WhisperUI
Truy cập trang web chính thức
WhisperUI Tổng quan
WhisperUI là một nền tảng toàn diện và linh hoạt, tận dụng các mô hình Whisper và Text-to-Speech mạnh mẽ của OpenAI để cung cấp các dịch vụ phiên âm âm thanh và tạo giọng nói chất lượng cao. Nó phục vụ cho nhiều đối tượng người dùng thông qua hai hình thức cung cấp: một giao diện web thân thiện với người dùng và một ứng dụng máy tính để bàn độc lập mạnh mẽ. Cách tiếp cận kép này cho phép người dùng lựa chọn giữa sự tiện lợi của dịch vụ dựa trên đám mây và sự riêng tư cùng việc sử dụng không giới hạn của xử lý cục bộ.
Phiên bản web của WhisperUI cung cấp cả chức năng Chuyển đổi Giọng nói thành Văn bản (S2T) và Chuyển đổi Văn bản thành Giọng nói (T2S). Nó hoạt động theo mô hình "Mang theo khóa của riêng bạn" (BYOK), nơi người dùng kết nối khóa API OpenAI của họ và trả tiền trực tiếp cho OpenAI cho việc sử dụng của họ, làm cho nó trở thành một giải pháp rất hiệu quả về chi phí. Gói miễn phí hỗ trợ phiên âm cơ bản, trong khi các tính năng cao cấp mở khóa các khả năng như tải lên tệp hàng loạt và tạo tệp phụ đề SRT. Dịch vụ T2S cho phép người dùng chuyển đổi văn bản thành giọng nói sống động như thật, cung cấp nhiều lựa chọn về giọng nói và mô hình chất lượng.
Đối với những người dùng ưu tiên quyền riêng tư dữ liệu, xử lý các tệp lớn hoặc yêu cầu phiên âm không giới hạn, ứng dụng WhisperUI Desktop là giải pháp lý tưởng. Phần mềm dựa trên đăng ký này chạy cục bộ trên các thiết bị Windows và macOS, đảm bảo rằng tất cả dữ liệu âm thanh vẫn nằm trên máy của người dùng. Nó loại bỏ các giới hạn về kích thước và thời lượng tệp, cung cấp phiên âm không giới hạn với một khoản phí hàng tháng cố định, và thậm chí còn hỗ trợ tăng tốc GPU (NVIDIA và AMD) để có tốc độ xử lý nhanh hơn đáng kể.
Cách sử dụng WhisperUI
Sử dụng WhisperUI rất đơn giản, với các bước khác nhau cho phiên bản web và máy tính để bàn:
Đối với Chuyển đổi Giọng nói thành Văn bản trên Web:
- Truy cập trang web WhisperUI.
- Cung cấp khóa API OpenAI của bạn. Khóa của bạn được lưu trữ cục bộ trong trình duyệt của bạn để bảo mật.
- Kéo và thả tệp âm thanh của bạn (ví dụ: mp3, wav, m4a) vào khu vực được chỉ định hoặc duyệt để chọn nó.
- Công cụ sẽ xử lý âm thanh bằng OpenAI Whisper và hiển thị văn bản đã được phiên âm.
- Đối với người dùng cao cấp, bạn có thể tải lên nhiều tệp cùng một lúc và xuất bản phiên âm dưới dạng tệp văn bản hoặc SRT.
Đối với Chuyển đổi Văn bản thành Giọng nói trên Web:
- Đi đến phần Chuyển đổi Văn bản thành Giọng nói trên trang web.
- Nhập khóa API OpenAI của bạn.
- Chọn giọng nói mong muốn của bạn (ví dụ: Alloy, Echo, Nova) và mô hình chất lượng (TTS-1 hoặc TTS-1-HD).
- Nhập hoặc dán văn bản bạn muốn chuyển đổi vào hộp văn bản.
- Nhấp vào "Tạo Giọng nói" để tạo và tải xuống tệp âm thanh.
Đối với Ứng dụng Máy tính để bàn:
- Đăng ký gói WhisperUI Desktop trên trang web.
- Tải xuống và cài đặt ứng dụng trên máy tính Windows hoặc macOS của bạn.
- Sao chép khóa cấp phép từ cài đặt tài khoản của bạn và dán vào ứng dụng máy tính để bàn.
