Wirestock
Wirestock là một thị trường kết nối freelancer sáng tạo với các công ty AI, cho phép người …
Wirestock là một thị trường kết nối freelancer sáng tạo với các công ty AI, cho phép người sáng tạo kiếm tiền bằng cách đóng góp hình ảnh, video và minh họa chất lượng cao cho các bộ dữ liệu huấn luyện AI.
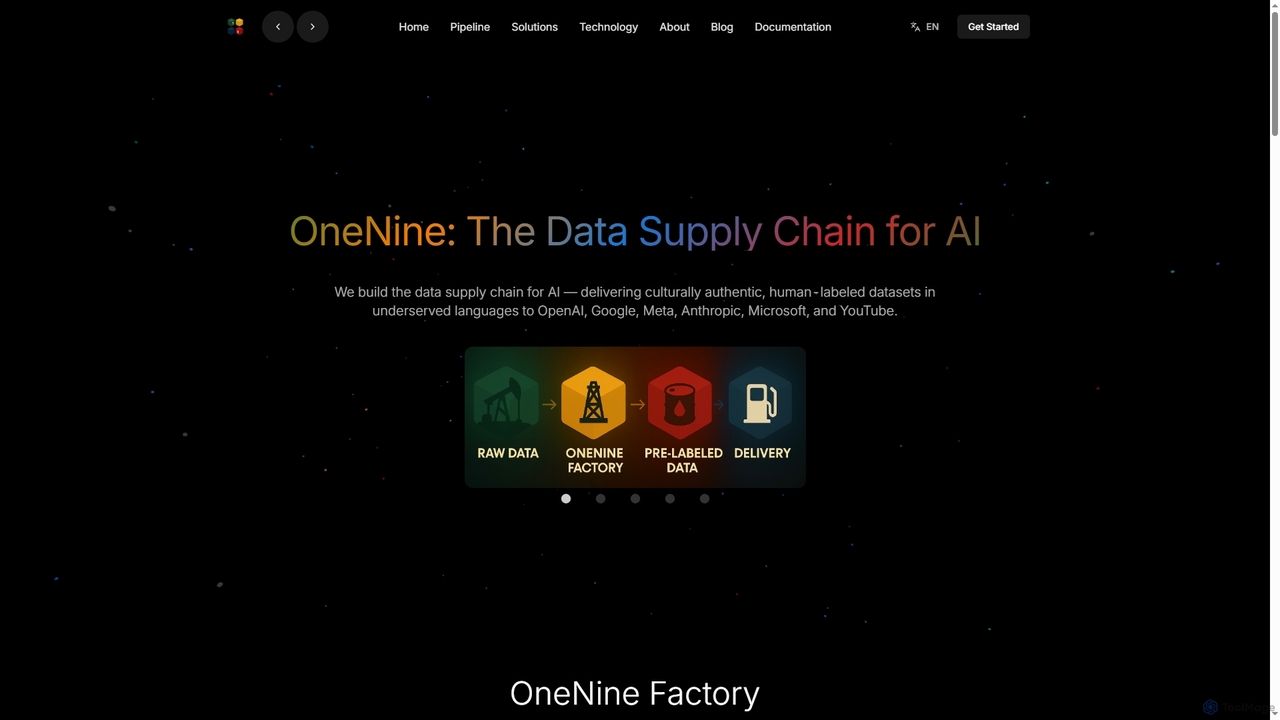
OneNine
OneNine là chuỗi cung ứng dữ liệu cho AI, chuyên cung cấp các bộ dữ liệu được gắn …
OneNine là chuỗi cung ứng dữ liệu cho AI, chuyên cung cấp các bộ dữ liệu được gắn nhãn thủ công, mang tính văn hóa đích thực và chất lượng cao bằng các ngôn ngữ ít tài nguyên cho các công ty AI hàng đầu. Nó thu hẹp khoảng cách ngôn ngữ, cho phép các mô hình AI toàn diện và chính xác hơn trên toàn cầu.

Sapien
Sapien là một xưởng đúc dữ liệu phi tập trung cung cấp dữ liệu huấn luyện AI cấp …
Sapien là một xưởng đúc dữ liệu phi tập trung cung cấp dữ liệu huấn luyện AI cấp doanh nghiệp. Nền tảng này tận dụng mạng lưới cộng tác viên toàn cầu để cung cấp dữ liệu chuyên biệt, chất lượng cao cho các hệ thống AI phức tạp, bao gồm chú thích 3D/4D, suy luận chuyên gia và thu thập dữ liệu quy mô lớn.
