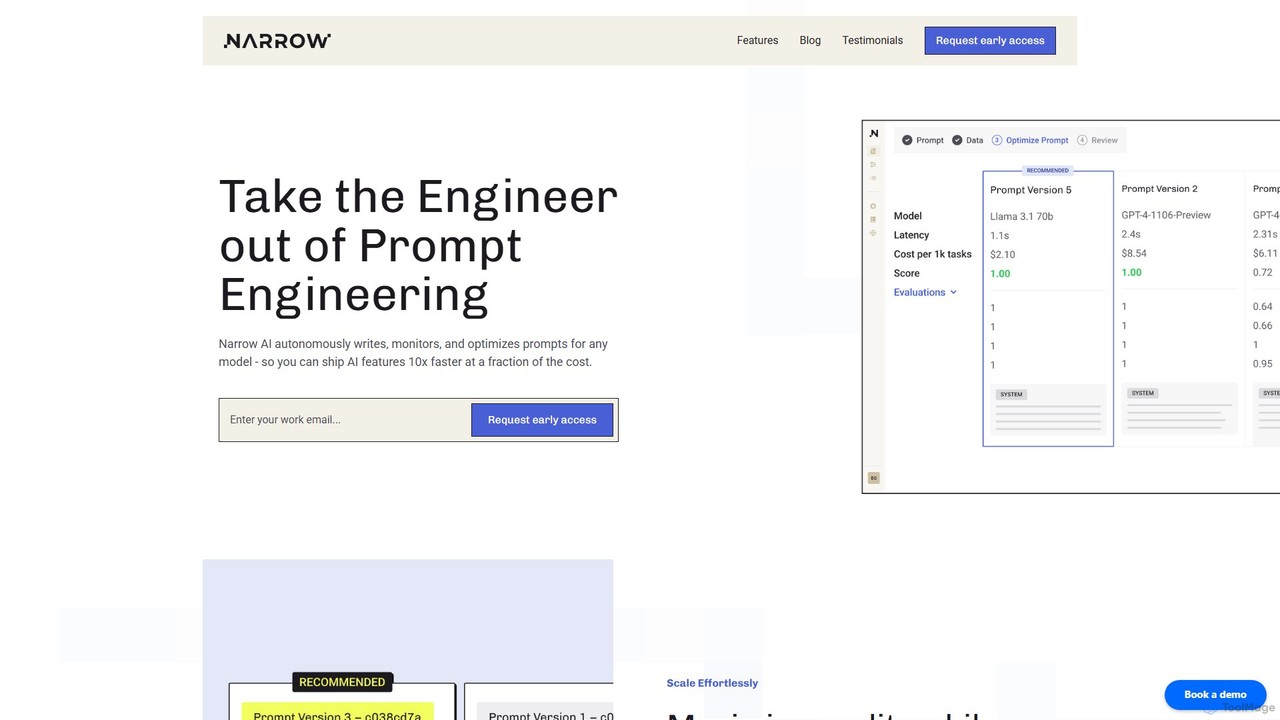
Narrow AI
Narrow AI là một nền tảng tối ưu hóa LLM dành cho nhà phát triển, tự động hóa …
Narrow AI là một nền tảng tối ưu hóa LLM dành cho nhà phát triển, tự động hóa kỹ thuật prompt và lựa chọn mô hình để giảm đáng kể chi phí vận hành AI lên đến 95%. Nền tảng này hợp lý hóa quy trình làm việc, cải thiện độ chính xác và tăng tốc việc triển khai các tính năng AI chất lượng cao, độ trễ thấp.
Về Tối ưu hóa Mô hình
Công cụ Tối ưu hóa Mô hình là một danh mục chuyên biệt của phần mềm cơ sở hạ tầng AI được thiết kế để làm cho các mô hình học máy đã được huấn luyện trở nên nhỏ hơn, nhanh hơn và tiết kiệm năng lượng hơn. Các công cụ này áp dụng các kỹ thuật như lượng tử hóa, cắt tỉa và chưng cất kiến thức để giảm dấu chân tính toán và bộ nhớ của mô hình mà không làm giảm độ chính xác đáng kể. Quá trình này rất quan trọng để triển khai AI phức tạp trên phần cứng có tài nguyên hạn chế, chẳng hạn như điện thoại di động hoặc thiết bị IoT, và để giảm chi phí vận hành của các dịch vụ AI quy mô lớn trên đám mây. Chúng thu hẹp khoảng cách giữa một mô hình đã được huấn luyện và ứng dụng thực tế của nó.