- Bây giờ bạn có thể kéo và thả bất kỳ số lượng tệp âm thanh nào với bất kỳ kích thước nào để phiên âm cục bộ, với kết quả được tạo trực tiếp trên thiết bị của bạn.
Tính năng chính của WhisperUI
- Phiên âm Độ chính xác Cao: Được cung cấp bởi mô hình Whisper của OpenAI, nổi tiếng về khả năng chống lại các giọng điệu, tiếng ồn nền và ngôn ngữ kỹ thuật.
- Tạo Văn bản thành Giọng nói: Chuyển đổi văn bản thành âm thanh tự nhiên với nhiều loại giọng nói và hai cấp độ chất lượng (TTS-1 và TTS-1-HD).
- Nền tảng Kép: Cung cấp cả giao diện web linh hoạt và một ứng dụng máy tính để bàn riêng tư, mạnh mẽ.
- Xử lý Cục bộ: Ứng dụng máy tính để bàn xử lý tất cả dữ liệu cục bộ, đảm bảo quyền riêng tư và bảo mật dữ liệu tối đa.
- Sử dụng Không giới hạn (Máy tính để bàn): Phiên bản máy tính để bàn không có giới hạn về kích thước tệp, thời lượng giọng nói hoặc số lần phiên âm.
- Tăng tốc GPU: Hỗ trợ thử nghiệm cho GPU NVIDIA và AMD trong ứng dụng máy tính để bàn để có hiệu suất nhanh hơn.
- Xuất tệp SRT: Tính năng web cao cấp để tạo tệp phụ đề trực tiếp từ âm thanh.
- Xử lý Hàng loạt: Phiên bản web cao cấp cho phép tải lên và phiên âm nhiều tệp cùng một lúc.
- Hỗ trợ Tệp Rộng rãi: Tương thích với các định dạng âm thanh và video phổ biến như mp3, mp4, mpeg, m4a, wav, ogg và webm.
Các trường hợp sử dụng WhisperUI
Người sáng tạo Nội dung: Phiên âm podcast, phỏng vấn và nội dung video để tạo phụ đề, ghi chú chương trình và bài viết blog, cải thiện khả năng tiếp cận và SEO.
Nhà báo và Nhà nghiên cứu: Nhanh chóng chuyển đổi các cuộc phỏng vấn, bài giảng và ghi chú thực địa đã ghi thành văn bản để phân tích, trích dẫn và báo cáo.
Sinh viên và Nhà giáo dục: Phiên âm các bài giảng để làm ghi chú học tập hoặc tạo phiên bản âm thanh của tài liệu viết cho các phong cách học tập khác nhau.
Chuyên gia Kinh doanh: Tạo biên bản chính xác từ các cuộc họp, cuộc gọi hội nghị và ghi nhớ giọng nói để làm tài liệu và theo dõi hành động.
Nhà phát triển: Sử dụng chức năng Chuyển đổi Văn bản thành Giọng nói để tạo giọng nói cho các ứng dụng, video hoặc mô-đun học tập điện tử.
Ưu điểm của WhisperUI
- Linh hoạt: Người dùng có thể chọn giữa xử lý đám mây trả theo mức sử dụng hoặc đăng ký trả phí cố định để xử lý cục bộ không giới hạn.
- Hiệu quả về Chi phí: Mô hình BYOK của phiên bản web tránh được việc tăng giá, cho phép người dùng trả theo mức giá cơ bản của OpenAI. Ứng dụng máy tính để bàn cung cấp mức giá có thể dự đoán và phải chăng cho người dùng nhiều.
- Tăng cường Quyền riêng tư: Ứng dụng máy tính để bàn là một lợi thế lớn cho người dùng xử lý thông tin nhạy cảm hoặc bí mật, vì không có dữ liệu nào được gửi lên đám mây.
- Sức mạnh và Kiểm soát: Bằng cách tận dụng các mô hình tiên tiến của OpenAI và cung cấp tăng tốc GPU cục bộ, WhisperUI cung cấp cho người dùng các công cụ mạnh mẽ với mức độ kiểm soát cao đối với quy trình làm việc và dữ liệu của họ.
- Giao diện Thân thiện với Người dùng: Chức năng kéo và thả đơn giản giúp người dùng ở mọi cấp độ kỹ thuật đều có thể tiếp cận.
