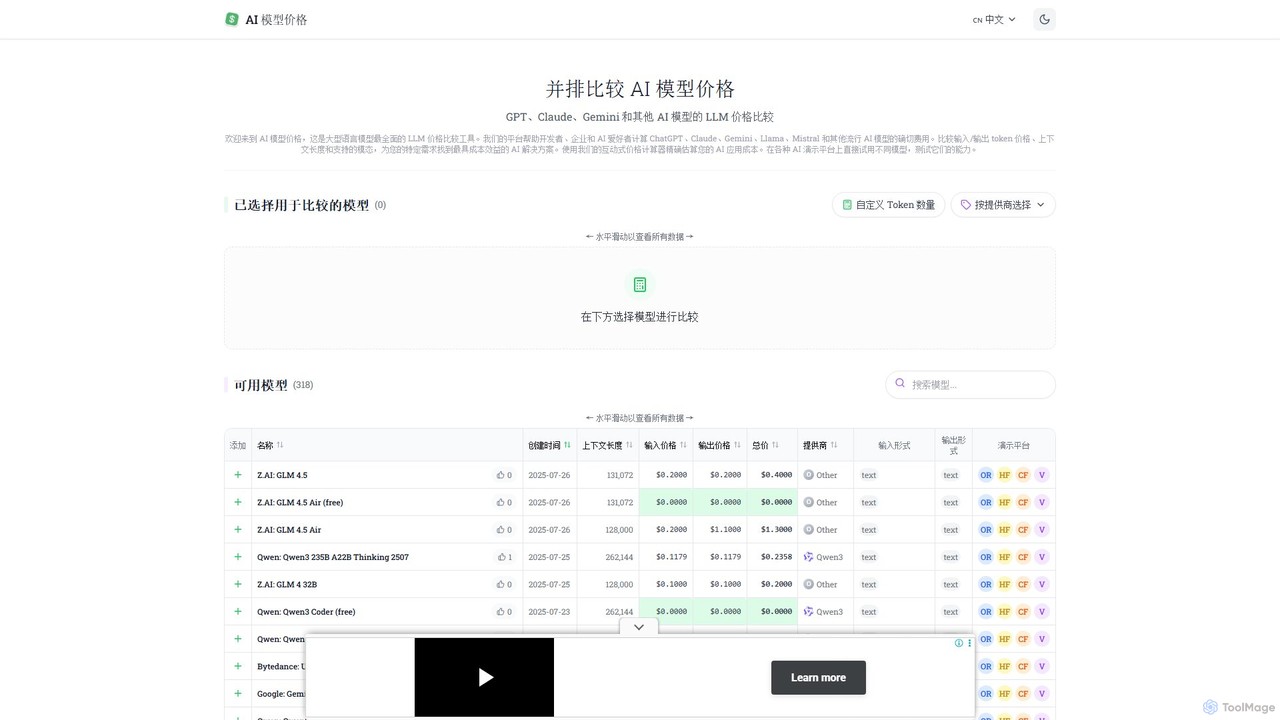
llm_price
llm_price là một công cụ so sánh toàn diện về giá API của các Mô hình Ngôn ngữ …
llm_price là một công cụ so sánh toàn diện về giá API của các Mô hình Ngôn ngữ Lớn (LLM). Nó cho phép các nhà phát triển, doanh nghiệp và những người đam mê AI dễ dàng so sánh chi phí của hàng trăm mô hình từ các nhà cung cấp như OpenAI, Google, Anthropic và Mistral. Với một máy tính chi phí tương tác và phân tích song song về giá token, độ dài ngữ cảnh và các phương thức, nó đơn giản hóa quá trình lựa chọn giải pháp AI hiệu quả nhất về chi phí cho bất kỳ dự án nào.

abcdindex
abcdindex (Academic Business Current Data Index) là một nền tảng miễn phí và toàn diện dành cho cộng …
abcdindex (Academic Business Current Data Index) là một nền tảng miễn phí và toàn diện dành cho cộng đồng học thuật. Nó cung cấp một cơ sở dữ liệu đã được xác minh và có cấu trúc về các tạp chí quốc tế, bài báo nghiên cứu, cơ hội tài trợ, học bổng và các tài nguyên học thuật khác. Nền tảng này nhằm mục đích giúp các nhà nghiên cứu, sinh viên và nhà xuất bản điều hướng hiệu quả trong môi trường học thuật và tránh các ấn phẩm săn mồi hoặc không hoạt động bằng cách cung cấp thông tin đáng tin cậy, tập trung.
