FinetuneFast
Truy cập trang web chính thức
FinetuneFast Tổng quan
FinetuneFast là một bộ công cụ thiết yếu được thiết kế cho các kỹ sư ML, nhà phát triển và các nhà sản xuất độc lập muốn tăng tốc vòng đời phát triển AI của họ. Nó cung cấp một bộ sưu tập toàn diện các boilerplate ML giúp hợp lý hóa toàn bộ quy trình, từ đào tạo mô hình và chuẩn bị dữ liệu đến triển khai và mở rộng quy mô. Sứ mệnh cốt lõi của FinetuneFast, được tạo ra bởi kỹ sư ML và SRE giàu kinh nghiệm Patrick, là loại bỏ các tác vụ lặp đi lặp lại và tốn thời gian liên quan đến việc thiết lập cơ sở hạ tầng AI, cho phép người sáng tạo tập trung vào những gì thực sự quan trọng: xây dựng và hoàn thiện các mô hình AI mạnh mẽ.
Nền tảng này giải quyết các điểm yếu phổ biến trong quy trình làm việc ML, chẳng hạn như cấu hình môi trường, làm sạch dữ liệu, tích hợp API và triển khai mô hình. Bằng cách cung cấp các giải pháp được cấu hình sẵn và sẵn sàng cho sản xuất, FinetuneFast tuyên bố sẽ giúp các nhà phát triển tiết kiệm hơn 20 giờ làm việc trong một dự án thông thường, biến một nỗ lực kéo dài nhiều tuần thành chỉ trong vài ngày.
Cách sử dụng FinetuneFast
Sử dụng FinetuneFast là một quy trình đơn giản cho bất kỳ ai có kinh nghiệm lập trình. Sau khi mua một gói, bạn sẽ nhận được quyền truy cập thủ công vào một kho lưu trữ GitHub riêng tư trong vòng 24 giờ. Bên trong, bạn sẽ tìm thấy một bộ sưu tập các boilerplate và mẫu được tổ chức tốt. Quy trình làm việc điển hình như sau:
- Chọn một Boilerplate: Chọn mẫu phù hợp cho dự án của bạn, cho dù đó là tinh chỉnh một LLM như Llama-3, một mô hình văn bản thành hình ảnh như Flux-Schnell, hay triển khai một hệ thống RAG (Retrieval-Augmented Generation).
- Thiết lập và Cấu hình: Làm theo tài liệu chi tiết để thiết lập môi trường của bạn và cấu hình các tập lệnh với các tham số và đường dẫn dữ liệu cụ thể của bạn.
- Chuẩn bị Dữ liệu: Sử dụng các đường ống tải dữ liệu hiệu quả để chuẩn bị và định dạng dữ liệu đào tạo của bạn.
- Đào tạo Mô hình: Chạy các tập lệnh đào tạo được cấu hình sẵn. Các boilerplate bao gồm hỗ trợ đào tạo đa GPU và các công cụ tối ưu hóa siêu tham số để đạt được kết quả tốt nhất.
- Triển khai: Khi mô hình của bạn đã được tinh chỉnh, hãy sử dụng các boilerplate triển khai để triển khai bằng một cú nhấp chuột. Điều này tạo ra một điểm cuối API có thể mở rộng cho mô hình của bạn, hoàn chỉnh với việc giám sát và ghi nhật ký.
- Hỗ trợ: Đối với các câu hỏi kỹ thuật, gói 'All In' cung cấp quyền truy cập vào một cộng đồng Discord chuyên dụng để được hỗ trợ từ người tạo và những người dùng khác.
Tính năng chính của FinetuneFast
- Boilerplate Tinh chỉnh: Các tập lệnh sẵn sàng cho sản xuất để tinh chỉnh các mô hình khác nhau, bao gồm LLM (OpenAI, Mistral, Llama-3.2), mô hình văn bản thành hình ảnh (Flux-Schnell) và văn bản thành giọng nói (Fish-Speech).
- Boilerplate Suy luận và Triển khai: Các giải pháp triển khai đơn giản bằng một cú nhấp chuột để tạo các điểm cuối API tự động mở rộng quy mô và sẵn sàng cho sản xuất cho các mô hình của bạn.