Về Dữ liệu huấn luyện
Công cụ Dữ liệu huấn luyện là các nền tảng và dịch vụ được thiết kế để tạo, quản lý và cung cấp các bộ dữ liệu chất lượng cao cho các mô hình học máy. Những công cụ này hợp lý hóa quy trình chuẩn bị dữ liệu quan trọng, cung cấp các chức năng chú thích dữ liệu, tạo dữ liệu tổng hợp và đảm bảo chất lượng. Giá trị chính của chúng nằm ở việc đẩy nhanh quá trình phát triển các hệ thống AI chính xác và mạnh mẽ, vì hiệu suất của bất kỳ mô hình nào cũng phụ thuộc cơ bản vào chất lượng dữ liệu huấn luyện của nó. Là một thành phần quan trọng trong vòng đời Phát triển AI, chúng tạo thành nền tảng để xây dựng các mô hình hiệu quả.
Tính năng Cốt lõi
- Chú thích & Gán nhãn Dữ liệu: Cung cấp giao diện và công cụ tự động để gắn thẻ chính xác các loại dữ liệu khác nhau, chẳng hạn như hình ảnh, văn bản và âm thanh, để tạo ra sự thật nền tảng cho các mô hình.
- Tạo Dữ liệu Tổng hợp: Tạo ra dữ liệu nhân tạo nhưng thực tế để tăng cường các bộ dữ liệu hạn chế, bao quát các trường hợp đặc biệt hoặc bảo vệ thông tin nhạy cảm.
- Quản lý & Phiên bản Dữ liệu: Cung cấp một nền tảng tập trung để lưu trữ, theo dõi và quản lý các phiên bản khác nhau của bộ dữ liệu, đảm bảo khả năng tái tạo thử nghiệm.
- Quy trình Đảm bảo Chất lượng: Bao gồm các tính năng để xem xét, đồng thuận và phát hiện lỗi nhằm duy trì các tiêu chuẩn cao về độ chính xác và nhất quán của dữ liệu.
- Tìm nguồn cung cấp Dữ liệu: Cung cấp quyền truy cập vào các bộ dữ liệu được gán nhãn sẵn, có sẵn hoặc các dịch vụ để thu thập và chuẩn bị dữ liệu tùy chỉnh.
Trường hợp Sử dụng
Những công cụ này rất cần thiết trong các ngành sử dụng nhiều dữ liệu như xe tự hành để phát hiện vật thể, y tế để phân tích hình ảnh y khoa và bán lẻ để phân loại sản phẩm. Các kỹ sư học máy, nhà khoa học dữ liệu và nhà nghiên cứu AI sử dụng chúng hàng ngày để xây dựng và tinh chỉnh các bộ dữ liệu cho các tác vụ từ xử lý ngôn ngữ tự nhiên đến thị giác máy tính.
Cách Lựa chọn
Khi chọn một công cụ Dữ liệu huấn luyện, hãy xem xét khả năng hỗ trợ các loại dữ liệu cụ thể của bạn (ví dụ: video, đám mây điểm 3D). Đánh giá các cơ chế kiểm soát chất lượng, chẳng hạn như vai trò của người đánh giá và điểm đồng thuận. Đánh giá khả năng mở rộng của nó cho các dự án quy mô lớn và khả năng tích hợp với quy trình MLOps và lưu trữ đám mây hiện có của bạn. Cuối cùng, hãy xác minh các giao thức bảo mật và sự tuân thủ các quy định về quyền riêng tư dữ liệu như GDPR hoặc HIPAA.
Dữ liệu huấn luyệnTrường hợp sử dụng
Huấn luyện Mô hình Nhận thức cho Xe tự hành
Một công ty công nghệ ô tô phát triển xe tự lái cần huấn luyện các mô hình thị giác máy tính của mình để nhận dạng chính xác người đi bộ, phương tiện, biển báo giao thông và vạch kẻ đường. Sử dụng nền tảng chú thích dữ liệu, một nhóm người gán nhãn thực hiện phân đoạn ngữ nghĩa và chú thích hộp giới hạn trên hàng triệu hình ảnh và khung hình video được ghi lại từ các cuộc thử nghiệm trên đường. Các tính năng kiểm soát chất lượng của nền tảng, chẳng hạn như tính điểm đồng thuận và quy trình làm việc của người đánh giá, đảm bảo độ chính xác cao. Bộ dữ liệu được gán nhãn tỉ mỉ này rất quan trọng để huấn luyện các mô hình nhận thức có thể điều hướng an toàn trong môi trường đô thị phức tạp.