Về Cơ sở dữ liệu
Cơ sở dữ liệu AI là các bộ sưu tập dữ liệu có cấu trúc được tuyển chọn, đóng vai trò là tài nguyên cơ bản để huấn luyện, kiểm thử và triển khai các mô hình trí tuệ nhân tạo. Các tài nguyên này được chuẩn bị đặc biệt để máy tính sử dụng, thường chứa một lượng lớn dữ liệu có nhãn hoặc không có nhãn như hình ảnh, văn bản hoặc số liệu. Chúng cung cấp nguyên liệu thô thiết yếu cho các nhiệm vụ học máy, xử lý ngôn ngữ tự nhiên và thị giác máy tính. Chất lượng, quy mô và sự liên quan của các cơ sở dữ liệu này quyết định trực tiếp đến hiệu suất và khả năng của một hệ thống AI.
Tính năng Cốt lõi
- Dữ liệu có cấu trúc và được gán nhãn: Dữ liệu được tổ chức và thường được chú thích bằng nhãn, phù hợp cho các thuật toán học có giám sát.
- Quy mô lớn: Thường chứa hàng triệu hoặc thậm chí hàng tỷ điểm dữ liệu để đảm bảo các mô hình có thể học được các mẫu tổng quát.
- Tính đặc thù theo lĩnh vực: Tập trung vào các lĩnh vực cụ thể như y tế, tài chính hoặc lái xe tự động để xây dựng AI chuyên biệt.
- Chất lượng và tính nhất quán của dữ liệu: Được làm sạch và xác thực để giảm thiểu nhiễu và sai lệch, điều này rất quan trọng để xây dựng các mô hình đáng tin cậy.
Trường hợp sử dụng
Cơ sở dữ liệu AI rất cần thiết cho các nhà khoa học dữ liệu, kỹ sư học máy và nhà nghiên cứu. Chúng được sử dụng để huấn luyện hệ thống nhận dạng khuôn mặt bằng bộ dữ liệu hình ảnh, phát triển các mô hình ngôn ngữ sử dụng kho văn bản khổng lồ và xây dựng các thuật toán phát hiện gian lận từ dữ liệu giao dịch lịch sử. Các tổ chức học thuật cũng sử dụng các bộ dữ liệu tiêu chuẩn hóa để đánh giá hiệu suất của các thuật toán AI mới.
Cách lựa chọn
Khi chọn một Cơ sở dữ liệu AI, hãy xem xét sự liên quan của nó đến lĩnh vực vấn đề cụ thể của bạn. Đánh giá chất lượng dữ liệu, độ chính xác của nhãn và sự hiện diện của các sai lệch tiềm ẩn. Kiểm tra các điều khoản cấp phép để đảm bảo nó có thể được sử dụng cho mục đích dự định của bạn (ví dụ: học thuật so với thương mại). Cuối cùng, đánh giá định dạng và kích thước dữ liệu để xác nhận khả năng tương thích với tài nguyên tính toán và chuỗi công cụ của bạn.
Cơ sở dữ liệuTrường hợp sử dụng
Huấn luyện Mô hình Phân tích Hình ảnh Y tế
Một nhà nghiên cứu AI trong lĩnh vực chăm sóc sức khỏe cần phát triển một mô hình có thể phát hiện các dấu hiệu sớm của bệnh từ các bản quét y tế như X-quang hoặc MRI. Họ sử dụng một cơ sở dữ liệu chuyên biệt, chất lượng cao gồm hàng nghìn hình ảnh y tế đã được ẩn danh, mỗi hình ảnh đều được các bác sĩ X-quang chú thích tỉ mỉ. Bằng cách huấn luyện một mô hình thị giác máy tính trên bộ dữ liệu này, hệ thống sẽ học cách xác định các mẫu tinh vi liên quan đến các tình trạng cụ thể. Công cụ AI kết quả có thể hỗ trợ các bác sĩ X-quang bằng cách làm nổi bật các khu vực có khả năng đáng lo ngại, dẫn đến chẩn đoán nhanh hơn và chính xác hơn.
