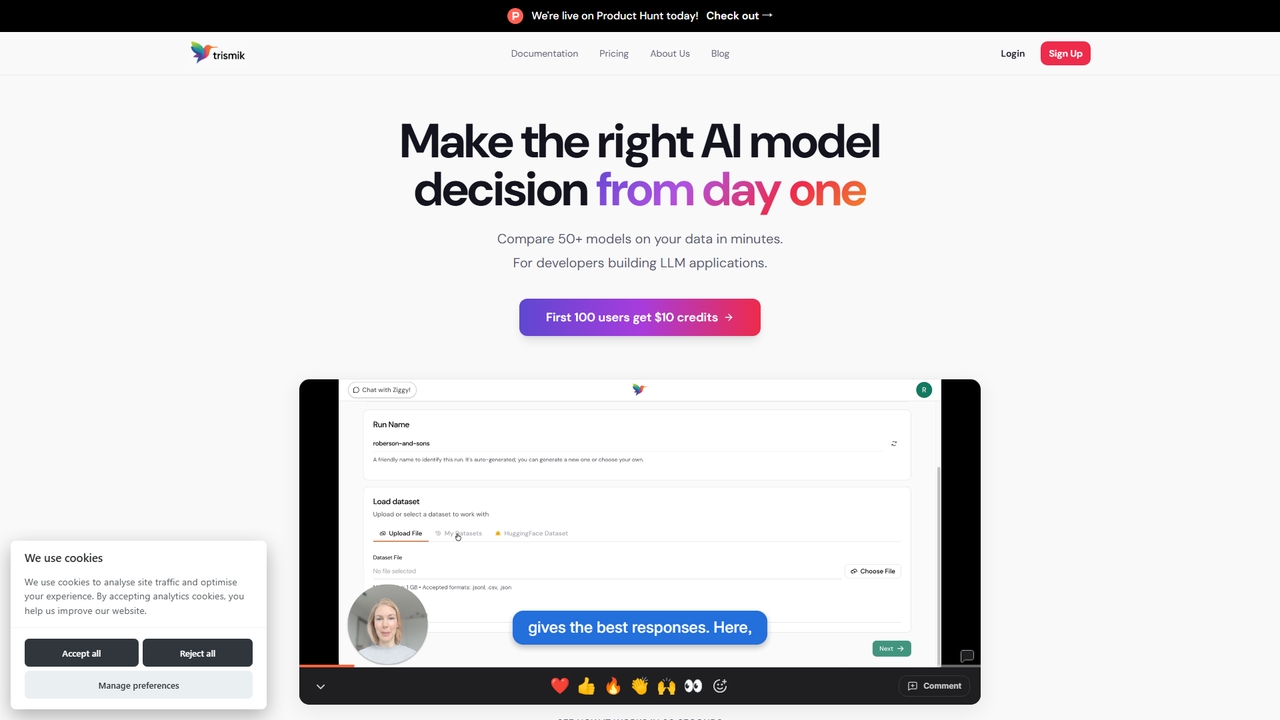
Trismik
So sánh hơn 50 LLM trên dữ liệu của bạn trong vài phút. Đưa ra quyết định chọn …
So sánh hơn 50 LLM trên dữ liệu của bạn trong vài phút. Đưa ra quyết định chọn mô hình dựa trên bằng chứng về chất lượng, chi phí và tốc độ.