Phát triển AI Chẩn đoán Hình ảnh Y tế
Một viện nghiên cứu y tế đặt mục tiêu xây dựng một mô hình AI để phát hiện các khối u giai đoạn đầu trong ảnh chụp MRI. Do sự khan hiếm của các bác sĩ X-quang chuyên gia và chi phí chú thích thủ công cao, họ sử dụng một công cụ chú thích hình ảnh y tế chuyên dụng. Công cụ này cung cấp các tính năng như hỗ trợ DICOM và phân đoạn bán tự động, giúp tăng tốc quá trình. Để bảo vệ quyền riêng tư của bệnh nhân, tất cả dữ liệu đều được ẩn danh trong nền tảng. Bộ dữ liệu được gán nhãn chất lượng cao thu được cho phép nhóm khoa học dữ liệu huấn luyện một mô hình có thể hỗ trợ các bác sĩ X-quang bằng cách làm nổi bật các khu vực có khả năng đáng lo ngại, dẫn đến chẩn đoán sớm hơn và chính xác hơn.
Tạo Dữ liệu Tổng hợp để Phát hiện Gian lận
Một công ty dịch vụ tài chính muốn cải thiện mô hình phát hiện gian lận của mình nhưng bị hạn chế bởi số lượng ít các ví dụ gian lận thực tế và các quy định nghiêm ngặt về quyền riêng tư dữ liệu. Họ sử dụng một công cụ tạo dữ liệu tổng hợp để tạo ra một bộ dữ liệu giao dịch tài chính lớn và cân bằng. Công cụ này mô hình hóa các thuộc tính thống kê của dữ liệu thực tế của họ để tạo ra các bản ghi giao dịch thực tế nhưng hoàn toàn nhân tạo, bao gồm cả các kịch bản gian lận phức tạp hiếm gặp trong thế giới thực. Điều này cho phép họ huấn luyện một mô hình mạnh mẽ hơn mà không cần sử dụng dữ liệu khách hàng nhạy cảm, cải thiện tỷ lệ phát hiện trong khi vẫn duy trì tuân thủ đầy đủ.
Cải thiện Phân loại Sản phẩm Thương mại điện tử
Một gã khổng lồ bán lẻ trực tuyến quản lý hàng triệu sản phẩm, và việc phân loại các mặt hàng mới theo cách thủ công rất chậm và dễ xảy ra lỗi. Họ sử dụng một dịch vụ gán nhãn dữ liệu để phân loại một bộ dữ liệu lớn gồm hình ảnh và mô tả sản phẩm. Dịch vụ này sử dụng sự kết hợp giữa người chú thích và công nghệ gán nhãn trước do AI hỗ trợ để phân loại sản phẩm một cách hiệu quả vào một hệ thống phân loại chi tiết. Dữ liệu được gán nhãn này sau đó được sử dụng để huấn luyện một mô hình học máy tự động gán danh mục cho các sản phẩm mới được tải lên trang web, giúp giảm đáng kể công sức thủ công, cải thiện mức độ liên quan của tìm kiếm và nâng cao trải nghiệm mua sắm của khách hàng.
Quản lý Bộ dữ liệu để Đảm bảo Tính tái tạo của Mô hình NLP
Một phòng thí nghiệm nghiên cứu AI đang phát triển một mô hình ngôn ngữ mới và cần chạy hàng trăm thí nghiệm với các phiên bản khác nhau của kho văn bản của họ. Để đảm bảo kết quả của họ có thể tái tạo, họ sử dụng một nền tảng quản lý và phiên bản dữ liệu. Công cụ này cho phép họ theo dõi mọi thay đổi đối với bộ dữ liệu, liên kết các phiên bản bộ dữ liệu cụ thể với các lần chạy huấn luyện mô hình và dễ dàng hoàn nguyên về các trạng thái trước đó. Nó hoạt động giống như 'Git cho dữ liệu', cung cấp một dấu vết kiểm tra rõ ràng và ngăn ngừa sự nhầm lẫn. Cách tiếp cận có hệ thống này rất quan trọng cho nghiên cứu hợp tác và để công bố các phát hiện khoa học có thể kiểm chứng.
Kiểm tra Thiên vị trong Bộ dữ liệu cho Thuật toán Tuyển dụng
Một công ty công nghệ nhân sự đang xây dựng một công cụ AI để giúp sàng lọc hồ sơ. Để ngăn chặn việc duy trì các thành kiến lịch sử, họ sử dụng một công cụ đảm bảo chất lượng dữ liệu để kiểm tra bộ dữ liệu huấn luyện của mình. Công cụ này phân tích sự phân bổ của dữ liệu nhân khẩu học (ví dụ: giới tính, dân tộc) và xác định các sự mất cân bằng hoặc tương quan tiềm ẩn có thể dẫn đến kết quả không công bằng. Nó cung cấp các hình ảnh trực quan và báo cáo thống kê giúp nhóm khoa học dữ liệu xác định và giảm thiểu thiên vị trước khi huấn luyện mô hình. Bước chủ động này là cần thiết để phát triển các hệ thống AI có trách nhiệm và đạo đức nhằm thúc đẩy các hoạt động tuyển dụng công bằng.