Geoguessr AI
一款AI驱动的教练工具,旨在帮助GeoGuessr玩家提升技能。用户可以上传游戏回合的截图,AI会分析护柱、路标和街景车元数据等视觉线索来识别位置。它专注于解释猜测背后的原因,将自己定位为一款学习工具,每天提供3次免费分析。
一款AI驱动的教练工具,旨在帮助GeoGuessr玩家提升技能。用户可以上传游戏回合的截图,AI会分析护柱、路标和街景车元数据等视觉线索来识别位置。它专注于解释猜测背后的原因,将自己定位为一款学习工具,每天提供3次免费分析。

Visionati
Visionati 是一个全面的人工智能视觉分析平台,可将图像和视频转化为可操作的见解。它提供了一套完整的工具包,包括图像字幕、智能标签、内容过滤以及面部和品牌识别等高级分析功能。通过单一 API 集成 OpenAI、Gemini 和 Claude 等顶级 AI 模型,Visionati 为开发人员、营销人员和内容创作者提供高度准确和深入的视觉理解。
Visionati 是一个全面的人工智能视觉分析平台,可将图像和视频转化为可操作的见解。它提供了一套完整的工具包,包括图像字幕、智能标签、内容过滤以及面部和品牌识别等高级分析功能。通过单一 API 集成 OpenAI、Gemini 和 Claude 等顶级 AI 模型,Visionati 为开发人员、营销人员和内容创作者提供高度准确和深入的视觉理解。
Image to Prompt AI
Image to Prompt AI 是一款先进的工具,它使用人工智能分析图像并生成详细、准确的文本描述或提示词。它专为SEO专家、内容创作者和AI艺术家设计,用于创建优化的替代文本、增强可访问性以及为AI艺术生成器反向工程提示词。该工具提供用户友好的界面和每日20个免费积分。
Image to Prompt AI 是一款先进的工具,它使用人工智能分析图像并生成详细、准确的文本描述或提示词。它专为SEO专家、内容创作者和AI艺术家设计,用于创建优化的替代文本、增强可访问性以及为AI艺术生成器反向工程提示词。该工具提供用户友好的界面和每日20个免费积分。