- Ví dụ và Mẫu RAG: Các mẫu sẵn sàng sử dụng để xây dựng các hệ thống Retrieval-Augmented Generation tiên tiến, cho phép các mô hình truy cập kiến thức bên ngoài.
- Đường ống Dữ liệu Hiệu quả: Các tập lệnh được tối ưu hóa để tải và xử lý dữ liệu, một phần quan trọng nhưng thường tốn thời gian của quy trình ML.
- Hỗ trợ Đa GPU: Hỗ trợ sẵn có cho việc đào tạo trên nhiều GPU, giúp tăng tốc đáng kể quá trình đào tạo.
- Bao gồm các Thực tiễn Tốt nhất: Mã nguồn kết hợp các thực tiễn tốt nhất trong ML và SRE, đảm bảo các mô hình của bạn không chỉ mạnh mẽ mà còn đáng tin cậy và có thể mở rộng.
Các trường hợp sử dụng FinetuneFast
FinetuneFast rất linh hoạt và có thể được sử dụng cho nhiều dự án khác nhau:
- Sản phẩm AI SaaS: Các nhà phát triển độc lập có thể nhanh chóng xây dựng và ra mắt các ứng dụng AI-SaaS chuyên biệt, chẳng hạn như một trình tạo nội dung chuyên dụng hoặc một công cụ tạo hình ảnh tùy chỉnh.
- Chatbot Tùy chỉnh: Các doanh nghiệp có thể tinh chỉnh một LLM mã nguồn mở trên các tài liệu nội bộ của họ để tạo ra một cơ sở kiến thức riêng hoặc một bot hỗ trợ khách hàng.
- Tạo nghệ thuật bằng AI: Các nghệ sĩ và nhà thiết kế có thể tinh chỉnh các mô hình hình ảnh theo phong cách độc đáo của họ để tạo ra các tác phẩm nghệ thuật nhất quán và nguyên bản.
- Tạo mẫu Nhanh: Các kỹ sư ML có thể nhanh chóng kiểm tra và xác thực các ý tưởng mới mà không bị sa lầy vào việc thiết lập cơ sở hạ tầng cơ bản.
- Dịch vụ AI Chuyên biệt: Xây dựng các công cụ cụ thể như xóa nền (RMBG-1.4) hoặc các ứng dụng đa phương thức (Molmo-7B) bằng cách sử dụng các boilerplate được cung cấp.
Ưu điểm của FinetuneFast
Ưu điểm chính của FinetuneFast là tốc độ. Nó giảm đáng kể thời gian phát triển. Các lợi ích chính khác bao gồm:
- Hiệu quả về Chi phí: Thanh toán một lần cung cấp quyền truy cập vào tất cả các tài liệu cho các dự án không giới hạn, làm cho nó rẻ hơn nhiều so với các nền tảng dựa trên đăng ký hoặc thuê người để thiết lập.
- Sẵn sàng cho Sản xuất: Các boilerplate không chỉ dành cho các bài tập học thuật; chúng được xây dựng để xử lý lưu lượng truy cập thực tế và tự động mở rộng quy mô.
- Được xây dựng bởi Chuyên gia: Được thiết kế bởi một kỹ sư có chuyên môn sâu về cả Machine Learning và Site Reliability Engineering (SRE), đảm bảo các tiêu chuẩn cao về chất lượng và độ tin cậy.
- Giải pháp Toàn diện: Bao gồm toàn bộ vòng đời ML từ đầu đến cuối, từ đào tạo đến triển khai và giám sát.
Giá cả và gói dịch vụ
FinetuneFast cung cấp một mô hình thanh toán một lần đơn giản.
- Gói Starter: Có giá $99.99 (đang giảm giá từ $159.99). Gói này bao gồm Boilerplate Tinh chỉnh, Boilerplate Suy luận Sẵn sàng cho Sản xuất, Ví dụ và Mẫu RAG, và hướng dẫn Thực tiễn Tốt nhất.
- Gói All In: Có giá $119.99 (đang giảm giá từ $199.99). Gói này bao gồm mọi thứ trong gói Starter, cộng với quyền truy cập vào Cộng đồng Discord riêng tư để được hỗ trợ và Cập nhật Trọn đời cho kho lưu trữ.