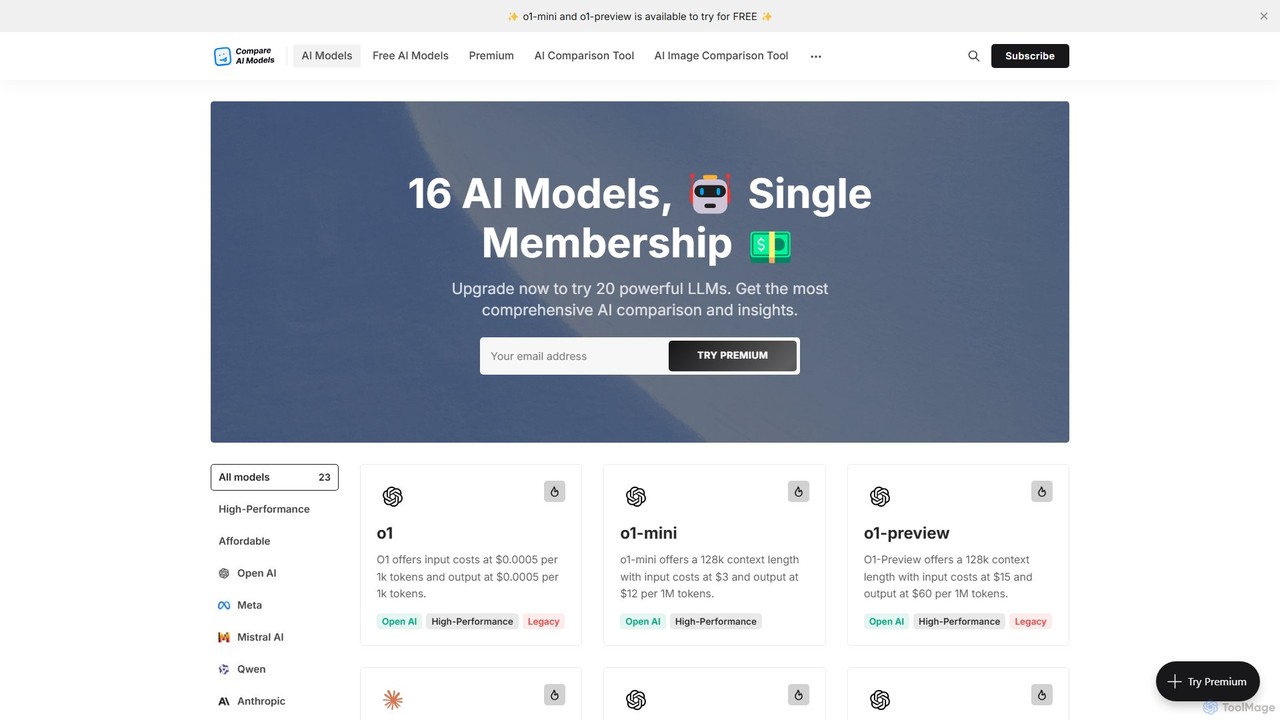
Compare AI Models
Một nền tảng toàn diện để so sánh hơn 20 Mô hình Ngôn ngữ Lớn (LLM) hàng đầu. …
Một nền tảng toàn diện để so sánh hơn 20 Mô hình Ngôn ngữ Lớn (LLM) hàng đầu. Nền tảng này cung cấp các chỉ số chi tiết về hiệu suất, giá API, cửa sổ ngữ cảnh và các tính năng, cùng với một cuộc trò chuyện miễn phí để kiểm tra trực tiếp các mô hình. Một công cụ thiết yếu cho các nhà phát triển, nhà nghiên cứu và doanh nghiệp để tìm ra AI hoàn hảo cho nhu cầu của họ.
Joythee AI
Joythee AI là một nền tảng AI đàm thoại tiên tiến cho phép bạn trò chuyện với nhiều …
Joythee AI là một nền tảng AI đàm thoại tiên tiến cho phép bạn trò chuyện với nhiều tác nhân AI cùng một lúc. So sánh các câu trả lời từ nhiều LLM khác nhau trong một giao diện duy nhất, tận hưởng các cuộc trò chuyện được cá nhân hóa và bảo vệ quyền riêng tư của bạn bằng chế độ ẩn danh. Lý tưởng cho cá nhân, đội nhóm và doanh nghiệp muốn nâng cao năng suất và sự sáng tạo.
Về So sánh Mô hình
Công cụ So sánh Mô hình là các nền tảng chuyên dụng trong bộ công cụ của nhà phát triển, được thiết kế để đánh giá, đo điểm chuẩn và so sánh hiệu suất của các mô hình AI khác nhau một cách có hệ thống. Các công cụ này cung cấp một môi trường có cấu trúc để chạy các mô hình như LLM hoặc trình tạo hình ảnh trên cùng một đầu vào và bộ dữ liệu để đo lường kết quả của chúng một cách khách quan. Chúng rất cần thiết để đưa ra quyết định dựa trên dữ liệu, cho phép các nhà phát triển và nhà nghiên cứu chọn mô hình chính xác, tiết kiệm chi phí và hiệu quả nhất cho một ứng dụng cụ thể. Bằng cách cung cấp phân tích song song và các chỉ số định lượng, chúng hợp lý hóa quy trình lựa chọn mô hình vốn phức tạp và tốn thời gian.