Image Describer
Image Describer 是一款多功能 AI 工具,可从任何图像生成详细描述、替代文本和创意内容。它能分析数据图表、创建食谱、生成营销文案,甚至为 Midjourney 等 AI 艺术生成器制作提示词。该工具专为营销人员、研究人员、艺术家和内容创作者设计,旨在解锁洞察力并提高效率。
Image Describer 是一款多功能 AI 工具,可从任何图像生成详细描述、替代文本和创意内容。它能分析数据图表、创建食谱、生成营销文案,甚至为 Midjourney 等 AI 艺术生成器制作提示词。该工具专为营销人员、研究人员、艺术家和内容创作者设计,旨在解锁洞察力并提高效率。
GreenEyes.AI
GreenEyes.AI通过即插即用的REST API为开发者提供一套计算机视觉工具。它专注于AI以图搜物、对象标注和基于内容的图像检索(CBIR)。该平台专为可扩展性和易用性而设计,使企业能够以低碳足迹将先进、可持续的图像识别技术集成到其应用中。
GreenEyes.AI通过即插即用的REST API为开发者提供一套计算机视觉工具。它专注于AI以图搜物、对象标注和基于内容的图像检索(CBIR)。该平台专为可扩展性和易用性而设计,使企业能够以低碳足迹将先进、可持续的图像识别技术集成到其应用中。

SceneXplain
SceneXplain 是 Jina AI 推出的一款先进的多模态AI工具,可为图像生成丰富、详细的描述,并为视频生成简洁的摘要。它超越了简单的字幕,能够创建叙事性、人性化的文本,回答有关视觉内容的问题(VQA),并生成结构化数据。它专为开发者、内容创作者和企业设计,旨在增强可访问性、自动化内容创作和改进数据分析。
