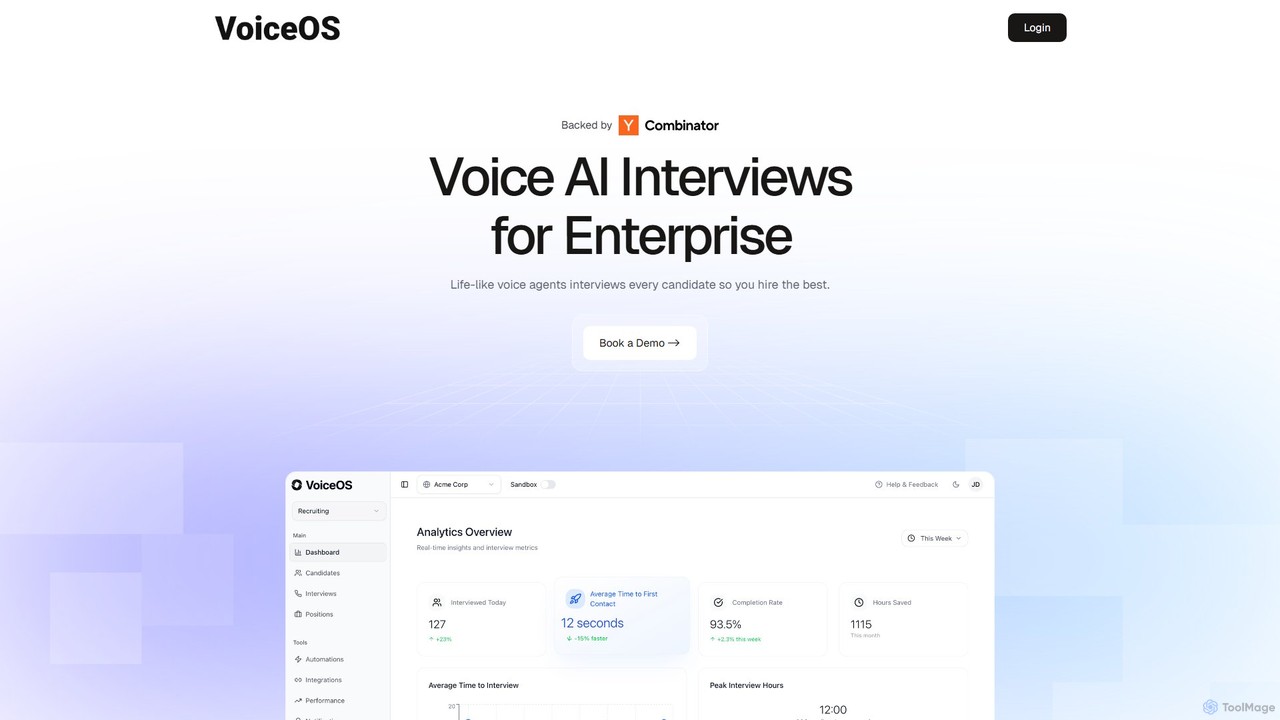
VoiceOS
VoiceOS là một nền tảng do AI cung cấp cho doanh nghiệp, tự động hóa việc sàng lọc …
VoiceOS là một nền tảng do AI cung cấp cho doanh nghiệp, tự động hóa việc sàng lọc ứng viên ban đầu thông qua các cuộc phỏng vấn bằng giọng nói sống động như thật. Nó tích hợp với bất kỳ ATS nào, tiến hành phỏng vấn 24/7 và cung cấp phân tích nâng cao về tình cảm, sự phù hợp văn hóa và kinh nghiệm. Điều này giúp hợp lý hóa việc tuyển dụng số lượng lớn, giảm thiểu thành kiến và cho phép các nhóm tuyển dụng tập trung vào những ứng viên đủ tiêu chuẩn nhất, đẩy nhanh quá trình tuyển dụng.