Tính năng Cốt lõi
- Sân chơi So sánh Song song: So sánh ngay lập tức kết quả đầu ra từ nhiều mô hình cho cùng một lời nhắc trong một giao diện thống nhất.
- Đo điểm chuẩn Tự động: Chạy các bài kiểm tra tiêu chuẩn ngành (ví dụ: MMLU, HumanEval) để chấm điểm các mô hình về các khả năng khác nhau.
- Phân tích Chi phí và Độ trễ: Theo dõi và so sánh chi phí tài chính và thời gian phản hồi cho mỗi lần suy luận của mô hình.
- Đánh giá Định tính: Tạo điều kiện cho phản hồi và chấm điểm của con người về các tiêu chí chủ quan như sự mạch lạc, phong cách hoặc an toàn.
- Kiểm soát Phiên bản & Lịch sử: Ghi lại và theo dõi các thử nghiệm đánh giá theo thời gian để giám sát các thay đổi về hiệu suất và sự suy giảm.
Trường hợp Sử dụng
Các công cụ này rất quan trọng đối với các nhà phát triển AI, kỹ sư MLOps và quản lý sản phẩm trong suốt vòng đời phát triển và bảo trì. Chúng được sử dụng khi chọn một mô hình nền tảng cho một tính năng mới, đánh giá tác động của việc tinh chỉnh hoặc tiến hành kiểm thử hồi quy sau khi cập nhật mô hình. Ví dụ, một nhóm xây dựng chatbot dịch vụ khách hàng sẽ sử dụng các công cụ này để so sánh khả năng đàm thoại và chi phí của các mô hình từ OpenAI, Anthropic và Google trước khi quyết định chọn một mô hình.
Cách Lựa chọn
Khi chọn một công cụ So sánh Mô hình, hãy xem xét phạm vi các mô hình được hỗ trợ, bao gồm cả API độc quyền và các tùy chọn mã nguồn mở. Đánh giá các bộ điểm chuẩn có sẵn và tính linh hoạt để tạo bộ dữ liệu đánh giá tùy chỉnh. Đánh giá khả năng tích hợp của nó với quy trình làm việc MLOps và các đường ống CI/CD hiện có của bạn. Cuối cùng, hãy xem xét các tính năng cộng tác cho phép các thành viên trong nhóm xem xét kết quả và các mô hình định giá có thể mở rộng theo nhu cầu đánh giá của bạn.
So sánh Mô hìnhTrường hợp sử dụng
Lựa chọn LLM Tối ưu cho Chatbot Mới
Một nhóm sản phẩm đang phát triển một chatbot hỗ trợ khách hàng mới được hỗ trợ bởi AI. Họ sử dụng một công cụ so sánh mô hình để đánh giá GPT-4, Claude 3 Sonnet và Llama 3 70B. Họ tạo ra một 'bộ dữ liệu vàng' gồm 100 truy vấn khách hàng phổ biến và chạy cả ba mô hình trên đó. Nền tảng này cung cấp một chế độ xem song song các câu trả lời, cùng với các chỉ số tự động về mức độ hữu ích và giọng điệu. Nó cũng tính toán chi phí trung bình cho mỗi 1.000 cuộc trò chuyện cho mỗi mô hình. Dựa trên kết quả, họ chọn Claude 3 Sonnet vì nó cung cấp sự cân bằng tốt nhất giữa chất lượng đàm thoại và chi phí vận hành cho trường hợp sử dụng cụ thể của họ.
Đánh giá Hiệu suất Mô hình đã được Tinh chỉnh
Một kỹ sư ML đã tinh chỉnh một mô hình mã nguồn mở Mistral 7B trên các tài liệu nội bộ của công ty cho một tác vụ hỏi-đáp. Để chứng minh cho việc triển khai, họ sử dụng một công cụ so sánh để đo điểm chuẩn của mô hình đã tinh chỉnh so với mô hình Mistral 7B cơ sở và một mô hình độc quyền như GPT-4. Họ tải lên một bộ thử nghiệm gồm 50 câu hỏi kỹ thuật. Công cụ này đo lường độ chính xác thực tế và sự liên quan. Kết quả cho thấy mô hình đã tinh chỉnh của họ vượt trội hơn mô hình cơ sở 30% về độ chính xác và rẻ hơn 10 lần so với GPT-4, cung cấp bằng chứng rõ ràng để tiến hành triển khai.
