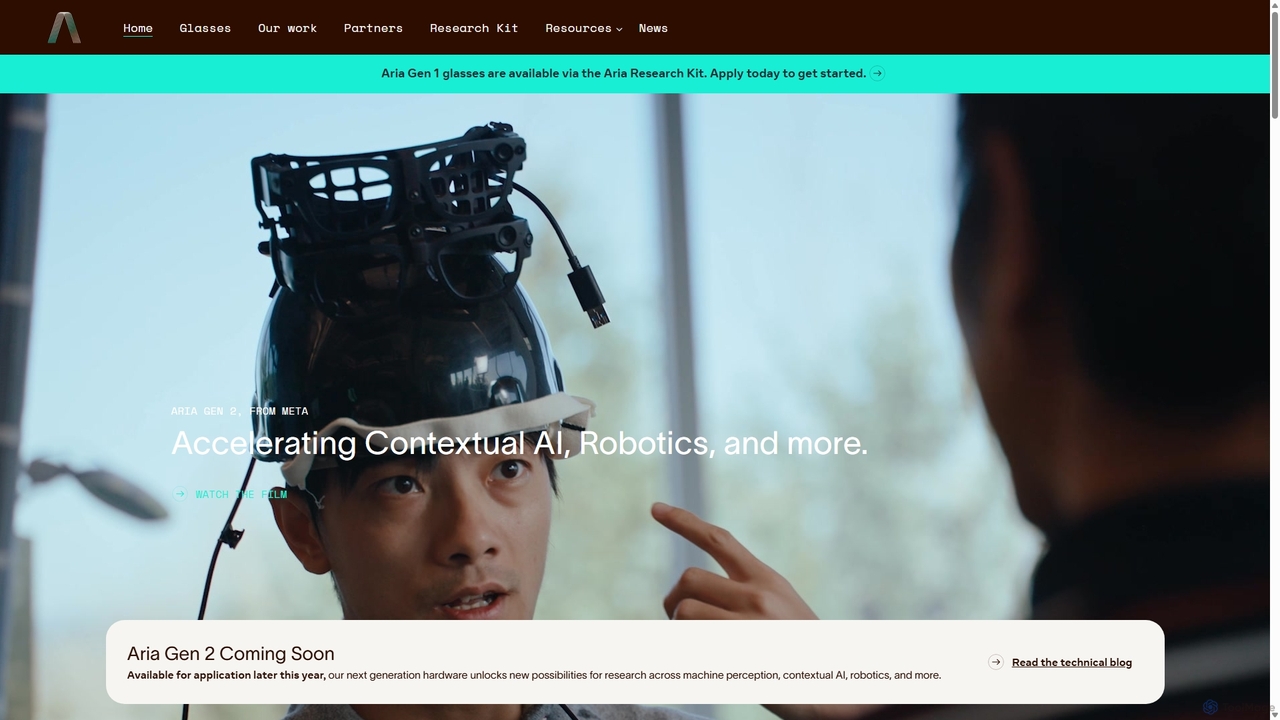
Project Aria
Project Aria是Meta发起的一项研究计划,旨在加速情境AI、增强现实(AR)和机器人技术的发展。它利用Aria Gen 2等先进的研究眼镜来捕捉第一人称视角数据,为研究人员提供一个包含硬件、开源数据集和开发工具的综合平台,以构建机器感知的未来。
Project Aria是Meta发起的一项研究计划,旨在加速情境AI、增强现实(AR)和机器人技术的发展。它利用Aria Gen 2等先进的研究眼镜来捕捉第一人称视角数据,为研究人员提供一个包含硬件、开源数据集和开发工具的综合平台,以构建机器感知的未来。

Allen Institute for AI (AI2)
艾伦人工智能研究所(AI2)是一家非营利性研究机构,致力于为共同利益构建突破性的人工智能。它专注于创建像OLMo这样真正开源的大型语言模型、全面的数据集以及专业的AI工具,以推动科学研究并应对气候科学、自然保护和医学等领域的重大全球挑战。
艾伦人工智能研究所(AI2)是一家非营利性研究机构,致力于为共同利益构建突破性的人工智能。它专注于创建像OLMo这样真正开源的大型语言模型、全面的数据集以及专业的AI工具,以推动科学研究并应对气候科学、自然保护和医学等领域的重大全球挑战。
关于 数据集
数据集是用于训练、验证和测试人工智能模型的精选数据集合。这些集合可包含图像、文本、音频或数值数据,为机器学习算法学习模式和做出预测提供了基础知识。获取高质量的相关数据集是开发有效AI应用(从计算机视觉系统到自然语言处理器)的关键第一步。它们是AI学习的“教科书”,直接影响最终模型的准确性和性能。
核心功能
- 结构化与标注数据:数据通常经过组织和注释(例如,为图片标注“猫”或“狗”),以支持监督学习。
- 多样化数据类型:包含图像、文本文档、音频剪辑和表格数据等多种格式,以支持不同的AI任务。
- 数据划分:通常预先划分为训练集、验证集和测试集,以确保正确的模型评估并防止过拟合。
- 全面的元数据:附有详细文档,说明数据来源、收集方法和许可信息。
适用场景
数据集在学术研究和商业AI开发中至关重要。数据科学家使用它们来训练定制的机器学习模型,研究人员用其对算法性能进行基准测试,开发者则用其为特定任务(如情感分析或对象检测)微调预训练模型。
