Geoguessr AI
一款AI驅動的教練工具,旨在幫助GeoGuessr玩家提升技能。用戶可上傳遊戲回合的截圖,AI會分析護柱、路標和街景車元數據等視覺線索來識別位置。它專注於解釋猜測背後的原因,將自己定位為一款學習工具,每天提供3次免費分析。
一款AI驅動的教練工具,旨在幫助GeoGuessr玩家提升技能。用戶可上傳遊戲回合的截圖,AI會分析護柱、路標和街景車元數據等視覺線索來識別位置。它專注於解釋猜測背後的原因,將自己定位為一款學習工具,每天提供3次免費分析。

Visionati
Visionati 是一個全面的人工智慧視覺分析平台,可將圖像和影片轉化為可行的洞察。它提供了一套完整的工具包,包括圖像字幕、智慧標籤、內容過濾以及臉部和品牌識別等進階分析功能。透過單一 API 整合 OpenAI、Gemini 和 Claude 等頂級 AI 模型,Visionati 為開發人員、行銷人員和內容創作者提供高度準確和深入的視覺理解。
Visionati 是一個全面的人工智慧視覺分析平台,可將圖像和影片轉化為可行的洞察。它提供了一套完整的工具包,包括圖像字幕、智慧標籤、內容過濾以及臉部和品牌識別等進階分析功能。透過單一 API 整合 OpenAI、Gemini 和 Claude 等頂級 AI 模型,Visionati 為開發人員、行銷人員和內容創作者提供高度準確和深入的視覺理解。
Image to Prompt AI
Image to Prompt AI 是一款先進的工具,它使用人工智慧分析圖像並生成詳細、準確的文字描述或提示詞。它專為SEO專家、內容創作者和AI藝術家設計,用於創建優化的替代文字、增強無障礙性以及為AI藝術生成器反向工程提示詞。該工具提供使用者友好的介面和每日20個免費積分。