Phát triển Mô hình Xử lý Ngôn ngữ Tự nhiên (NLP)
Một nhóm khoa học dữ liệu được giao nhiệm vụ xây dựng một công cụ phân tích tình cảm cho các bài đánh giá của khách hàng. Để đạt được điều này, họ tận dụng một cơ sở dữ liệu văn bản quy mô lớn chứa hàng triệu bài đánh giá sản phẩm, mỗi bài được dán nhãn là tích cực, tiêu cực hoặc trung tính. Kho ngữ liệu này đóng vai trò là sự thật cơ bản để huấn luyện mô hình NLP của họ. Mô hình xử lý văn bản, học các sắc thái của ngôn ngữ và xác định các mẫu tương quan với các tình cảm khác nhau. Sau khi huấn luyện, công cụ có thể tự động phân loại các bài đánh giá mới, chưa từng thấy, cung cấp cho doanh nghiệp những hiểu biết quý giá về sự hài lòng của khách hàng trên quy mô lớn.
Xây dựng Hệ thống Phát hiện Gian lận Tài chính
Một công ty công nghệ tài chính (fintech) nhằm mục đích giảm các giao dịch gian lận cho người dùng của mình. Các kỹ sư học máy của họ sử dụng một cơ sở dữ liệu lịch sử khổng lồ về dữ liệu giao dịch. Cơ sở dữ liệu này bao gồm các đặc điểm như số tiền giao dịch, thời gian, địa điểm và loại hình người bán, với mỗi giao dịch được dán nhãn là hợp pháp hoặc gian lận. Bằng cách huấn luyện một mô hình phát hiện bất thường trên dữ liệu này, hệ thống sẽ học được các đặc điểm của hành vi giao dịch bình thường. Khi một giao dịch mới xảy ra, mô hình có thể dự đoán xác suất gian lận của nó trong thời gian thực, cho phép công ty chặn các hoạt động đáng ngờ và bảo vệ khách hàng của mình.
Đánh giá hiệu năng các thuật toán AI mới
Một phòng thí nghiệm nghiên cứu học thuật phát triển một thuật toán mới để nhận dạng đối tượng. Để chứng minh hiệu quả của nó, họ phải so sánh hiệu suất của nó với các phương pháp tiên tiến hiện có. Họ sử dụng một cơ sở dữ liệu công khai, được tiêu chuẩn hóa như ImageNet hoặc COCO, được cộng đồng nghiên cứu chấp nhận rộng rãi để đánh giá hiệu năng. Bằng cách chạy thuật toán mới của họ và các thuật toán đã có trên cùng một bộ dữ liệu, họ có thể thu được các chỉ số khách quan như độ chính xác và tốc độ xử lý. Điều này cho phép họ công bố các phát hiện của mình với kết quả có thể kiểm chứng, góp phần vào sự tiến bộ của lĩnh vực AI.
Cung cấp năng lượng cho Hệ thống Hỏi-Đáp dựa trên Tri thức
Một công ty công nghệ pháp lý muốn tạo ra một trợ lý AI có thể trả lời các câu hỏi pháp lý phức tạp. Thay vì một kho văn bản chung, họ sử dụng một cơ sở tri thức chuyên biệt—một cơ sở dữ liệu có cấu trúc chứa các đạo luật, án lệ và các bài báo học thuật, tất cả được kết nối với nhau thông qua một đồ thị tri thức. Khi một luật sư đặt câu hỏi, AI không chỉ tìm kiếm từ khóa; nó điều hướng đồ thị này để hiểu các mối quan hệ và ngữ cảnh. Điều này cho phép hệ thống cung cấp các câu trả lời có độ chính xác cao, nhận biết ngữ cảnh và được hỗ trợ bởi các trích dẫn pháp lý cụ thể, hoạt động như một công cụ nghiên cứu mạnh mẽ cho các chuyên gia pháp lý.
Tạo dữ liệu tổng hợp để kiểm thử mô hình AI
Một nhóm phát triển AI đang xây dựng một hệ thống xe tự lái nhưng thiếu đủ dữ liệu thực tế cho các trường hợp biên hiếm gặp, như động vật đột ngột băng qua đường. Họ sử dụng một cơ sở dữ liệu nền tảng về các kịch bản lái xe để tạo ra một lượng lớn dữ liệu tổng hợp thực tế. Quá trình này cho phép họ tạo ra hàng nghìn biến thể của một kịch bản duy nhất, thay đổi điều kiện thời tiết, ánh sáng và tốc độ của vật thể. Bằng cách kiểm thử mô hình của họ trên cơ sở dữ liệu tổng hợp toàn diện này, họ có thể đảm bảo AI hoạt động mạnh mẽ và đáng tin cậy trong các tình huống quá nguy hiểm hoặc không thường xuyên để ghi lại trong thực tế, mà không ảnh hưởng đến quyền riêng tư của người dùng.