Tính năng Cốt lõi
- Lượng tử hóa (Quantization): Giảm độ chính xác của trọng số mô hình (ví dụ: từ float 32-bit xuống integer 8-bit) để giảm kích thước và tăng tốc độ tính toán.
- Cắt tỉa (Pruning): Loại bỏ một cách có hệ thống các trọng số hoặc kết nối ít quan trọng hơn khỏi mạng nơ-ron để tạo ra một mô hình nhỏ hơn, thưa thớt hơn.
- Chưng cất kiến thức (Knowledge Distillation): Huấn luyện một mô hình "học sinh" nhỏ gọn hơn để bắt chước hành vi của một mô hình "giáo viên" lớn hơn, phức tạp hơn.
- Biên dịch mô hình (Model Compilation): Chuyển đổi một mô hình thành một định dạng thực thi được tối ưu hóa cao và dành riêng cho phần cứng mục tiêu như GPU, TPU hoặc CPU.
- Phân tích hiệu suất (Performance Profiling): Phân tích quá trình thực thi của mô hình để xác định và giải quyết các điểm nghẽn về hiệu suất liên quan đến tốc độ, bộ nhớ hoặc mức tiêu thụ điện năng.
Trường hợp sử dụng
Tối ưu hóa Mô hình là điều cần thiết cho các kỹ sư MLOps, nhà phát triển AI và kỹ sư hệ thống nhúng. Nó được sử dụng rộng rãi trong các ngành công nghiệp như điện tử tiêu dùng cho AI trên thiết bị, ô tô cho các hệ thống nhận thức thời gian thực và điện toán đám mây để quản lý chi phí suy luận của các mô hình ngôn ngữ lớn (LLM) và các công cụ đề xuất. Bất kỳ ứng dụng nào yêu cầu suy luận AI hiệu quả đều được hưởng lợi từ các công cụ này.
Cách chọn
Khi chọn một công cụ Tối ưu hóa Mô hình, hãy xem xét khả năng tương thích của nó với các framework AI của bạn (ví dụ: TensorFlow, PyTorch, ONNX). Đánh giá sự hỗ trợ của nó cho phần cứng mục tiêu của bạn, từ GPU cấp máy chủ đến NPU di động. Đánh giá phạm vi các kỹ thuật tối ưu hóa mà nó cung cấp và mức độ tự động hóa so với kiểm soát thủ công. Cuối cùng, hãy phân tích khả năng quản lý sự đánh đổi giữa lợi ích về hiệu suất và sự suy giảm độ chính xác tiềm ẩn.
Tối ưu hóa Mô hìnhTrường hợp sử dụng
Triển khai mô hình AI trên thiết bị biên
Một nhà phát triển ứng dụng di động cần tích hợp tính năng phát hiện đối tượng thời gian thực vào ứng dụng của họ. Mô hình ban đầu quá lớn và chậm để chạy mượt mà trên điện thoại thông minh, gây hao pin và trải nghiệm người dùng kém. Bằng cách sử dụng công cụ tối ưu hóa mô hình, nhà phát triển áp dụng lượng tử hóa 8-bit và cắt tỉa cho mô hình. Điều này giúp giảm kích thước của nó đi 75% và tăng tốc độ suy luận lên gấp ba lần, cho phép tính năng chạy hiệu quả trên thiết bị với tác động tối thiểu đến thời lượng pin, mang lại trải nghiệm người dùng nhạy bén và mạnh mẽ.