Giá cả và gói dịch vụ
WhisperUI cung cấp một số cấu trúc giá khác nhau:
- Web Chuyển đổi Giọng nói thành Văn bản (Freemium/BYOK): Dịch vụ phiên âm web cơ bản được sử dụng miễn phí. Người dùng phải cung cấp khóa API OpenAI của riêng họ và sẽ được OpenAI thanh toán trực tiếp cho việc sử dụng phiên âm. Các tính năng cao cấp như tải lên hàng loạt và xuất SRT có thể yêu cầu mua thêm hoặc đăng ký.
- Web Chuyển đổi Văn bản thành Giọng nói (Trả theo mức sử dụng/BYOK): Dịch vụ này cũng yêu cầu khóa API OpenAI của người dùng. Việc thanh toán được thực hiện trực tiếp từ OpenAI dựa trên số lượng ký tự: 0,015 đô la cho mỗi 1.000 ký tự đối với mô hình TTS-1 và 0,030 đô la cho mỗi 1.000 ký tự đối với mô hình TTS-1-HD.
- WhisperUI Desktop (Đăng ký): Đây là một gói đăng ký trả phí, có giá 8 đô la/tháng (giá khuyến mãi). Giấy phép cấp quyền truy cập vào ứng dụng máy tính để bàn cho một thiết bị, cung cấp phiên âm cục bộ không giới hạn, tăng cường quyền riêng tư, không giới hạn kích thước tệp và hỗ trợ GPU.
WhisperUI Bình luận (0)
Đăng nhập để bình luận
Đăng nhập ngayWhisperUIPhân tích lưu lượng truy cập website
Tình hình lưu lượng truy cập mới nhất
Trạng thái
Xu hướng lưu lượng truy cập hàng tháng
Vị trí địa lý
Top 5 Quốc gia/Khu vực
-
🇺🇸 United States24,17%
-
🇻🇳 Vietnam24,01%
-
🇮🇹 Italy18,42%
-
🇷🇺 Russia17,35%
-
🇫🇷 France16,05%
Từ khóa phổ biến
| Từ khóa | Chi phí mỗi lượt nhấp |
|---|---|
|
$0,00
|
|
|
$0,00
|
|
|
$2,84
|
|
|
$0,00
|
|
|
$0,00
|
WhisperUI Các lựa chọn thay thế
Xem tất cả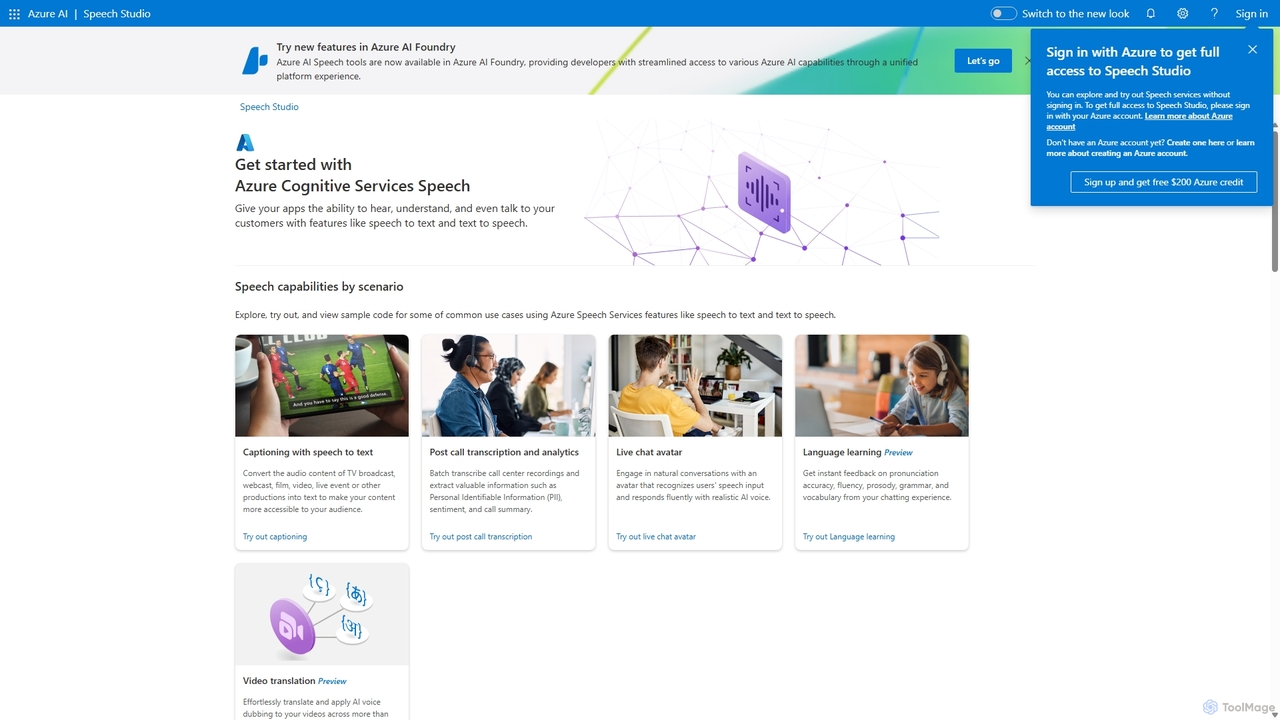
Speech Studio
Speech Studio là một bộ công cụ toàn diện do AI cung cấp từ Microsoft Azure, cho phép …
Speech Studio là một bộ công cụ toàn diện do AI cung cấp từ Microsoft Azure, cho phép các nhà phát triển xây dựng ứng dụng với khả năng giọng nói tiên tiến. Nó cung cấp tính năng chuyển giọng nói thành văn bản có độ chính xác cao, chuyển văn bản thành giọng nói tự nhiên, dịch giọng nói thời gian thực và nhận dạng người nói. Người dùng có thể tạo các mô hình giọng nói tùy chỉnh và giao diện hội thoại, biến nó thành một nền tảng đa năng cho nhiều giải pháp hỗ trợ giọng nói.