选择要点
选择数据集时,需考虑其与特定问题的相关性及整体质量,包括标签的准确性和是否存在偏见。同时,评估数据集的规模,确保其足够大以便模型有效学习。最后,检查许可条款,确保其允许您的预期用途,无论是商业还是学术目的。
数据集应用场景
训练自定义图像识别模型
一位计算机视觉工程师需要构建一个模型来识别特定的制造缺陷。他们使用一个高质量、已标注的产品图像数据集,其中每张图片都被注释为“合格”或“不合格”,并附有缺陷类型。通过在这个数据集上训练他们的卷积神经网络(CNN),模型学会了区分无瑕疵产品和各种缺陷,从而自动化质量控制流程并提高检测准确率。
为客户支持微调语言模型
一家初创公司希望为其行业创建一个专门的聊天机器人。机器学习专家采用一个大型的预训练语言模型,并使用一个包含行业特定客户咨询及相应专家解答的精选数据集对其进行微调。这个过程使通用模型能够适应并理解专业术语,提供相关、准确的回复,从而显著改善客户支持体验。
对新的推荐算法进行基准测试
一个数据科学团队为电影推荐引擎开发了一种新算法。为了证明其有效性,他们使用像MovieLens这样的公开行业标准数据集对其进行测试。他们将自己算法的预测准确性(例如,预测用户评分的准确度)与已有的基准进行比较。这使得在部署新系统之前,能够进行客观的性能评估和验证。
开发声控智能家居设备
一位物联网开发者正在创造一个能响应语音命令的设备。他们利用一个大型音频数据集,其中包含来自不同口音、不同声学环境的多元化说话者数千小时的口头命令。该数据集用于训练一个语音转文本模型,确保设备在真实世界条件下能够可靠地理解用户的命令,如“开灯”或“设置一个计时器”。
构建医疗诊断AI助手
一家医学研究机构旨在创建一种AI工具,以协助放射科医生从MRI扫描中检测肿瘤。他们使用一个专门的、匿名的医学图像数据集,其中每次扫描都由专家放射科医生进行标记。在此数据集上训练模型有助于创建一个能够突出潜在问题区域的系统,作为第二意见,并可能提高诊断速度和准确性。
为市场研究进行情感分析
一位市场分析师希望了解公众对新产品发布的看法。他们使用一个包含社交媒体帖子和产品评论的数据集,其中每条内容都标注了情感(正面、负面、中性)。通过在这个数据上训练自然语言处理(NLP)模型,他们可以自动分析成千上万条新评论,从而提供关于客户满意度的实时洞察,并识别出需要改进的领域。