Cả hai gói đều cung cấp giấy phép 'thanh toán một lần, xây dựng dự án không giới hạn'.
FinetuneFast Bình luận (0)
Đăng nhập để bình luận
Đăng nhập ngayFinetuneFast Các lựa chọn thay thế
Xem tất cả
thundercompute
Thunder Compute cung cấp một nền tảng đám mây GPU chi phí cực thấp được thiết kế cho …
Thunder Compute cung cấp một nền tảng đám mây GPU chi phí cực thấp được thiết kế cho các nhà phát triển AI và học máy. Nó cung cấp các phiên bản GPU theo yêu cầu như NVIDIA A100 và T4 với giá thấp hơn tới 80% so với các nhà cung cấp đám mây lớn. Với các tính năng như thiết lập bằng một cú nhấp chuột, tích hợp VS Code và khả năng mở rộng liền mạch, nó đơn giản hóa đáng kể quy trình làm việc phát triển, từ tạo mẫu đến sản xuất, cho phép các nhà phát triển tập trung vào việc xây dựng mô hình thay vì quản lý cơ sở hạ tầng.

Paperspace
Paperspace là một nền tảng điện toán đám mây hiệu suất cao được thiết kế cho AI và …
Paperspace là một nền tảng điện toán đám mây hiệu suất cao được thiết kế cho AI và Học máy. Nó cung cấp quyền truy cập dễ dàng vào các GPU đám mây mạnh mẽ, sổ tay Jupyter được quản lý và một nền tảng MLOps hoàn chỉnh (Gradient) để xây dựng, huấn luyện và triển khai các mô hình. Lý tưởng cho các nhà phát triển, nhà khoa học dữ liệu và doanh nghiệp muốn tăng tốc quy trình làm việc AI của họ mà không cần phải quản lý cơ sở hạ tầng phức tạp.
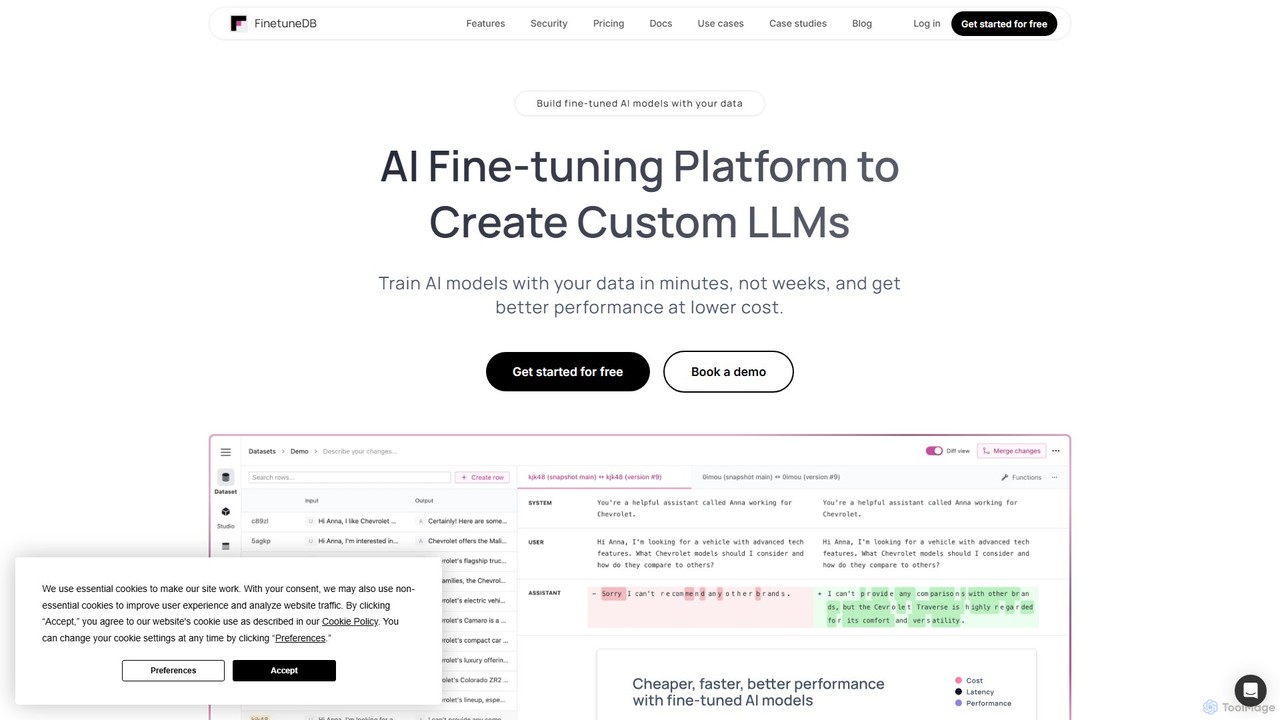