Image to Prompt AI 是一款先進的工具,它使用人工智慧分析圖像並生成詳細、準確的文字描述或提示詞。它專為SEO專家、內容創作者和AI藝術家設計,用於創建優化的替代文字、增強無障礙性以及為AI藝術生成器反向工程提示詞。該工具提供使用者友好的介面和每日20個免費積分。

Image Describer
Image Describer 是一款多功能 AI 工具,可從任何圖像生成詳細描述、替代文本和創意內容。它能分析數據圖表、創建食譜、生成行銷文案,甚至為 Midjourney 等 AI 藝術生成器製作提示詞。該工具專為行銷人員、研究人員、藝術家和內容創作者設計,旨在解鎖洞察力並提高效率。
Image Describer 是一款多功能 AI 工具,可從任何圖像生成詳細描述、替代文本和創意內容。它能分析數據圖表、創建食譜、生成行銷文案,甚至為 Midjourney 等 AI 藝術生成器製作提示詞。該工具專為行銷人員、研究人員、藝術家和內容創作者設計,旨在解鎖洞察力並提高效率。
GreenEyes.AI
GreenEyes.AI透過即插即用的REST API為開發者提供一套電腦視覺工具。它專注於AI以圖搜物、物件標註和基於內容的圖像檢索(CBIR)。該平台專為可擴展性和易用性而設計,使企業能夠以低碳足跡將先進、可持續的圖像識別技術整合到其應用程式中。
GreenEyes.AI透過即插即用的REST API為開發者提供一套電腦視覺工具。它專注於AI以圖搜物、物件標註和基於內容的圖像檢索(CBIR)。該平台專為可擴展性和易用性而設計,使企業能夠以低碳足跡將先進、可持續的圖像識別技術整合到其應用程式中。

SceneXplain
