ezML
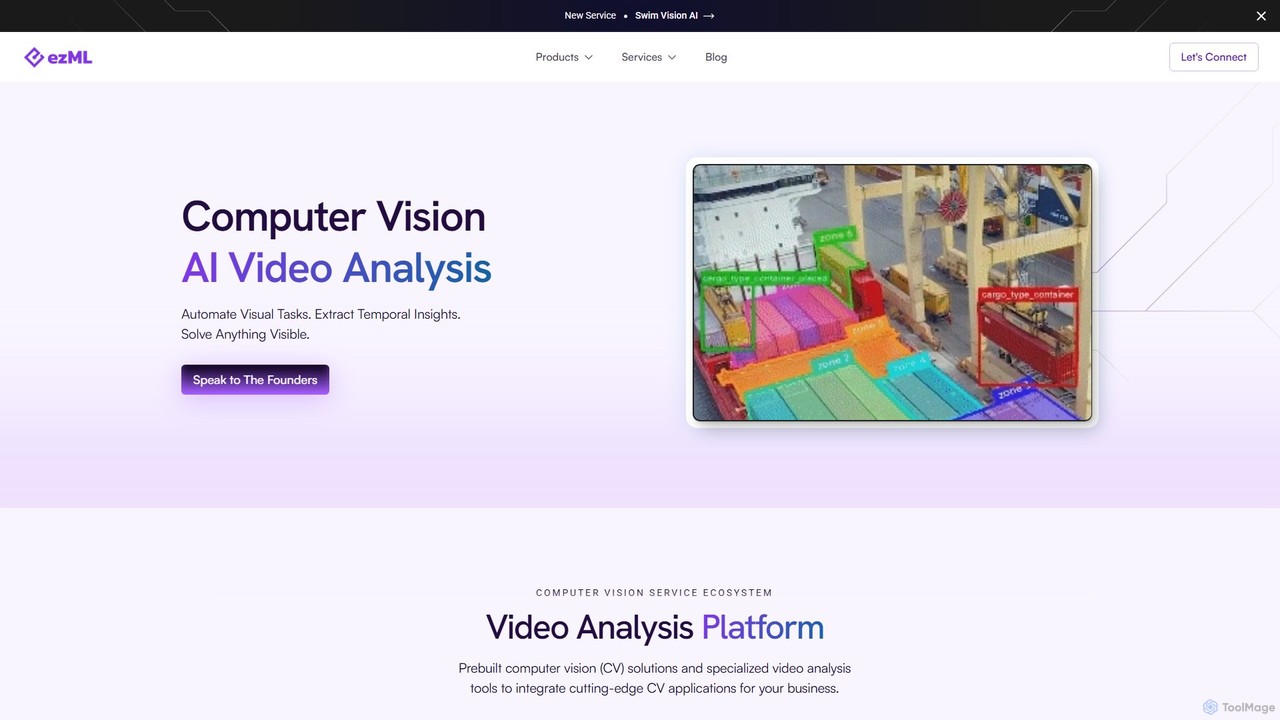
ezML 是一个企业级计算机视觉平台,专注于高级视频分析。它提供一套完整的工具,包括预构建模型、多模态搜索、合成数据生成和定制化计算机视觉解决方案。ezML 尤其擅长体育分析,例如其 Swim Vision AI,可帮助企业自动化视觉任务,从视频数据中提取深度洞察,并部署高性能、可扩展的计算机视觉应用。
ezML 是一个企业级计算机视觉平台,专注于高级视频分析。它提供一套完整的工具,包括预构建模型、多模态搜索、合成数据生成和定制化计算机视觉解决方案。ezML 尤其擅长体育分析,例如其 Swim Vision AI,可帮助企业自动化视觉任务,从视频数据中提取深度洞察,并部署高性能、可扩展的计算机视觉应用。
关于 数据生成
数据生成工具是一类利用人工智能技术创建全新合成数据集的解决方案。这类工具利用先进算法,常包括生成对抗网络(GANs)或变分自编码器(VAEs),生成与真实世界数据统计特性和模式高度相似的新数据。它们对于解决数据稀缺、增强隐私保护以及为机器学习模型训练和测试生成多样化、无偏见的数据集至关重要。通过模拟复杂数据分布,这些工具无需完全依赖敏感或有限的真实数据,即可实现稳健的开发。
核心功能
- 合成数据创建:生成逼真且统计学上相似的数据点,涵盖图像、文本或表格数据等多种模态。
- 隐私保护:创建既保留分析价值又能匿名化或保护敏感信息的合成数据。
- 数据增强:通过多样化变体扩展现有数据集,以提高模型的鲁棒性和泛化能力。
- 偏见缓解:生成平衡的数据集,减少真实数据中固有的偏见,从而构建更公平的AI模型。
- 可定制参数:提供控制选项,用于指定数据的特征、数量、分布和特定生成场景。
适用场景
数据生成工具被机器学习工程师、数据科学家和软件测试人员广泛采用。它们对于在数据稀缺领域训练强大的AI模型、在不损害隐私的情况下为应用程序创建逼真的测试数据,以及在医疗、金融等受监管行业中生成符合合规要求的匿名数据集至关重要。
选择要点
选择数据生成工具时,需考虑所需的数据类型和保真度,确保其能为您的用例生成足够逼真的数据。评估其针对敏感信息的隐私和安全功能,并衡量其生成大量数据的可扩展性和性能。最后,检查其定制选项,以控制数据特征和特定场景。
数据生成应用场景
生成用于AI模型训练的合成图像数据
