
Cleora 概览
Cleora 是由 Synerise.com 团队开发的一款通用开源模型,专为从复杂的异构关系数据中进行高效、可扩展的实体嵌入学习而设计。它擅长将实体及其交互——例如购物车中的商品、社交网络上的用户或生物系统中的蛋白质——转换为有意义的数值向量。这些向量(即嵌入)捕捉了潜在的关系和相似性,使其在下游的机器学习任务中具有极高的价值。
Cleora 的核心采用高性能的 Rust 语言构建,并通过用户友好的 Python 包 (pycleora) 提供接口,其处理速度比 DeepWalk 或 PyTorch-BigGraph 等传统方法快几个数量级。它基于从数据中导出的马尔可夫转移矩阵进行迭代随机投影的原理运行,这种方法避免了负采样带来的噪声和效率低下的问题。这使得它能够在单台机器上处理超大规模的图和超图,这对于现实世界的应用是一个显著的优势。
如何使用 Cleora
对于熟悉 Python 的开发人员和数据科学家来说,使用 Cleora 非常简单。该过程通常包括以下步骤:
- 安装:直接使用 pip 安装 Python 包:
pip install pycleora。 - 数据准备:将您的数据构建为一系列超边。超边是一组共同出现的实体。例如,输入文件中的一行可以代表单次交易中购买的所有商品,用空格分隔。这可以从 pandas DataFrame 或任何 Python 迭代器中准备。
- 矩阵创建:使用
SparseMatrix.from_iterator()函数将您准备好的数据转换为稀疏的马尔可夫转移矩阵。该矩阵代表了您的超图内的关系。 - 嵌入初始化:您可以让 Cleora 确定性地初始化嵌入向量,也可以提供您自己的初始向量。这一独特功能允许您将外部信息(例如来自文本的嵌入,如 Sentence-BERT,或图像的嵌入,如 ViT)融入图结构中。
- 传播:使用
mat.left_markov_propagate(embeddings)执行几次马尔可夫传播迭代。通常,3 到 7 次迭代就足够了。较少的迭代捕捉直接的共现关系,而更多的迭代则捕捉更深层次的上下文相似性。 - 归一化:对生成的嵌入向量进行归一化,通常使用 L2 范数,以确保它们位于一个超球面上。这使得它们可以使用余弦相似度或点积进行比较。
- 使用:最终归一化的向量就是您的实体嵌入,可用于推荐、分类、聚类或相似性搜索任务。
Cleora 的核心功能
- 极致性能:采用 Rust 编写,并针对并发和缓存一致性进行了优化,使其速度极快。
- 可扩展性:能够在单台普通机器上嵌入拥有数十亿条边的超大规模图和超图。
- 归纳式学习:能够即时为新的、前所未见的实体生成嵌入,而无需重新训练整个模型,有效解决了冷启动问题。
- 稳定与确定性:与 Node2vec 等方法不同,Cleora 对相同的输入数据在多次运行中产生相同的嵌入,确保了可复现性和稳定性。
- 超图支持:原生处理超图(例如,购物篮中的商品,群组中的用户),这比简单的成对图分解功能更强大。
- Python 集成:提供无缝的 Python API (pycleora),并与 NumPy 深度集成,便于在数据科学工作流中使用。
- 自定义初始化:允许用户使用来自其他来源(如文本、图像模型)的向量来初始化嵌入,从而实现多模态分析。
Cleora 的使用案例
Cleora 的多功能性使其适用于各行各业的广泛应用:
- 电子商务:为推荐系统(例如,“购买此商品的顾客还购买了...”)、商品相似性和购物篮分析创建强大的商品嵌入。
- 社交网络分析:嵌入用户和内容以识别社区、预测连接和推荐内容。
- 生物信息学:通过基于在生物通路中共现的蛋白质、药物和基因进行嵌入来分析它们之间的相互作用。