FinetuneDB
FinetuneDB là một nền tảng tinh chỉnh AI tất cả trong một dành cho nhà phát triển. Nó …
FinetuneDB là một nền tảng tinh chỉnh AI tất cả trong một dành cho nhà phát triển. Nó đơn giản hóa toàn bộ quy trình tạo Mô hình Ngôn ngữ Lớn (LLM) tùy chỉnh, từ việc xây dựng bộ dữ liệu chất lượng cao và tinh chỉnh các mô hình như Llama 3 và GPT-4o mini, đến việc triển khai và đánh giá liên tục trên một nền tảng duy nhất, an toàn.

Ollama
Ollama là một framework mã nguồn mở mạnh mẽ để chạy các mô hình ngôn ngữ lớn (LLM) …
Ollama là một framework mã nguồn mở mạnh mẽ để chạy các mô hình ngôn ngữ lớn (LLM) như Llama 3, Mistral và Gemma cục bộ trên phần cứng của riêng bạn. Có sẵn cho macOS, Windows và Linux, nó đơn giản hóa việc thiết lập và quản lý các mô hình mã nguồn mở, cho phép phát triển và sử dụng AI một cách riêng tư, ngoại tuyến và tiết kiệm chi phí.

LAION
LAION (Mạng lưới Trí tuệ Nhân tạo Mở Quy mô lớn) là một tổ chức phi lợi nhuận …
LAION (Mạng lưới Trí tuệ Nhân tạo Mở Quy mô lớn) là một tổ chức phi lợi nhuận chuyên về dân chủ hóa nghiên cứu AI. Tổ chức này cung cấp các bộ dữ liệu mã nguồn mở khổng lồ, các mô hình được huấn luyện trước và công cụ cho công chúng, thúc đẩy nghiên cứu mở, giáo dục và phát triển hiệu quả về tài nguyên trong học máy.
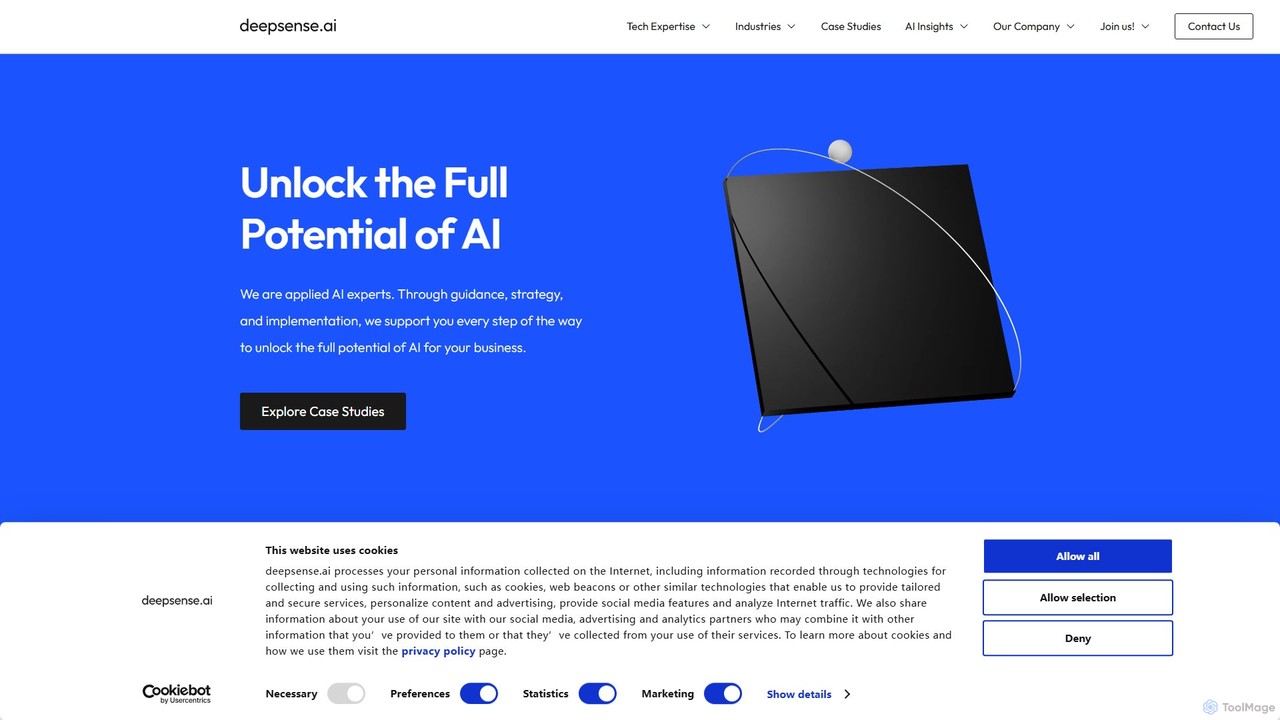
deepsense.ai
deepsense.ai là một công ty tư vấn AI và phát triển phần mềm tùy chỉnh hàng đầu. Họ …