AIFreeforever
AIFreeforever là một nền tảng toàn diện cung cấp hơn 700 công cụ AI miễn phí cho việc …
AIFreeforever là một nền tảng toàn diện cung cấp hơn 700 công cụ AI miễn phí cho việc tạo hình ảnh, chatbot, chuyển văn bản thành giọng nói, phiên âm, viết lách và nhiều hơn nữa. Nó không yêu cầu đăng nhập, đăng ký hay thẻ tín dụng, cung cấp quyền truy cập không giới hạn vào các khả năng AI tiên tiến cho người tạo nội dung, sinh viên và các chuyên gia.
FreeTTS
FreeTTS là một bộ công cụ âm thanh đa năng được hỗ trợ bởi AI, cung cấp một …
FreeTTS là một bộ công cụ âm thanh đa năng được hỗ trợ bởi AI, cung cấp một loạt dịch vụ miễn phí và cao cấp. Nó xuất sắc trong việc chuyển đổi văn bản thành giọng nói tự nhiên với nhiều loại giọng nói giống người. Ngoài TTS, nó còn cung cấp tính năng chuyển giọng nói thành văn bản có độ chính xác cao, công cụ tách giọng hát bằng AI, công cụ nâng cao chất lượng giọng nói và các công cụ chỉnh sửa âm thanh khác nhau như chuyển đổi, cắt và ghép. Đây là một giải pháp tất cả trong một cho các nhà sáng tạo nội dung, nhạc sĩ và bất kỳ ai cần xử lý âm thanh chất lượng cao.
freesubtitles.ai
Một công cụ được hỗ trợ bởi AI cung cấp dịch vụ miễn phí và trả phí để …
Một công cụ được hỗ trợ bởi AI cung cấp dịch vụ miễn phí và trả phí để chuyển mã âm thanh và video thành văn bản với độ chính xác cao. Nó hỗ trợ hơn 111 ngôn ngữ để chuyển mã và 91 ngôn ngữ để dịch, sử dụng các mô hình như Whisper của OpenAI. Các tính năng trả phí bao gồm giới hạn cao hơn, quyền truy cập API và xử lý nhanh hơn.

askeygeek
askeygeek là một nền tảng năng suất AI tất cả trong một, cung cấp quyền truy cập vào …
askeygeek là một nền tảng năng suất AI tất cả trong một, cung cấp quyền truy cập vào hơn 1000 mô hình AI hàng đầu (từ OpenAI, Claude, Stability, v.v.) và hơn 1500 công cụ web miễn phí thông qua một tài khoản duy nhất, giá cả phải chăng. Nó tích hợp chuyển văn bản thành giọng nói, phiên âm, tạo nội dung và các tiện ích dành cho nhà phát triển khác nhau để hợp lý hóa quy trình làm việc cho người sáng tạo, nhà tiếp thị và nhà phát triển.