- 金融服务:通过识别交易图中的异常模式来检测欺诈活动。
- 学术研究:分析合著网络以发现研究社区和有影响力的作者。
Cleora 的优势特点
Cleora 因其几个关键优势而在其他嵌入框架中脱颖而出:
- 无与伦比的速度:它比许多流行的替代方案(例如,在基准测试中比 DeepWalk 快 190 倍以上)要快得多。
- 生产就绪:其稳定性、归纳能力和实时更新能力使其非常适合部署在实时生产环境中。
- 高质量嵌入:在完整的转移矩阵上进行显式随机游走且无需负采样的方法,可以产生更高质量和更准确的嵌入。
- 资源效率:它被设计为在单台机器上高效运行,减少了对昂贵的分布式计算集群的需求。
- 简单与灵活:该模型在概念上简单而强大,在数据输入和嵌入初始化方面提供了灵活性。
定价和计划
Cleora 是一个在 MIT 许可下发布的完全开源的项目。这意味着它对于学术和商业用途都是完全免费的。没有付费计划或隐藏费用。源代码在 GitHub 上公开提供,任何人都可以使用、检查或贡献。
Cleora 评论 (0)
登录后即可发表评论
立即登录Cleora 替代方案
查看全部
Streamlit
Streamlit 是一个开源 Python 框架,使开发人员和数据科学家能够在几分钟内为机器学习和数据科学构建和共享精美的自定义 Web 应用。Streamlit Community Cloud 提供一个免费平台,用于部署、管理和与世界分享这些公共应用程序,营造一个协作创新的环境。
Streamlit 是一个开源 Python 框架,使开发人员和数据科学家能够在几分钟内为机器学习和数据科学构建和共享精美的自定义 Web 应用。Streamlit Community Cloud 提供一个免费平台,用于部署、管理和与世界分享这些公共应用程序,营造一个协作创新的环境。
marimo
marimo 是一款面向现代数据科学和人工智能的开源响应式 Python 笔记本。它提供了一个可复现、Git 友好且交互式的环境,其中笔记本即是纯 Python 脚本。其功能包括内置的 AI 辅助、SQL 单元格以及将笔记本作为 Web 应用共享的能力,从而简化了从实验到生产的工作流程。
marimo 是一款面向现代数据科学和人工智能的开源响应式 Python 笔记本。它提供了一个可复现、Git 友好且交互式的环境,其中笔记本即是纯 Python 脚本。其功能包括内置的 AI 辅助、SQL 单元格以及将笔记本作为 Web 应用共享的能力,从而简化了从实验到生产的工作流程。
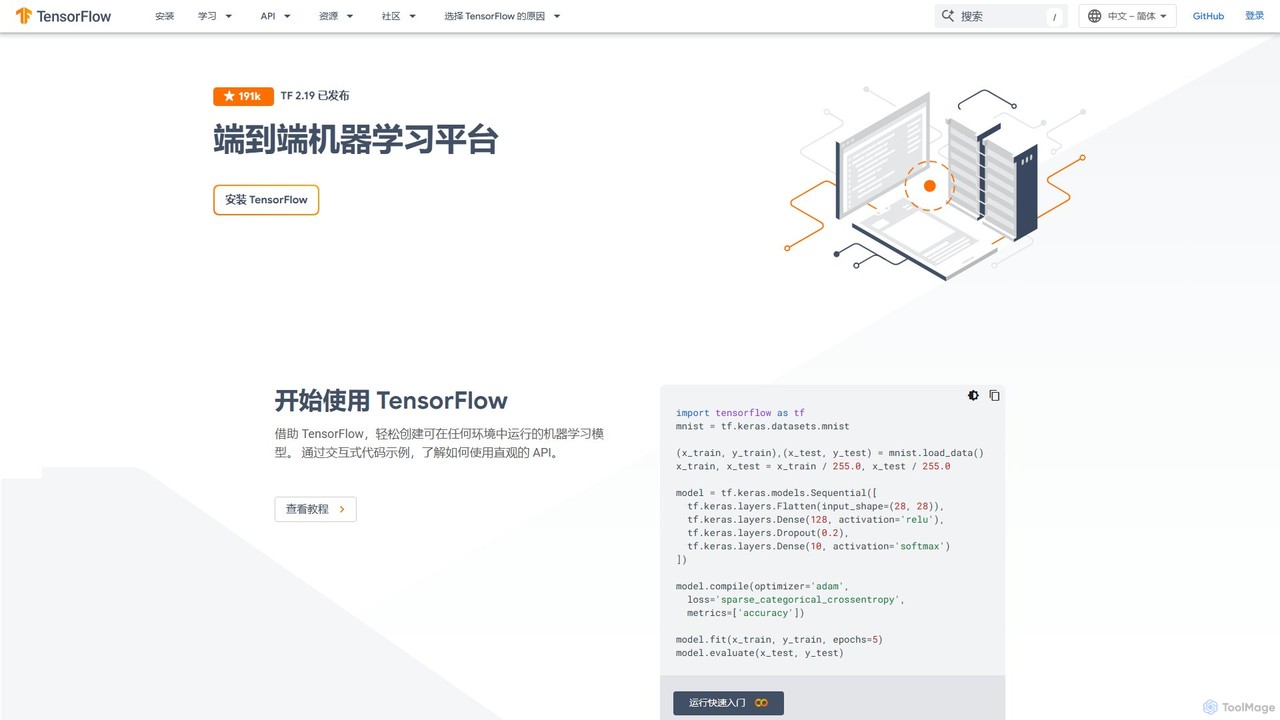
TensorFlow
TensorFlow 是由谷歌开发的端到端开源机器学习平台。它提供了一个全面、灵活的工具、库和社区资源生态系统,让研究人员和开发人员能够构建和部署由机器学习驱动的应用程序。从初学者到专家,TensorFlow 提供了用于轻松构建模型的直观高级 API 和用于高级研究的强大低级 API,支持在服务器、边缘设备和浏览器上进行部署。
TensorFlow 是由谷歌开发的端到端开源机器学习平台。它提供了一个全面、灵活的工具、库和社区资源生态系统,让研究人员和开发人员能够构建和部署由机器学习驱动的应用程序。从初学者到专家,TensorFlow 提供了用于轻松构建模型的直观高级 API 和用于高级研究的强大低级 API,支持在服务器、边缘设备和浏览器上进行部署。
Cleora AI工具对比
Cleora 嵌入功能
只需复制下方嵌入代码,将精美徽章贴到您的博客、文章或应用官网,即可把流量直接引导到本工具详情页,快速提升曝光与用户量!

还没有评论,成为第一个评论者吧!