Edgee
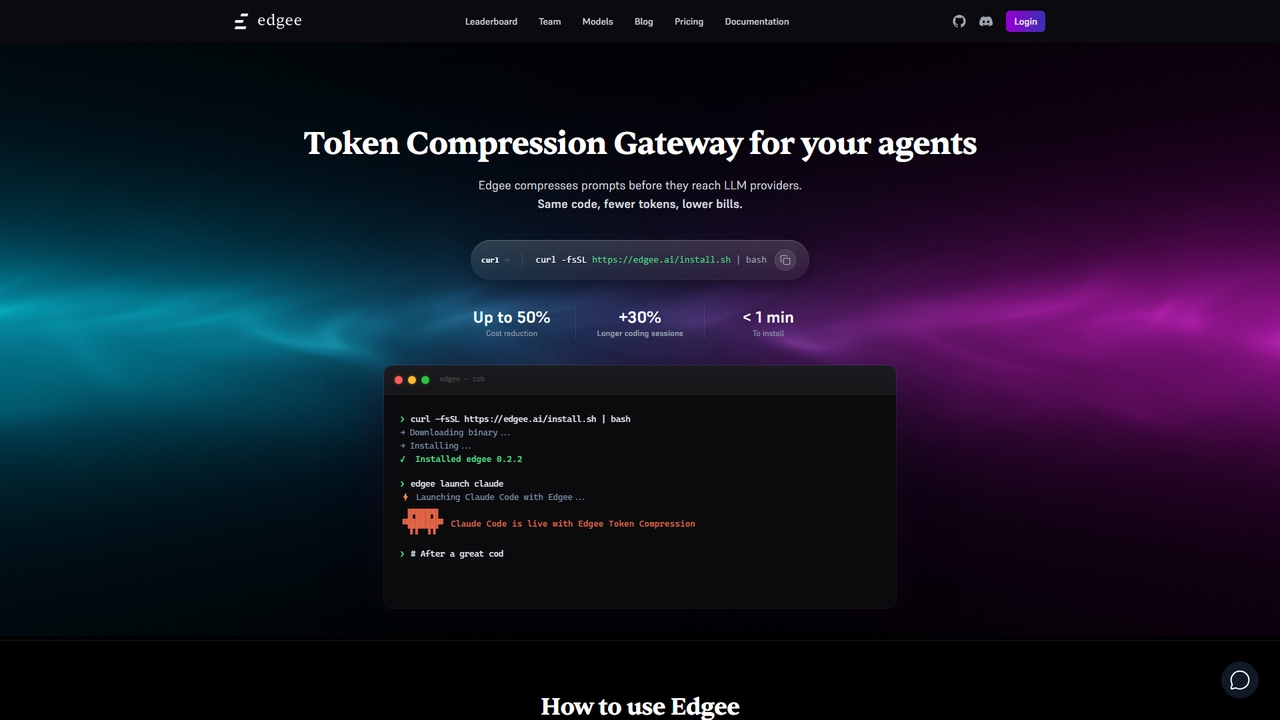
Edgee là một cổng nén token giúp giảm chi phí prompt LLM lên đến 50%. Hoạt động minh …
Edgee là một cổng nén token giúp giảm chi phí prompt LLM lên đến 50%. Hoạt động minh bạch với các tác nhân lập trình như Claude, Codex và Cursor.