SceneXplain 是 Jina AI 推出的一款先进的多模态AI工具,可为图像生成丰富、详细的描述,并为视频生成简洁的摘要。它超越了简单的字幕,能够创建叙事性、人性化的文本,回答有关视觉内容的问题(VQA),并生成结构化数据。它专为开发者、内容创作者和企业设计,旨在增强可访问性、自动化内容创作和改进数据分析。
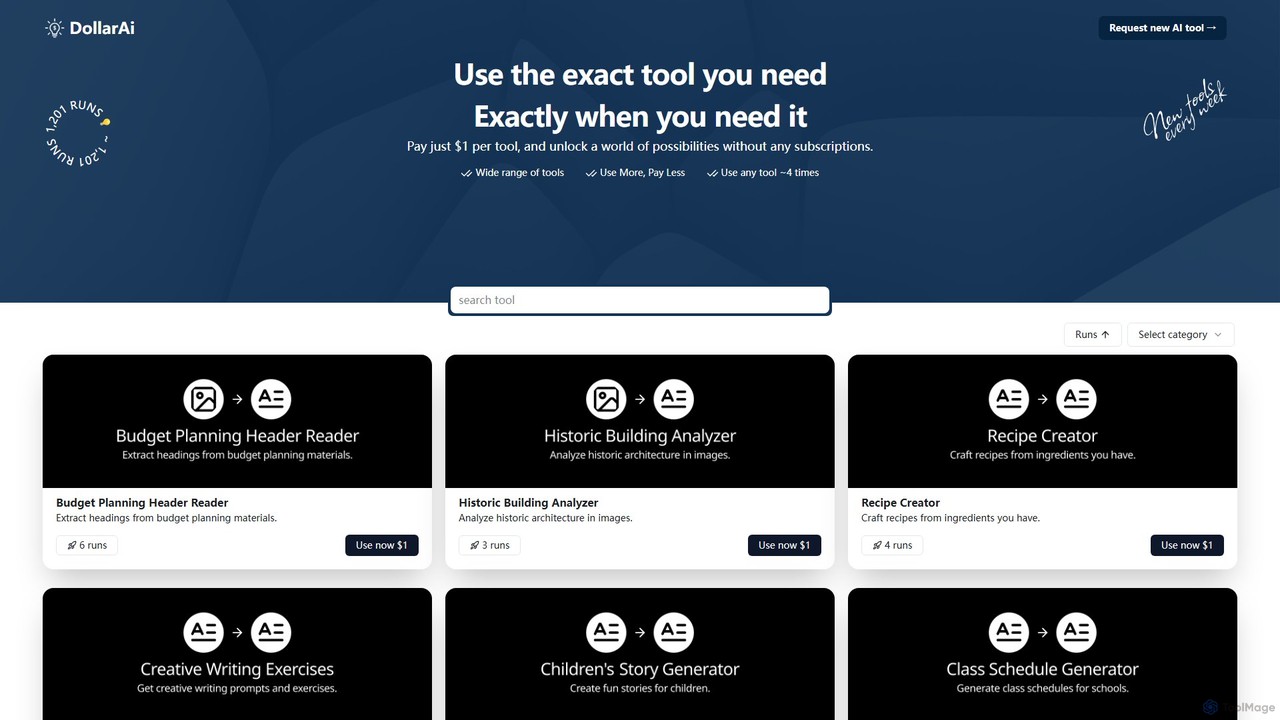
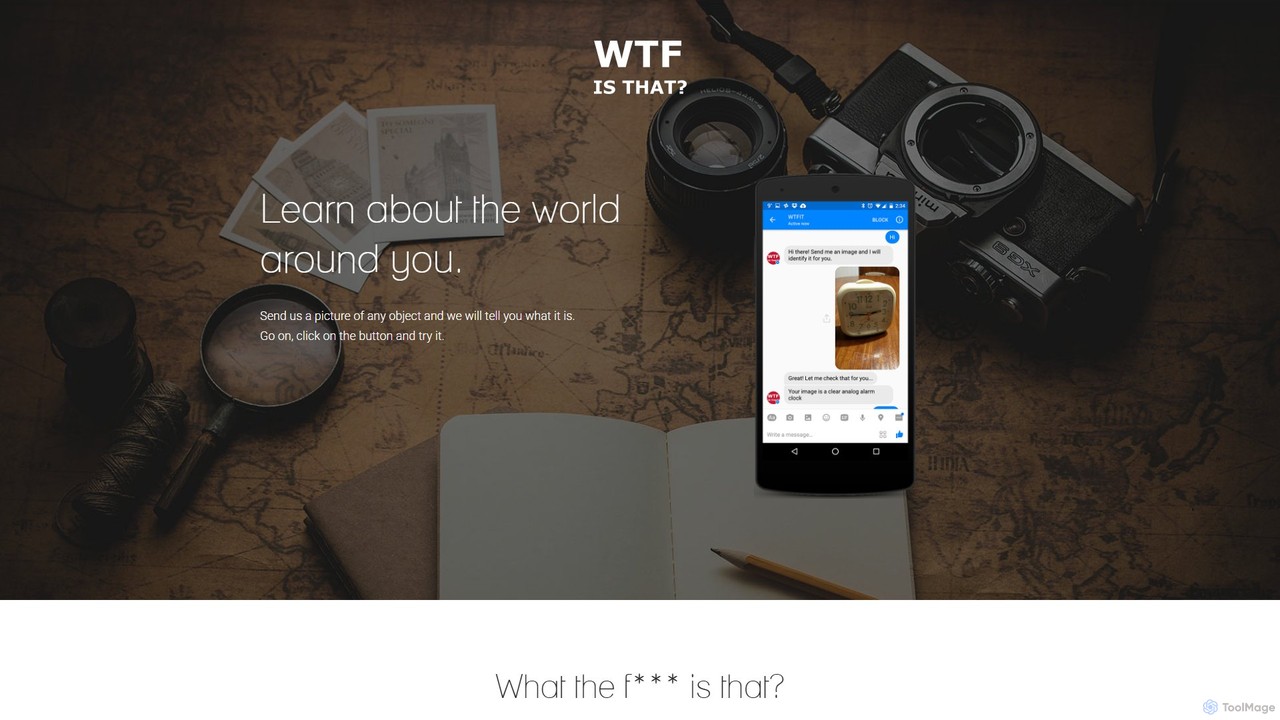
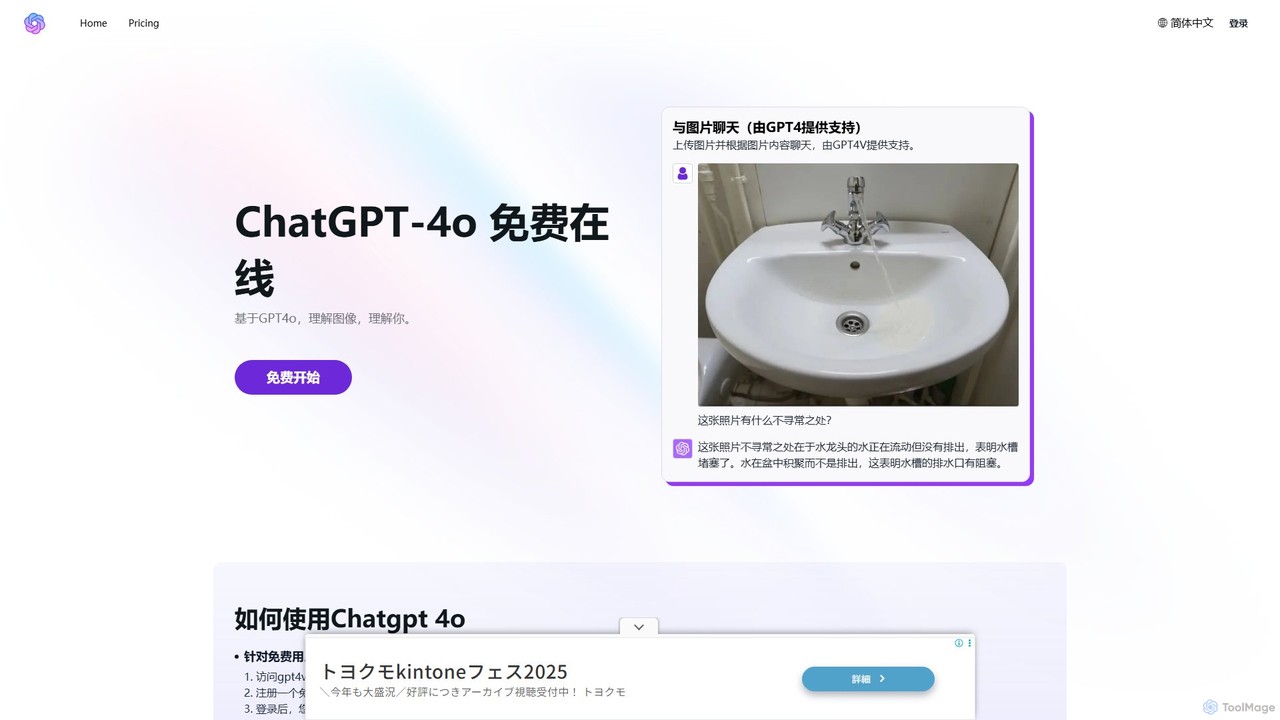
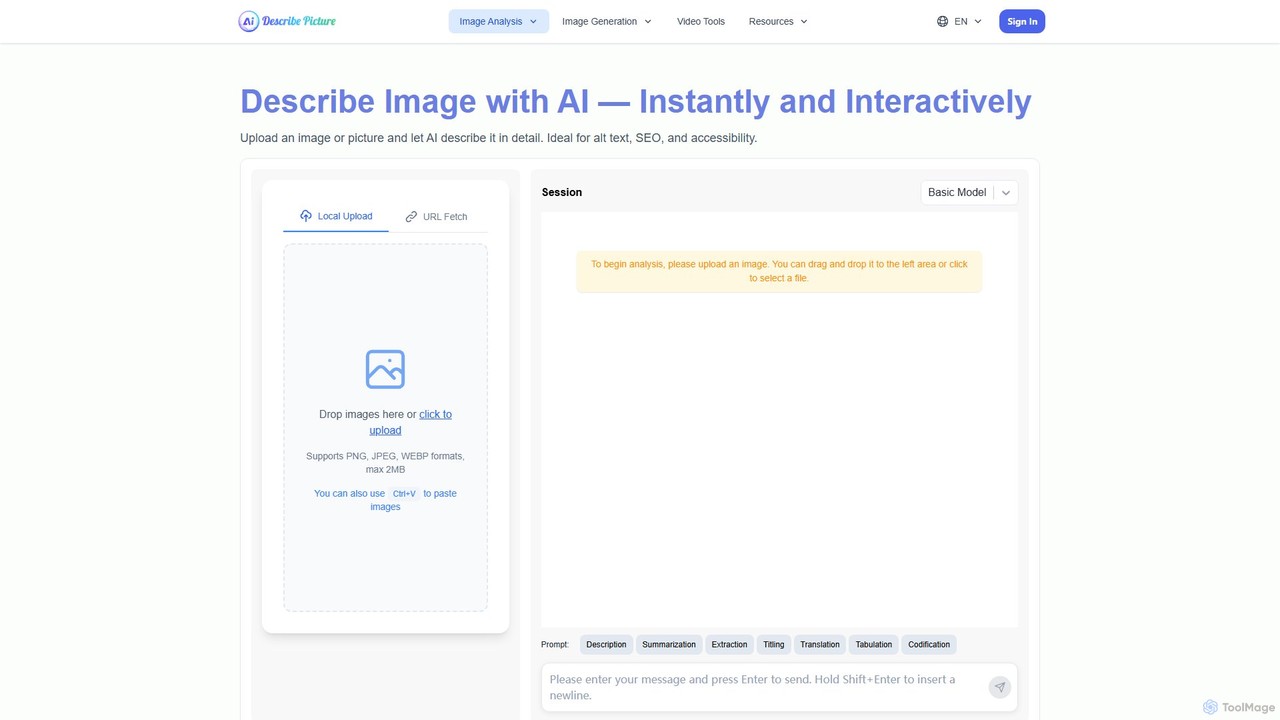
describepicture
describepicture 是一个多功能AI平台,可即时为图像和视频生成详细描述。它擅长为SEO和可访问性创建alt文本、从图像中提取文本(OCR)、将网页截图转换为代码(HTML/CSS/JS),以及将图像内容转换为Markdown。对于内容创作者、开发者和营销人员来说,它是一款集多种功能于一体的工具,可提高生产力并使数字内容更具包容性。
describepicture 是一个多功能AI平台,可即时为图像和视频生成详细描述。它擅长为SEO和可访问性创建alt文本、从图像中提取文本(OCR)、将网页截图转换为代码(HTML/CSS/JS),以及将图像内容转换为Markdown。对于内容创作者、开发者和营销人员来说,它是一款集多种功能于一体的工具,可提高生产力并使数字内容更具包容性。
moondream2
moondream2 是一款专为边缘设备设计的高效、轻量级开源视觉语言模型(VLM)。它擅长生成图像描述、理解复杂文档和执行视觉问答,是资源有限的移动应用和物联网场景的理想选择。
moondream2 是一款专为边缘设备设计的高效、轻量级开源视觉语言模型(VLM)。它擅长生成图像描述、理解复杂文档和执行视觉问答,是资源有限的移动应用和物联网场景的理想选择。
关于 图像识别