Về Giọng nói & Ngôn ngữ
Công cụ Giọng nói & Ngôn ngữ là các giải pháp do AI cung cấp để tạo, chuyển đổi và phân tích giọng nói của con người. Các công cụ này sử dụng các công nghệ cốt lõi như Chuyển văn bản thành giọng nói (TTS) để tạo âm thanh từ văn bản và Chuyển giọng nói thành văn bản (STT) để phiên âm lời nói thành dạng văn bản. Chúng được ứng dụng rộng rãi để tạo thuyết minh chân thực, tự động hóa phiên âm, phát triển trợ lý giọng nói và tăng cường khả năng tiếp cận. Khả năng xử lý và tái tạo các sắc thái về tông giọng, ngữ điệu và cảm xúc làm cho chúng trở nên rất hiệu quả cho giao tiếp và sáng tạo nội dung.
Tính năng Cốt lõi
- Chuyển văn bản thành giọng nói (TTS): Chuyển đổi văn bản viết thành âm thanh nói tự nhiên, giống con người bằng nhiều ngôn ngữ và giọng nói khác nhau.
- Chuyển giọng nói thành văn bản (STT) / Phiên âm: Phiên âm chính xác ngôn ngữ nói từ các tệp âm thanh hoặc video thành văn bản có thể tìm kiếm, chỉnh sửa.
- Nhân bản giọng nói: Tạo ra một bản sao kỹ thuật số của một giọng nói cụ thể từ một mẫu âm thanh ngắn, cho phép tạo ra lời nói mới bằng chính giọng nói đó.
- Nhận dạng giọng nói: Xác định và diễn giải các lệnh nói hoặc xác thực người dùng dựa trên các đặc điểm giọng nói độc nhất của họ.
- Phân tích giọng nói: Phân tích các cuộc hội thoại âm thanh để trích xuất thông tin chi tiết về tình cảm, từ khóa, tông giọng và hiệu suất của người nói.
Trường hợp sử dụng
Các công cụ này rất cần thiết trong các ngành như truyền thông và giải trí để sản xuất thuyết minh, trong dịch vụ khách hàng để xây dựng hệ thống Tương tác bằng giọng nói (IVR), và trong y tế để lập hồ sơ lâm sàng. Người sáng tạo nội dung, podcaster, nhà tiếp thị, nhà phát triển và nhà nghiên cứu sử dụng chúng để tự động hóa quy trình làm việc, tạo nội dung dễ tiếp cận và phân tích dữ liệu giọng nói.
Cách lựa chọn
Khi chọn một công cụ Giọng nói & Ngôn ngữ, hãy đánh giá sự tự nhiên và chất lượng của giọng nói được tạo ra hoặc độ chính xác của bản phiên âm. Xem xét phạm vi các ngôn ngữ, phương ngữ và giọng điệu được hỗ trợ. Đối với các nhà phát triển, sự sẵn có và tài liệu của API là rất quan trọng. Ngoài ra, hãy đánh giá các tùy chọn tùy chỉnh như nhân bản giọng nói, điều chỉnh tốc độ và các mô hình định giá dựa trên ký tự, phút hoặc các gói đăng ký.
Giọng nói & Ngôn ngữTrường hợp sử dụng
Tạo thuyết minh chân thực cho nội dung video
Một người tạo video hoặc nhà tiếp thị cần sản xuất một video quảng cáo bằng nhiều ngôn ngữ nhưng không có ngân sách cho các diễn viên lồng tiếng chuyên nghiệp. Bằng cách sử dụng công cụ Chuyển văn bản thành giọng nói (TTS), họ có thể nhập kịch bản của mình và tạo ra âm thanh chất lượng cao, tự nhiên cho mỗi ngôn ngữ yêu cầu. Quá trình này cho phép họ điều chỉnh tông giọng, tốc độ và cảm xúc để phù hợp với bối cảnh của video. Kết quả là nội dung video được bản địa hóa chuyên nghiệp, sản xuất nhanh chóng và hiệu quả về chi phí, cho phép họ tiếp cận khán giả toàn cầu mà không cần đầu tư đáng kể vào phòng thu hoặc tài năng.
Tự động hóa phiên âm cuộc họp và phỏng vấn
Một nhà báo, nhà nghiên cứu hoặc quản lý dự án thực hiện nhiều cuộc phỏng vấn hoặc cuộc họp hàng ngày cần có hồ sơ văn bản chính xác để phân tích. Việc phiên âm thủ công hàng giờ âm thanh tốn thời gian và dễ xảy ra lỗi. Bằng cách tải các bản ghi âm lên công cụ Chuyển giọng nói thành văn bản (STT), họ sẽ nhận được một bản phiên âm tự động, có dấu thời gian trong vòng vài phút. Nhiều công cụ còn có thể phân biệt giữa những người nói khác nhau. Việc tự động hóa này giúp tiết kiệm hàng giờ lao động thủ công, đẩy nhanh quá trình tạo nội dung hoặc nghiên cứu, và cung cấp một tài liệu văn bản có thể tìm kiếm để dễ dàng tham khảo và trích xuất dữ liệu.