APIPark
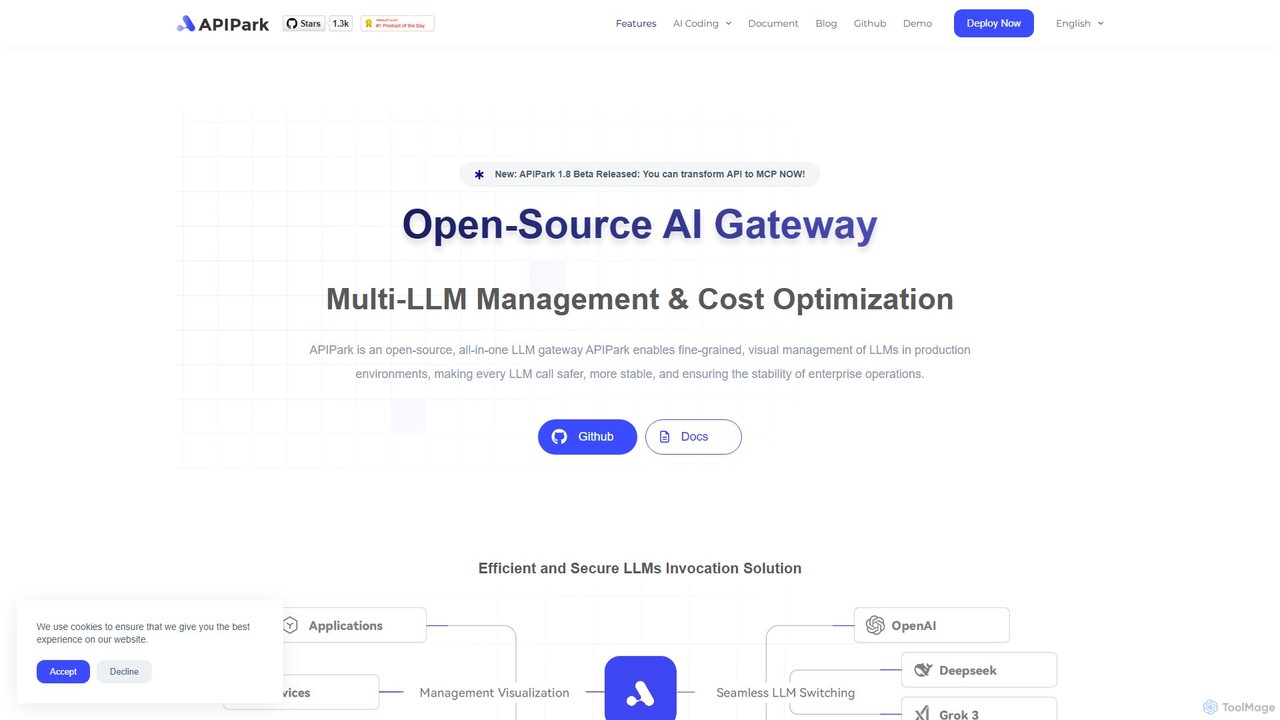
APIPark là một cổng AI mã nguồn mở và cổng thông tin dành cho nhà phát triển được …
APIPark là một cổng AI mã nguồn mở và cổng thông tin dành cho nhà phát triển được thiết kế để giúp các doanh nghiệp quản lý, tích hợp và triển khai các dịch vụ AI một cách hiệu quả. Nó tập trung hóa các lệnh gọi LLM, giảm chi phí và cung cấp các công cụ để chia sẻ, giám sát và bảo mật API.
Về Cổng LLM
Cổng LLM (LLM Gateway) là các công cụ phần mềm trung gian chuyên dụng giúp quản lý và hợp lý hóa quyền truy cập vào nhiều Mô hình Ngôn ngữ Lớn (LLM). Chúng hoạt động như một lớp API hợp nhất, nằm giữa các ứng dụng và nhiều nhà cung cấp LLM khác nhau như OpenAI, Anthropic hoặc Google. Việc kiểm soát tập trung này cho phép các nhà phát triển định tuyến yêu cầu, quản lý khóa API và giám sát việc sử dụng mà không bị ràng buộc vào một hệ sinh thái mô hình duy nhất. Là một phần quan trọng của Cơ sở hạ tầng AI, Cổng LLM rất cần thiết để xây dựng các ứng dụng do AI cung cấp có khả năng mở rộng, tiết kiệm chi phí và linh hoạt.
Tính năng Cốt lõi
- Điểm cuối API Hợp nhất: Truy cập các LLM đa dạng từ nhiều nhà cung cấp thông qua một giao diện duy nhất, nhất quán.