deepsense.ai là một công ty tư vấn AI và phát triển phần mềm tùy chỉnh hàng đầu. Họ chuyên tạo ra các giải pháp AI phù hợp cho doanh nghiệp, tận dụng chuyên môn về LLM, RAG, thị giác máy tính, MLOps và phân tích dự đoán. Họ hợp tác với các doanh nghiệp và công ty khởi nghiệp để nhúng AI vào sản phẩm, tối ưu hóa hoạt động và giành lợi thế cạnh tranh thông qua các hệ thống AI tiên tiến, sẵn sàng cho sản xuất.

xTuring
xTuring là một thư viện Python mã nguồn mở được thiết kế để đơn giản hóa quá trình …
xTuring là một thư viện Python mã nguồn mở được thiết kế để đơn giản hóa quá trình xây dựng, tinh chỉnh và kiểm soát các Mô hình Ngôn ngữ Lớn (LLM). Nó cung cấp một giao diện thân thiện với người dùng cho các nhà phát triển và nhà nghiên cứu để cá nhân hóa các mô hình AI cho dữ liệu và ứng dụng cụ thể với hiệu quả và khả năng tùy chỉnh cao.

Pydantic
Pydantic là một nền tảng toàn diện dành cho nhà phát triển, cung cấp khả năng xác thực …
Pydantic là một nền tảng toàn diện dành cho nhà phát triển, cung cấp khả năng xác thực dữ liệu mạnh mẽ, công cụ phát triển AI và giải pháp quan sát toàn diện (full-stack observability). Nó cho phép phát triển ứng dụng nhanh hơn, mạnh mẽ hơn bằng Python và các ngôn ngữ khác bằng cách tận dụng gợi ý kiểu (type hints) để xác thực dữ liệu thời gian chạy và cung cấp thông tin chi tiết sâu sắc từ môi trường phát triển cục bộ đến sản xuất.