机器学习工程师需要大量多样化的图像数据来训练计算机视觉模型,但真实数据收集成本高昂且可能受隐私限制。数据生成工具可以根据少量真实图像或特定描述,自动生成数百万张具有不同背景、光照、姿态和特征的合成图像。这不仅解决了数据稀缺问题,还通过引入多样性提高了模型在实际应用中的泛化能力和鲁棒性,显著加速了模型开发周期。
创建符合隐私法规的客户交易测试数据
金融机构在开发新产品或测试系统时,需要大量的客户交易数据进行功能和性能验证。然而,使用真实的客户数据存在严格的隐私合规风险。数据生成工具能够根据现有交易数据的统计模式,生成具有相同结构和特征的完全匿名的合成交易数据。这使得开发团队可以在安全合规的环境中进行全面的测试,避免了数据泄露风险,同时确保了测试的有效性。
自动化生成软件测试用的用户行为数据
软件测试人员在进行用户界面(UI)和用户体验(UX)测试时,需要模拟真实用户在应用中的各种交互行为。手动创建这些复杂的行为路径既耗时又难以覆盖所有边缘情况。数据生成工具可以根据预设的用户行为模式或历史日志,自动生成模拟用户点击、输入、导航等一系列操作的合成数据。这极大地提高了测试覆盖率和效率,帮助发现潜在的bug和性能瓶颈。
扩充小语种文本数据集以提升NLP模型性能
自然语言处理(NLP)模型在小语种或特定领域(如法律、医学)往往面临数据量不足的问题,导致模型性能不佳。内容创作者或AI研究人员可以利用数据生成工具,基于少量种子文本和语言规则,生成大量语法正确、语义连贯的合成文本数据。这些数据可以用于预训练或微调NLP模型,有效缓解数据稀缺性,显著提升翻译、情感分析、问答系统等任务在小语种环境下的准确性。
为自动驾驶系统生成多样化的传感器模拟数据
自动驾驶汽车的开发需要海量的传感器数据(如雷达、激光雷达、摄像头)来训练感知和决策模型。真实世界的数据收集成本极高且难以覆盖所有极端或罕见场景。数据生成工具能够模拟复杂的交通环境、天气条件和障碍物,生成逼真的合成传感器数据。这使得工程师能够在虚拟环境中安全、高效地测试和验证自动驾驶算法,加速了技术迭代和安全性提升。
填充缺失数据或平衡数据集以减少模型偏差
在许多实际数据集中,存在数据缺失或类别不平衡的问题,这可能导致训练出的AI模型产生偏差或性能下降。数据分析师和数据科学家可以利用数据生成工具,根据现有数据的分布模式,智能地填充缺失值或生成少数类别的合成数据。通过创建更完整、更平衡的数据集,这些工具能够有效减少模型训练中的偏差,提高模型的公平性和预测准确性,尤其在医疗诊断或金融风控等领域至关重要。