SceneXplain 是 Jina AI 推出的一款先進的多模態AI工具,可為圖像生成豐富、詳細的描述,並為影片生成簡潔的摘要。它超越了簡單的字幕,能夠創建敘事性、人性化的文本,回答有關視覺內容的問題(VQA),並生成結構化數據。它專為開發者、內容創作者和企業設計,旨在增強無障礙體驗、自動化內容創作和改進數據分析。
SceneXplain 是 Jina AI 推出的一款先進的多模態AI工具,可為圖像生成豐富、詳細的描述,並為影片生成簡潔的摘要。它超越了簡單的字幕,能夠創建敘事性、人性化的文本,回答有關視覺內容的問題(VQA),並生成結構化數據。它專為開發者、內容創作者和企業設計,旨在增強無障礙體驗、自動化內容創作和改進數據分析。
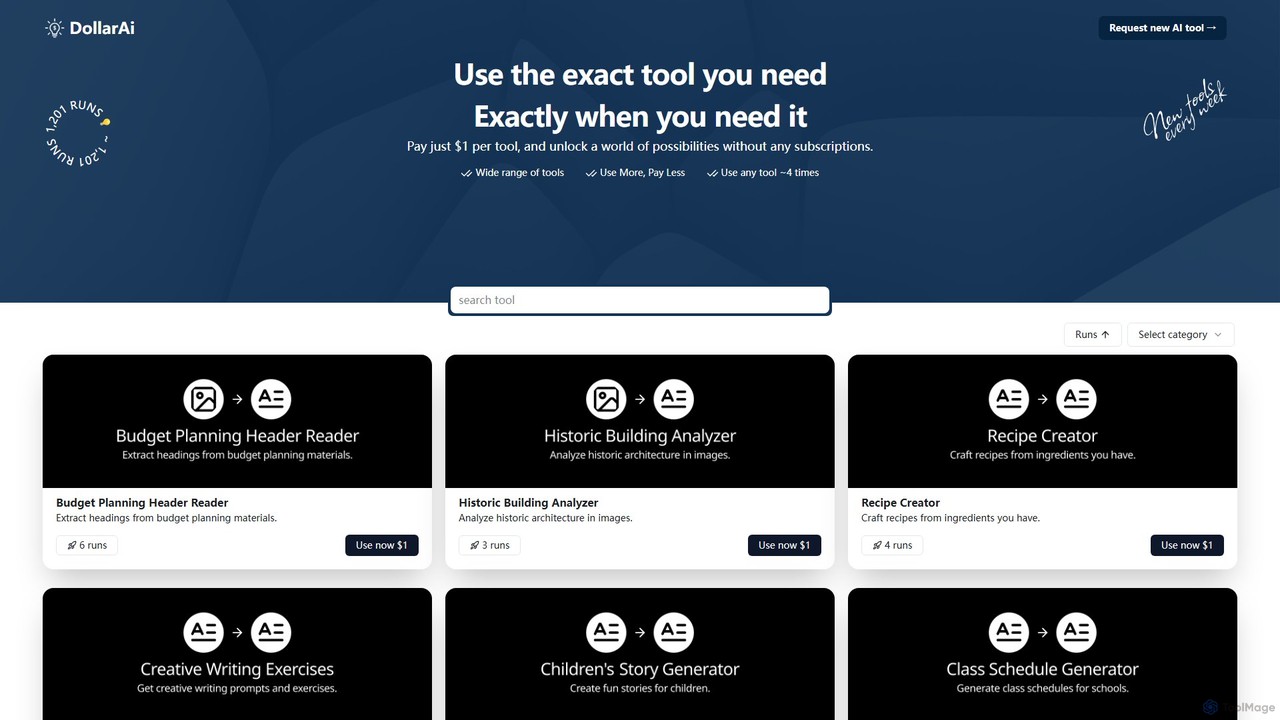
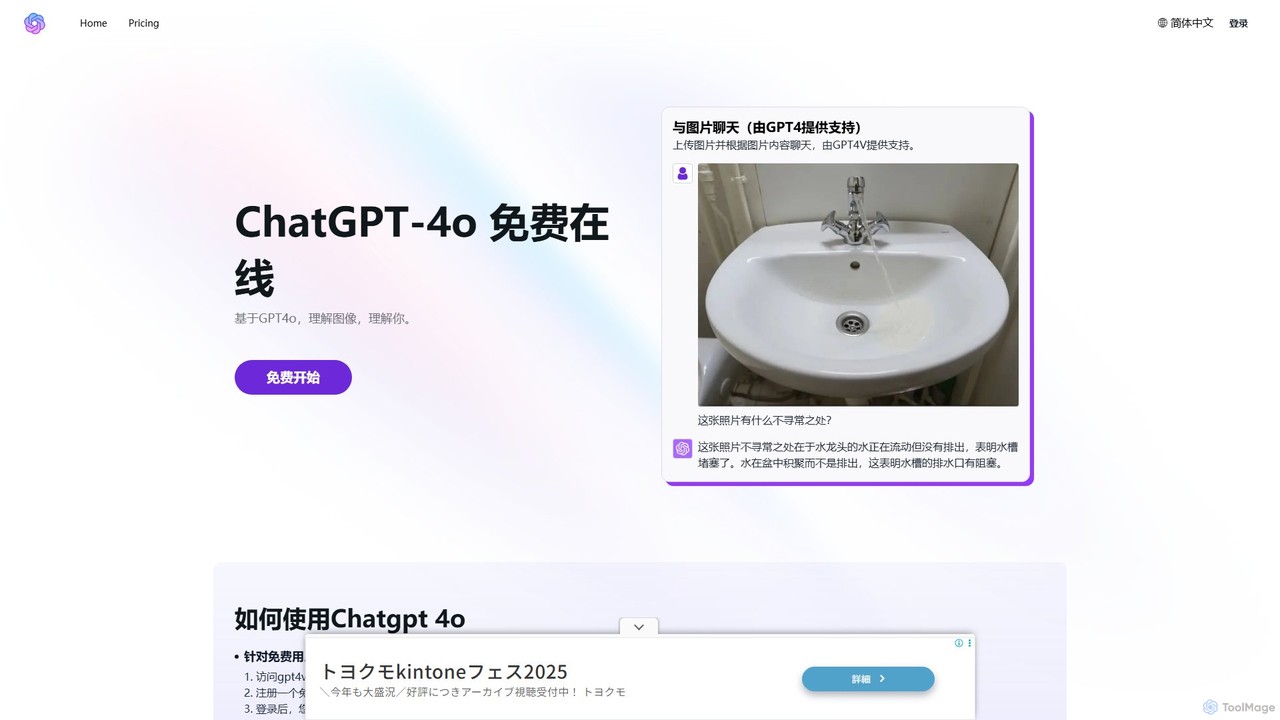
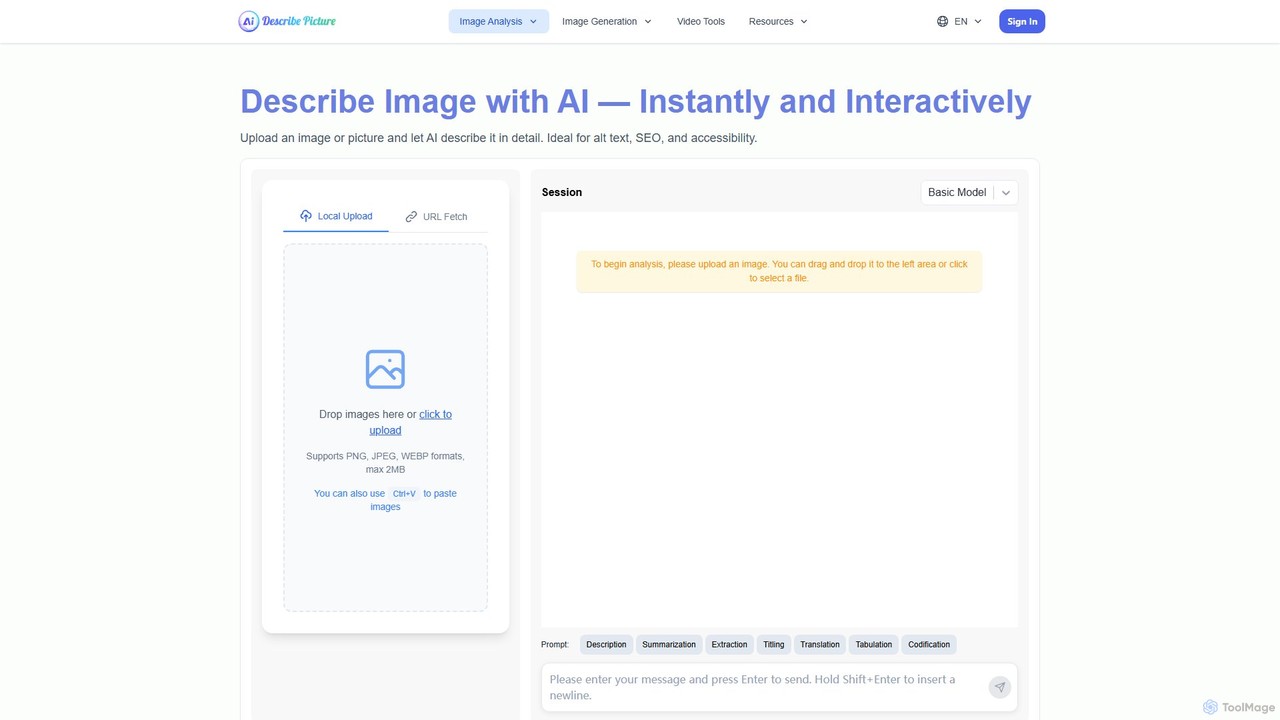
describepicture
describepicture 是一個多功能AI平台,可即時為圖像和影片生成詳細描述。它擅長為SEO和無障礙體驗創建alt替代文字、從圖像中提取文字(OCR)、將網頁截圖轉換為程式碼(HTML/CSS/JS),以及將圖像內容轉換為Markdown。對於內容創作者、開發者和行銷人員來說,它是一款集多種功能於一體的工具,可提高生產力並使數位內容更具包容性。
describepicture 是一個多功能AI平台,可即時為圖像和影片生成詳細描述。它擅長為SEO和無障礙體驗創建alt替代文字、從圖像中提取文字(OCR)、將網頁截圖轉換為程式碼(HTML/CSS/JS),以及將圖像內容轉換為Markdown。對於內容創作者、開發者和行銷人員來說,它是一款集多種功能於一體的工具,可提高生產力並使數位內容更具包容性。