Giảm chi phí suy luận trên đám mây cho các LLM
Một công ty khởi nghiệp công nghệ vận hành một dịch vụ chatbot phổ biến được cung cấp bởi một mô hình ngôn ngữ lớn (LLM). Chi phí cao của máy chủ GPU cho việc suy luận đang ảnh hưởng đến lợi nhuận của họ. Đội ngũ MLOps sử dụng một bộ công cụ tối ưu hóa mô hình để áp dụng chưng cất kiến thức và cắt tỉa có cấu trúc. Họ tạo ra một mô hình nhỏ hơn, chuyên biệt hơn, giữ lại 98% hiệu suất của mô hình gốc trên các tác vụ cụ thể của họ. Mô hình được tối ưu hóa này có thể xử lý số lượng người dùng đồng thời nhiều hơn 2,5 lần trên cùng một phần cứng, trực tiếp giảm hóa đơn cơ sở hạ tầng đám mây của họ hơn 50% và cải thiện khả năng mở rộng của dịch vụ.
Kích hoạt AI thời gian thực trong hệ thống ô tô
Một kỹ sư ô tô đang phát triển Hệ thống Hỗ trợ Lái xe Nâng cao (ADAS) sử dụng mạng nơ-ron để phát hiện người đi bộ. Hệ thống có yêu cầu độ trễ nghiêm ngặt — quyết định phải được đưa ra trong vài mili giây. Kỹ sư sử dụng một công cụ biên dịch mô hình để chuyển đổi mô hình PyTorch của họ thành một công cụ được tối ưu hóa cao cho GPU nhúng cụ thể của ô tô. Quá trình biên dịch hợp nhất các lớp và tối ưu hóa quyền truy cập bộ nhớ, giảm độ trễ suy luận đi 60% và đảm bảo hệ thống đáp ứng các mục tiêu hiệu suất thời gian thực quan trọng về an toàn.
Tích hợp mô hình vào vi điều khiển công suất thấp
Một kỹ sư hệ thống nhúng đang thiết kế một thiết bị nhà thông minh với tính năng phát hiện từ khóa. Phần cứng mục tiêu là một vi điều khiển nhỏ chỉ có 256KB RAM. Mô hình TensorFlow Lite ban đầu quá lớn để vừa. Sử dụng một bộ công cụ tối ưu hóa nâng cao, kỹ sư áp dụng cắt tỉa trọng số mạnh mẽ và lượng tử hóa số nguyên 8-bit. Điều này thu nhỏ kích thước mô hình từ 1MB xuống chỉ còn 180KB, cho phép nó được triển khai thành công trên vi điều khiển trong khi vẫn duy trì độ chính xác trên 95% cho các từ khóa mục tiêu, làm cho tính năng thông minh trở nên khả thi.
Tăng tốc công cụ đề xuất thương mại điện tử
Một nhóm MLOps tại một công ty thương mại điện tử lớn quản lý một mô hình đề xuất học sâu. Để cung cấp các đề xuất thời gian thực, độ trễ suy luận phải cực kỳ thấp. Họ sử dụng một công cụ phân tích hiệu suất để xác định rằng các lớp cụ thể trong mô hình của họ là các điểm nghẽn tính toán trên GPU máy chủ của họ. Công cụ tối ưu hóa đề xuất các tối ưu hóa có mục tiêu, bao gồm biên dịch các lớp cụ thể này với độ chính xác khác nhau (độ chính xác hỗn hợp). Sau khi áp dụng những thay đổi này, độ trễ từ đầu đến cuối của dịch vụ đề xuất giảm 40%, dẫn đến tải trang nhanh hơn và tăng đáng kể sự tương tác của người dùng và doanh số bán hàng.
Tối ưu hóa mô hình NLP để có phản hồi API nhanh hơn
Một công ty SaaS cung cấp API tóm tắt văn bản. Khách hàng phàn nàn về thời gian phản hồi chậm đối với các tài liệu lớn. Nhóm backend xác định mô hình NLP là điểm nghẽn. Thay vì huấn luyện lại một mô hình mới từ đầu, họ sử dụng phương pháp chưng cất kiến thức. Họ huấn luyện một mô hình Transformer nhỏ hơn, nhanh hơn ('học sinh') để sao chép đầu ra của mô hình lớn, chính xác của họ ('giáo viên'). Mô hình học sinh mới nhanh hơn 4 lần và được triển khai vào sản xuất, giảm thời gian phản hồi API trung bình từ 3 giây xuống dưới 700 mili giây, cải thiện đáng kể sự hài lòng của khách hàng.