图像识别工具是一类AI应用,旨在识别和解读数字图像中的物体、人物、文本及行为。这类工具利用深度学习模型,特别是卷积神经网络(CNNs),来分析像素数据并提取有效信息。其核心价值在于自动化视觉数据分析流程,使系统能够像人类一样“看见”并理解世界。作为图像工具大类中的关键组成部分,它专注于分析与理解,区别于图像生成或编辑工具。
核心功能
- 物体检测:在图像中识别并定位特定物体,通常会用边界框标出。
- 人脸识别:检测并验证人脸,通过与数据库比对进行身份识别或认证。
- 光学字符识别(OCR):从图像中提取印刷或手写文本,并将其转换为机器可读的文本数据。
- 场景理解:提供对整个图像的上下文描述,包括活动、环境和物体间的关系。
- 品牌与Logo检测:扫描图像和视频以发现并识别企业Logo,用于品牌监控。
适用场景
图像识别广泛应用于各行各业。在零售业,它通过追踪货架商品,为自动结账系统和库存管理提供支持。医疗保健专业人员用它分析X光片和MRI等医学影像,以辅助诊断。在汽车领域,它是自动驾驶汽车感知行人、交通标志和其他车辆的基础。安防系统也依赖它进行监控和访问控制。
选择要点
选择图像识别工具时,需考虑几个关键因素。评估模型针对您特定用例(如医疗与零售物体)的准确率和精确度。考量API的速度、可扩展性和可靠性,尤其对于实时应用。检查预训练模型的覆盖范围以及使用自有数据训练自定义模型的便捷性。最后,比较不同的定价模式,如按API调用次数、订阅等级或处理时间计费。
图像识别应用场景
电商产品自动化标签
一位负责数千种商品目录的电商经理,使用图像识别工具来简化产品上架流程。当上传新产品照片时,AI会自动分析每张图片,识别出“长袖衬衫”、“蓝色”、“棉质”和“花卉图案”等属性。这些属性随后被转换为可搜索的标签。这个过程省去了数小时的人工数据录入,减少了人为错误,并提升了客户对产品的可发现性,从而带来更好的搜索结果和可能更高的转化率。
社交媒体内容审核
