Sobre Engenharia de Confiabilidade de Sites
Site Reliability Engineering (SRE) é uma disciplina que aplica princípios de engenharia de software a problemas de infraestrutura e operações, visando criar sistemas altamente confiáveis e escaláveis. Ela utiliza automação, tomada de decisões baseada em dados e um foco em objetivos de nível de serviço (SLOs) para garantir a estabilidade e o desempenho de serviços críticos. Como um componente central dentro da categoria mais ampla de Operações, as ferramentas SRE capacitam as equipes a gerenciar proativamente a saúde do sistema, responder eficientemente a incidentes e melhorar continuamente a confiabilidade do serviço.
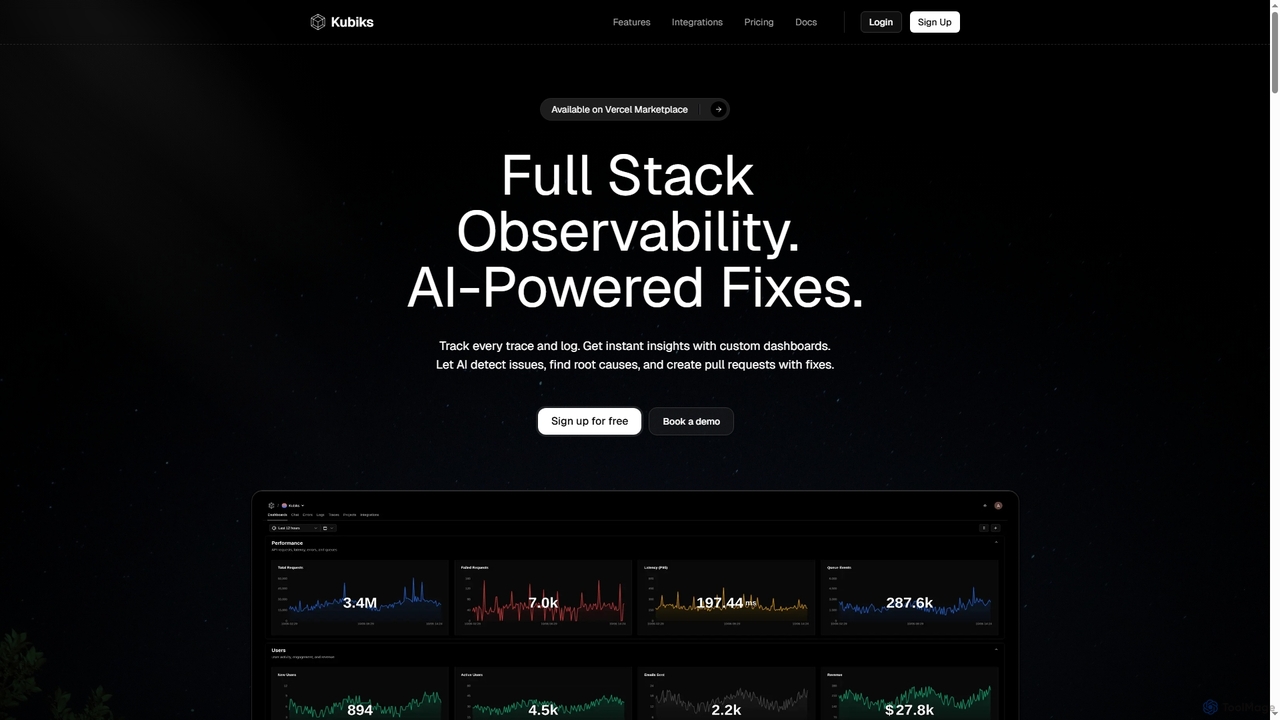
Principais Recursos
- Monitoramento de SLO/SLA: Acompanha e relata objetivos e acordos de nível de serviço para garantir que as metas de desempenho sejam atingidas.
- Gerenciamento e Automação de Incidentes: Otimiza os processos de detecção, alerta, resposta e resolução de incidentes por meio de fluxos de trabalho automatizados.
- Gerenciamento de Orçamento de Erros: Define e rastreia níveis aceitáveis de falta de confiabilidade, orientando as prioridades de desenvolvimento e operação.
- Observabilidade e Monitoramento: Fornece insights abrangentes sobre o comportamento do sistema por meio de logs, métricas e rastreamentos para identificação proativa de problemas.