Phát triển hệ thống Tương tác bằng giọng nói (IVR)
Một người quản lý dịch vụ khách hàng nhằm mục đích cải thiện hiệu quả của trung tâm cuộc gọi bằng cách tự động hóa các truy vấn phổ biến. Sử dụng các công cụ nhận dạng giọng nói và TTS, các nhà phát triển có thể xây dựng một hệ thống Tương tác bằng giọng nói (IVR). Hệ thống sử dụng nhận dạng giọng nói để hiểu yêu cầu nói của khách hàng (ví dụ: "kiểm tra số dư tài khoản của tôi"). Sau đó, nó xử lý yêu cầu và sử dụng TTS để cung cấp một phản hồi nói rõ ràng. Điều này giải phóng các nhân viên con người để xử lý các vấn đề phức tạp hơn, giảm thời gian chờ đợi của khách hàng và cung cấp hỗ trợ 24/7, cuối cùng cải thiện sự hài lòng chung của khách hàng và hiệu quả hoạt động.
Tạo sách nói và nội dung podcast
Một tác giả hoặc nhà xuất bản muốn chuyển đổi một cuốn sách viết thành sách nói để tiếp cận nhiều đối tượng hơn. Thay vì chi phí cao và tốn thời gian thuê diễn viên lồng tiếng và đặt phòng thu, họ có thể sử dụng công cụ TTS có độ trung thực cao. Bằng cách nhập văn bản của cuốn sách, họ có thể tạo ra toàn bộ nội dung âm thanh với một giọng nói AI biểu cảm, nhất quán. Tương tự, một podcaster có thể sử dụng TTS để tạo các phân đoạn, giới thiệu hoặc thậm chí toàn bộ các tập với giọng nói tổng hợp, cho phép sản xuất nội dung nhanh chóng và thử nghiệm với các phong cách giọng nói khác nhau mà không cần phải ghi âm giọng nói của chính mình.
Cá nhân hóa giọng nói thương hiệu bằng nhân bản giọng nói
Một giám đốc tiếp thị muốn thiết lập một nhận dạng âm thanh độc đáo và nhất quán cho thương hiệu của họ trên tất cả các nền tảng, từ quảng cáo đến trợ lý trong ứng dụng. Thay vì dựa vào các giọng nói có sẵn chung chung, họ có thể sử dụng công cụ nhân bản giọng nói. Bằng cách cung cấp một bản ghi âm ngắn, chất lượng cao từ một diễn viên lồng tiếng được chọn, công cụ sẽ tạo ra một mô hình giọng nói AI tùy chỉnh. Mô hình này sau đó có thể được sử dụng để tạo ra bất kỳ nội dung âm thanh mới nào, đảm bảo rằng mọi thông điệp thương hiệu đều được truyền tải bằng cùng một giọng nói độc quyền và dễ nhận biết. Điều này giúp tăng cường khả năng ghi nhớ thương hiệu và tạo ra một kết nối cá nhân hơn với khán giả.
Tăng cường khả năng tiếp cận cho người dùng khiếm thị
Một nhà phát triển web hoặc người tạo nội dung cần làm cho nội dung số của họ, chẳng hạn như các bài báo và tài liệu giáo dục, có thể truy cập được cho người dùng khiếm thị. Bằng cách tích hợp API Chuyển văn bản thành giọng nói (TTS), họ có thể thêm tính năng "đọc to" vào trang web hoặc ứng dụng của mình. Điều này cho phép người dùng nghe văn bản trên màn hình thay vì đọc nó. Điều này không chỉ giúp đạt được sự tuân thủ với các tiêu chuẩn tiếp cận như WCAG mà còn cung cấp một trải nghiệm người dùng toàn diện hơn, đảm bảo rằng thông tin có giá trị có sẵn cho mọi người, bất kể khả năng thị giác của họ.