一家社交媒体公司的信任与安全团队部署了图像识别API,以自动扫描用户上传的内容。该系统经过训练,能够实时检测并标记含有违禁内容的图片,如暴力、仇恨符号或露骨材料。当检测到潜在违规时,图片会被发送给人工审核员进行最终审查。这种自动化的初审大大减轻了审核员的工作量和接触有害内容的频率,同时加快了删除违规帖子的速度,以维护一个更安全的网络环境。
使用OCR数字化文档
一家律师事务所需要处理大量的纸质合同和案件档案。他们使用OCR工具代替了手动转录。行政助理扫描文件后,软件的图像识别引擎会分析扫描图像,识别文本,并将其转换为可编辑和可搜索的数字格式,如Word或PDF。这使得律师能够快速在数千份文件中搜索特定条款、姓名或日期,从而节省大量时间,并提高法律研究和案件准备的效率。
辅助放射科医学诊断
一位放射科医生使用AI驱动的图像识别工具来分析MRI或CT扫描等医学影像。该AI经过数百万张带注释的医学图像训练,能够检测并高亮显示人眼可能忽略的细微异常、肿瘤或骨折,尤其是在高工作量的情况下。该工具并非取代放射科医生,而是作为第二双眼睛,提供量化数据并突出显示关注区域。这提高了诊断的准确性,加快了审查过程,并有助于疾病的早期发现。
零售货架监控与分析
一家大型零售连锁店在其过道安装了连接到图像识别系统的摄像头。该系统持续分析视频流以监控货架库存。它能识别特定产品何时缺货,检测错放的商品,并验证促销陈列是否设置正确。当检测到问题时,例如货架空了,系统会自动向店员的移动设备发送警报,以便立即补货。这确保了产品的可得性,改善了顾客的购物体验,并提供了关于产品流动性的宝贵数据。
社交媒体品牌监控
一家全球饮料公司的营销分析师使用图像识别工具来追踪其品牌在网络上的曝光度。该工具每天扫描社交媒体平台上发布的数百万张公开图片,搜索该公司的Logo。这使得分析师能够识别包含其产品的用户生成内容,监控品牌的呈现方式,并发现潜在的影响者营销机会。与基于文本的搜索不同,这种方法能捕捉到未明确写出品牌名称的视觉提及,从而提供更全面的品牌知名度和参与度视图。