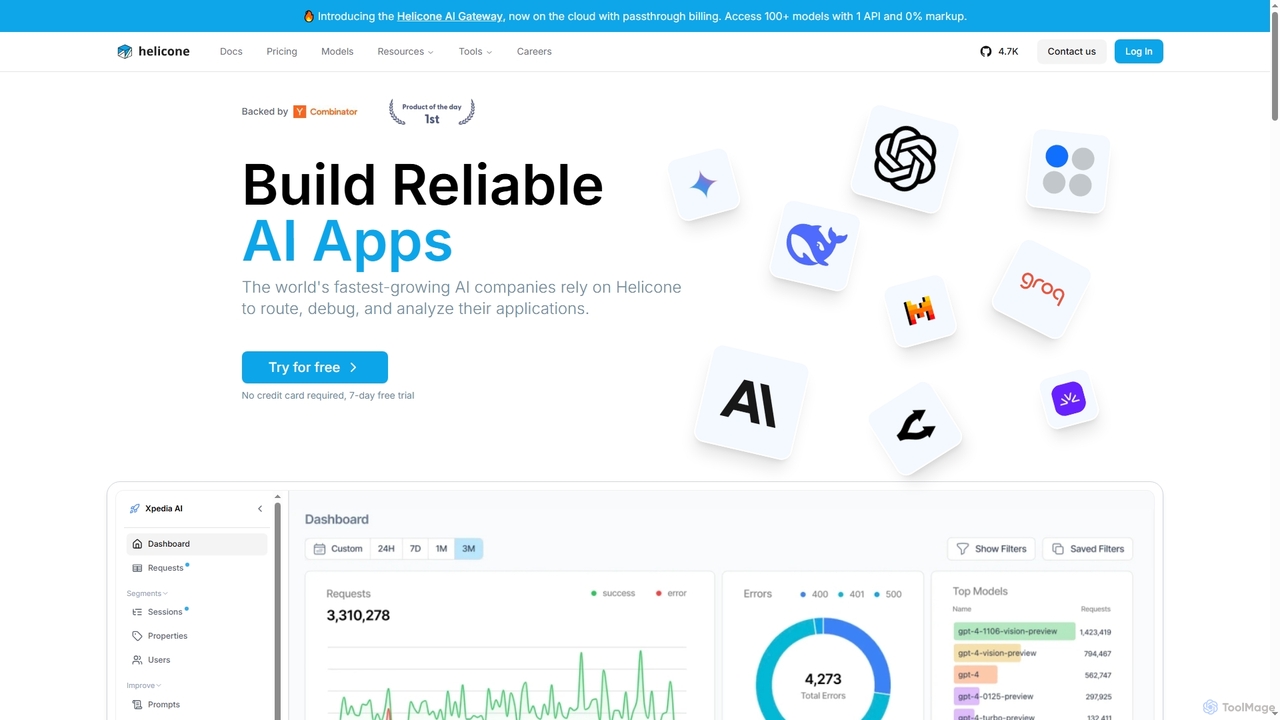
Helicone
Helicone là một nền tảng mã nguồn mở cung cấp Cổng AI và Khả năng quan sát LLM …
Helicone là một nền tảng mã nguồn mở cung cấp Cổng AI và Khả năng quan sát LLM cho các nhà phát triển. Nó giúp xây dựng các ứng dụng AI đáng tin cậy bằng cách cung cấp các công cụ để định tuyến, giám sát, gỡ lỗi và phân tích việc sử dụng LLM. Các tính năng chính bao gồm API hợp nhất cho hơn 100 mô hình, bộ nhớ đệm thông minh, giới hạn tốc độ, quản lý prompt và phân tích hiệu suất chi tiết.

hyperficient
hyperficient là một công cụ AI mã nguồn mở dành cho các nhà phát triển và kỹ sư …
hyperficient là một công cụ AI mã nguồn mở dành cho các nhà phát triển và kỹ sư ML, giúp tự động hóa việc tìm kiếm các chiến lược tinh chỉnh (fine-tuning) hiệu quả nhất cho các mạng nơ-ron. Nó giảm đáng kể chi phí tính toán, thời gian GPU và công sức thủ công, cho phép đạt hiệu suất mô hình tối ưu với nguồn lực hạn chế.
FinetuneFast Danh mục
FinetuneFast Thẻ
FinetuneFast Công cụ AI
FinetuneFast Tính năng nhúng
Chỉ cần sao chép mã nhúng bên dưới, dán huy hiệu đẹp mắt vào blog, bài viết hoặc trang web chính thức của ứng dụng để hướng lưu lượng truy cập trực tiếp đến trang chi tiết của công cụ này, giúp nhanh chóng tăng độ hiển thị và số lượng người dùng!

Chưa có bình luận nào, hãy là người đầu tiên bình luận!