SubEasy
SubEasy là một nền tảng AI thế hệ mới để phiên âm video và âm thanh, tạo phụ …
SubEasy là một nền tảng AI thế hệ mới để phiên âm video và âm thanh, tạo phụ đề và dịch thuật. Được hỗ trợ bởi Whisper của OpenAI, nó mang lại độ chính xác lên đến 99%. Nền tảng hỗ trợ hơn 100 ngôn ngữ, cung cấp tính năng AI Reflow độc đáo để tạo phụ đề được căn chỉnh thời gian hoàn hảo và cung cấp giải pháp tất cả trong một từ phiên âm đến xuất video, lý tưởng cho người sáng tạo nội dung, nhà giáo dục và doanh nghiệp.
Voiser
Voiser là một nền tảng AI tiên tiến cung cấp dịch vụ chuyển văn bản thành giọng nói …
Voiser là một nền tảng AI tiên tiến cung cấp dịch vụ chuyển văn bản thành giọng nói (TTS) chất lượng cao, chuyển giọng nói thành văn bản (ghi âm) chính xác và dịch vụ nhân bản giọng nói sáng tạo. Hỗ trợ hơn 75 ngôn ngữ với hơn 550 giọng nói, nó cung cấp một bộ công cụ toàn diện cho người sáng tạo nội dung, doanh nghiệp và nhà phát triển, bao gồm avatar nói chuyện, lồng tiếng YouTube và tích hợp API.
SIREN
SIREN là một nền tảng âm thanh AI tất cả trong một, được tăng tốc bằng GPU. Nó …
SIREN là một nền tảng âm thanh AI tất cả trong một, được tăng tốc bằng GPU. Nó cung cấp tính năng phiên âm thanh chính xác cao, chuyển văn bản thành giọng nói tự nhiên với hơn 420 giọng nói, lồng tiếng video liền mạch bằng hơn 100 ngôn ngữ và phụ đề phát trực tiếp theo thời gian thực. Được thiết kế cho người sáng tạo, nhà tiếp thị và doanh nghiệp, SIREN đơn giản hóa các tác vụ âm thanh phức tạp thành một quy trình làm việc duy nhất, hiệu quả.
SpeechText.AI
SpeechText.AI là một dịch vụ phiên âm tiên tiến do AI cung cấp, tự động chuyển đổi các …
SpeechText.AI là một dịch vụ phiên âm tiên tiến do AI cung cấp, tự động chuyển đổi các tệp âm thanh và video thành văn bản chính xác. Nó hỗ trợ hơn 30 ngôn ngữ, có tính năng nhận dạng người nói và tạo phụ đề (tệp SRT). Lý tưởng cho các nhà sáng tạo nội dung, nhà giáo dục và doanh nghiệp muốn nâng cao khả năng tiếp cận và hiệu quả quy trình làm việc.
SpeechGen
SpeechGen là một công cụ AI mạnh mẽ để tạo giọng đọc chuyển văn bản thành giọng nói …
SpeechGen là một công cụ AI mạnh mẽ để tạo giọng đọc chuyển văn bản thành giọng nói (TTS) chân thực và chuyển mã tệp video/âm thanh sang văn bản. Nó cung cấp hơn 1000 giọng nói tự nhiên bằng hơn 150 ngôn ngữ, các tùy chọn tùy chỉnh phong phú và mô hình định giá trả tiền theo mức sử dụng độc đáo. Lý tưởng cho người sáng tạo nội dung, nhà tiếp thị và nhà phát triển, nó hỗ trợ sử dụng thương mại và tích hợp liền mạch với nhiều nền tảng khác nhau.
WhisperUI Danh mục
WhisperUI Thẻ
WhisperUI Công cụ AI
WhisperUI Tính năng nhúng
Chỉ cần sao chép mã nhúng bên dưới, dán huy hiệu đẹp mắt vào blog, bài viết hoặc trang web chính thức của ứng dụng để hướng lưu lượng truy cập trực tiếp đến trang chi tiết của công cụ này, giúp nhanh chóng tăng độ hiển thị và số lượng người dùng!

Chưa có bình luận nào, hãy là người đầu tiên bình luận!