- Planejamento de Capacidade: Preveja as necessidades de recursos e otimiza a infraestrutura para lidar com cargas antecipadas e prevenir interrupções.
Cenários Aplicáveis
As ferramentas SRE são essenciais para organizações que executam sistemas complexos e distribuídos, como grandes plataformas de e-commerce, provedores de SaaS e serviços financeiros. Elas permitem que equipes SRE, engenheiros de DevOps e engenheiros de plataforma mantenham alta disponibilidade, gerenciem a confiabilidade de microsserviços e automatizem tarefas operacionais críticas, garantindo experiências de usuário contínuas e continuidade dos negócios.
Como Escolher
Ao selecionar ferramentas SRE, priorize soluções que ofereçam recursos robustos de observabilidade, integração perfeita com pipelines de CI/CD e plataformas de nuvem existentes, e capacidades abrangentes de gerenciamento de incidentes. Considere a escalabilidade da ferramenta, os recursos de relatórios para conformidade com SLO e sua capacidade de suportar o rastreamento do orçamento de erros. A facilidade de uso e o suporte da comunidade também são cruciais para uma adoção eficaz pela equipe.
Engenharia de Confiabilidade de SitesCenários de aplicação
Automatizando Fluxos de Trabalho de Resposta a Incidentes
Para engenheiros de plantão e equipes SRE, as ferramentas SRE alimentadas por IA automatizam a detecção de anomalias e incidentes críticos em sistemas distribuídos. Elas podem acionar alertas, iniciar scripts de diagnóstico e até mesmo sugerir etapas de remediação com base em dados históricos, reduzindo significativamente o tempo médio para resolução (MTTR) e minimizando a interrupção do serviço durante interrupções críticas.
Monitoramento e Aplicação de Objetivos de Nível de Serviço (SLOs)
As equipes SRE utilizam essas ferramentas para definir, monitorar e aplicar os Objetivos de Nível de Serviço (SLOs) para serviços críticos. As ferramentas coletam e analisam continuamente métricas (por exemplo, latência, taxa de erro, disponibilidade), fornecendo painéis em tempo real e alertas quando os SLOs estão em risco, permitindo que as equipes abordem proativamente a degradação do desempenho antes que ela afete os usuários.
Planejamento Proativo de Capacidade e Otimização de Recursos
Arquitetos de infraestrutura e SREs utilizam ferramentas SRE para planejamento de capacidade baseado em dados. Ao analisar padrões de uso históricos e prever a demanda futura, essas ferramentas ajudam a otimizar a alocação de recursos, prevenir gargalos e garantir que os sistemas possam escalar eficientemente para atender a picos de tráfego, evitando assim o provisionamento excessivo caro ou interrupções de serviço devido ao subprovisionamento.
Conduzindo Análises Post-Mortem Sem Culpa
Após um incidente, as ferramentas SRE facilitam a análise post-mortem abrangente, agregando logs, métricas e rastreamentos de várias fontes. Isso permite que as equipes SRE e de desenvolvimento identifiquem as causas raiz, compreendam os fatores contribuintes e documentem as lições aprendidas sem atribuir culpa, promovendo uma cultura de melhoria contínua e prevenindo a recorrência de problemas semelhantes.
Implementando e Gerenciando Orçamentos de Erros
Proprietários de produtos e SREs usam essas ferramentas para implementar e gerenciar orçamentos de erros, que quantificam a quantidade aceitável de falta de confiabilidade para um serviço. As ferramentas rastreiam o consumo do orçamento de erros em tempo real, fornecendo sinais claros às equipes de produto e engenharia sobre quando priorizar o trabalho de confiabilidade em detrimento do desenvolvimento de novos recursos, equilibrando inovação com estabilidade.
Aprimorando a Observabilidade em Sistemas Distribuídos Complexos
Engenheiros de plataforma e SREs implementam essas ferramentas para obter profunda observabilidade em arquiteturas de microsserviços e aplicações nativas da nuvem. Ao correlacionar métricas, logs e rastreamentos em centenas ou milhares de serviços, as ferramentas fornecem uma visão unificada da saúde do sistema, permitindo depuração rápida, ajuste de desempenho e uma compreensão holística do comportamento do sistema.