- Định tuyến Thông minh & Chuyển đổi dự phòng: Tự động chuyển hướng yêu cầu đến mô hình tối ưu dựa trên chi phí, độ trễ hoặc tính khả dụng, với khả năng chuyển đổi dự phòng liền mạch.
- Quản lý & Kiểm soát Chi phí: Theo dõi việc sử dụng token theo thời gian thực, đặt ngân sách và thực thi giới hạn tốc độ để ngăn chặn các chi phí không mong muốn.
- Bộ nhớ đệm Hiệu suất: Lưu trữ và tái sử dụng các phản hồi cho các truy vấn thường xuyên để giảm độ trễ và giảm thiểu các lệnh gọi API dư thừa.
- Khả năng Quan sát Tập trung: Hợp nhất nhật ký, số liệu và dấu vết từ tất cả các tương tác LLM để đơn giản hóa việc giám sát và gỡ lỗi.
Trường hợp Sử dụng
Cổng LLM được sử dụng rộng rãi bởi các công ty công nghệ xây dựng sản phẩm AI-native, các doanh nghiệp tích hợp AI tạo sinh vào quy trình làm việc hiện có và các nhóm phát triển yêu cầu sự linh hoạt của mô hình. Chúng đặc biệt có giá trị trong môi trường sản xuất để quản lý các chiến lược đa đám mây hoặc đa mô hình, tối ưu hóa chi phí vận hành và đảm bảo độ tin cậy của ứng dụng.
Cách Lựa chọn
Khi chọn một Cổng LLM, hãy xem xét phạm vi các nhà cung cấp LLM được hỗ trợ, các tùy chọn triển khai (đám mây so với tự lưu trữ), sự tinh vi của các quy tắc định tuyến và bộ nhớ đệm, và khả năng tích hợp của nó với ngăn xếp khả năng quan sát hiện có của bạn (ví dụ: công cụ ghi nhật ký và giám sát). Ngoài ra, hãy đánh giá các tính năng bảo mật và độ trễ mà cổng gây ra.
Cổng LLMTrường hợp sử dụng
Tích hợp AI Đa mô hình cho Doanh nghiệp
Một nhóm phát triển doanh nghiệp cần tích hợp các tính năng AI tạo sinh vào nhiều ứng dụng nội bộ, chẳng hạn như CRM và cơ sở kiến thức. Thay vì xây dựng các tích hợp riêng biệt cho mỗi nhà cung cấp LLM, họ triển khai một Cổng LLM. Điều này cung cấp một điểm cuối duy nhất, an toàn cho tất cả các ứng dụng. Cổng được cấu hình để định tuyến các truy vấn dữ liệu nhạy cảm đến một mô hình riêng, tự lưu trữ, trong khi các tác vụ tạo nội dung chung được gửi đến mô hình thương mại hiệu quả nhất về chi phí. Cách tiếp cận này đơn giản hóa việc bảo trì, thực thi các chính sách bảo mật một cách tập trung và tránh bị khóa nhà cung cấp.
Kiểm soát Chi phí cho Ứng dụng SaaS
Một công ty SaaS cung cấp tính năng tóm tắt nội dung do AI cung cấp cho khách hàng của mình ở các mức giá khác nhau. Để quản lý chi phí vận hành, họ sử dụng một Cổng LLM. Cổng này thực thi các giới hạn token hàng tháng nghiêm ngặt cho mỗi khách hàng dựa trên gói đăng ký của họ. Nó cũng cung cấp các phân tích chi tiết về các mẫu sử dụng, giúp nhóm sản phẩm hiểu chi phí cho mỗi tính năng và điều chỉnh giá cả. Hơn nữa, họ cấu hình một quy tắc để định tuyến các yêu cầu từ người dùng gói miễn phí đến một mô hình rẻ hơn, yếu hơn một chút, dành các mô hình cao cấp cho khách hàng trả phí.