Kiểm thử Hồi quy cho các Cập nhật API Mô hình
Một nhóm MLOps quản lý một tính năng tóm tắt phụ thuộc vào API mô hình bên ngoài. Nhà cung cấp API thông báo một phiên bản mới. Trước khi chuyển đổi, nhóm sử dụng một nền tảng so sánh mô hình để chạy bộ 500 tài liệu thử nghiệm của họ qua cả phiên bản API cũ và mới. Nền tảng này tự động gắn cờ bất kỳ bản tóm tắt nào từ phiên bản mới ngắn hơn đáng kể, kém mạch lạc hơn hoặc không chính xác về mặt thực tế so với đầu ra của phiên bản cũ. Việc kiểm thử hồi quy tự động này ngăn chặn sự suy giảm chất lượng dịch vụ và đảm bảo quá trình chuyển đổi sang mô hình được cập nhật diễn ra suôn sẻ.
So sánh các Mô hình Tạo ảnh cho Tiếp thị
Một công ty tiếp thị cần chọn một mô hình tạo ảnh để tạo các sản phẩm quảng cáo. Họ sử dụng một công cụ so sánh để kiểm tra DALL-E 3, Midjourney và Stable Diffusion với 20 lời nhắc khác nhau liên quan đến sản phẩm của khách hàng. Công cụ này cho phép đội ngũ sáng tạo của họ xếp hạng mỗi hình ảnh được tạo trên thang điểm từ 1-5 về mức độ tuân thủ lời nhắc, chất lượng thẩm mỹ và sự phù hợp với thương hiệu. Điểm số tổng hợp cho thấy mặc dù Midjourney tạo ra những hình ảnh đẹp nhất về mặt thẩm mỹ, DALL-E 3 lại vượt trội trong việc kết hợp chính xác các chi tiết sản phẩm cụ thể được đề cập trong lời nhắc, khiến nó trở thành lựa chọn tốt hơn cho nhu cầu của họ.
Tối ưu hóa Chi phí-Hiệu suất cho API Tóm tắt
Một dịch vụ tổng hợp tin tức sử dụng LLM để tóm tắt các bài báo. Để giảm chi phí, họ muốn tìm mô hình rẻ nhất mà vẫn duy trì chất lượng. Sử dụng một công cụ so sánh, họ thử nghiệm năm mô hình khác nhau, từ GPT-4 cao cấp đến các lựa chọn thay thế mã nguồn mở nhỏ hơn. Họ cho 1.000 bài báo chạy qua mỗi mô hình và sử dụng điểm ROUGE tự động để đo chất lượng tóm tắt, trong khi công cụ theo dõi chi phí cho mỗi mô hình. Họ phát hiện ra rằng một phiên bản lượng tử hóa của mô hình Llama 3 8B cung cấp 95% chất lượng của GPT-4 với chỉ 10% chi phí, dẫn đến tiết kiệm đáng kể hàng tháng.
Thử nghiệm A/B Lời nhắc trên Nhiều Mô hình
Một kỹ sư lời nhắc được giao nhiệm vụ tạo ra lời nhắc hiệu quả nhất cho một tính năng tạo mã. Thay vì thử nghiệm từng lời nhắc một, họ sử dụng một công cụ so sánh mô hình để thiết lập một thử nghiệm ma trận. Họ nhập ba biến thể lời nhắc khác nhau và thử nghiệm chúng trên bốn mô hình (ví dụ: GPT-4, Claude 3 Opus, Gemini Pro và một mô hình mã chuyên dụng). Nền tảng này chạy tất cả 12 kết hợp và trình bày kết quả dưới dạng bản đồ nhiệt, cho thấy cặp lời nhắc-mô hình nào tạo ra mã chính xác và hiệu quả nhất. Điều này giúp tăng tốc quá trình tối ưu hóa lời nhắc lên gấp mười lần.