Đảm bảo Tính sẵn sàng Cao với Chuyển đổi dự phòng Mô hình
Một nền tảng dịch vụ khách hàng dựa vào một chatbot AI phải hoạt động 24/7. Để ngăn chặn thời gian chết do sự cố của nhà cung cấp LLM hoặc suy giảm hiệu suất, nhóm DevOps triển khai một Cổng LLM. Họ cấu hình một mô hình chính cho tất cả các yêu cầu nhưng thiết lập một mô hình phụ từ một nhà cung cấp khác làm dự phòng. Cổng liên tục theo dõi tình trạng và độ trễ của mô hình chính. Nếu phát hiện sự cố, nó sẽ tự động và liền mạch chuyển hướng tất cả lưu lượng truy cập đến mô hình dự phòng cho đến khi dịch vụ chính được khôi phục, đảm bảo dịch vụ không bị gián đoạn cho người dùng cuối.
Thử nghiệm A/B các LLM để có Hiệu suất Tối ưu
Một nhóm sản phẩm muốn xác định xem một mô hình mã nguồn mở mới, đã được tinh chỉnh, có cung cấp kết quả tốt hơn cho trường hợp sử dụng cụ thể của họ so với LLM thương mại hiện tại hay không. Sử dụng một Cổng LLM, họ thiết lập một thử nghiệm A/B. Cổng được cấu hình để định tuyến 10% lưu lượng người dùng đến mô hình mới trong khi 90% còn lại tiếp tục sử dụng mô hình hiện có. Thông qua nhật ký tập trung của cổng, nhóm có thể dễ dàng so sánh các chỉ số chính như chất lượng phản hồi (qua phản hồi của người dùng), độ trễ và chi phí cho mỗi truy vấn cho cả hai mô hình. Cách tiếp cận dựa trên dữ liệu này cho phép họ đưa ra quyết định sáng suốt mà không làm gián đoạn trải nghiệm người dùng.
Quản lý và Phiên bản hóa Prompt Tập trung
Một nhóm lớn các nhà phát triển và kỹ sư prompt làm việc trên một ứng dụng với hàng chục tính năng do AI điều khiển. Việc quản lý và cập nhật các prompt trực tiếp trong mã ứng dụng rất chậm và dễ xảy ra lỗi. Họ áp dụng một Cổng LLM bao gồm một hệ thống quản lý prompt. Điều này cho phép họ lưu trữ, phiên bản hóa và triển khai các mẫu prompt từ một bảng điều khiển trung tâm. Khi một prompt cần được cải thiện, một kỹ sư prompt có thể cập nhật nó trong giao diện người dùng của cổng, và thay đổi được phản ánh ngay lập tức trong ứng dụng mà không cần triển khai mã mới. Điều này tách rời kỹ thuật prompt khỏi vòng đời phát triển phần mềm.
Triển khai Bộ nhớ đệm Ngữ nghĩa để Cải thiện Hiệu suất
Một nền tảng phân tích tin tức tài chính thực hiện các lệnh gọi API thường xuyên và tương tự đến một LLM để tóm tắt các bài báo tin tức nóng hổi. Để giảm độ trễ và cắt giảm chi phí, họ sử dụng một Cổng LLM có khả năng lưu trữ bộ nhớ đệm ngữ nghĩa. Khi có yêu cầu tóm tắt một bài báo mới, cổng trước tiên sẽ kiểm tra bộ nhớ đệm của nó để tìm các yêu cầu tương tự về mặt ngữ nghĩa. Nếu một bản tóm tắt đủ tương tự đã tồn tại, nó sẽ trả về phản hồi được lưu trong bộ nhớ đệm ngay lập tức, tránh một lệnh gọi tốn kém đến LLM. Điều này cải thiện đáng kể thời gian phản hồi cho người dùng xem các câu chuyện tin tức phổ biến và giảm tổng chi tiêu API hơn 40%.