moondream2
moondream2 是一款專為邊緣裝置設計的高效、輕量級開源視覺語言模型(VLM)。它擅長生成圖像描述、理解複雜文件和執行視覺問答,是資源有限的行動應用和物聯網場景的理想選擇。
moondream2 是一款專為邊緣裝置設計的高效、輕量級開源視覺語言模型(VLM)。它擅長生成圖像描述、理解複雜文件和執行視覺問答,是資源有限的行動應用和物聯網場景的理想選擇。
關於 圖像識別
圖像識別工具是一類AI應用,旨在識別和解讀數位影像中的物體、人物、文字及行為。這類工具利用深度學習模型,特別是卷積神經網路(CNNs),來分析像素數據並提取有效資訊。其核心價值在於自動化視覺數據分析流程,使系統能夠像人類一樣「看見」並理解世界。作為圖像工具大類中的關鍵組成部分,它專注於分析與理解,區別於圖像生成或編輯工具。
核心功能
- 物體偵測:在影像中識別並定位特定物體,通常會用邊界框標出。
- 人臉辨識:偵測並驗證人臉,透過與資料庫比對進行身份識別或認證。
- 光學字元辨識(OCR):從影像中提取印刷或手寫文字,並將其轉換為機器可讀的文字數據。
- 場景理解:提供對整個影像的上下文描述,包括活動、環境和物體間的關係。
- 品牌與Logo偵測:掃描影像和影片以發現並識別企業Logo,用於品牌監控。
適用場景
圖像識別廣泛應用於各行各業。在零售業,它透過追蹤貨架商品,為自動結帳系統和庫存管理提供支援。醫療保健專業人員用它分析X光片和MRI等醫學影像,以輔助診斷。在汽車領域,它是自動駕駛汽車感知行人、交通標誌和其他車輛的基礎。安防系統也依賴它進行監控和存取控制。
選擇要點
選擇圖像識別工具時,需考慮幾個關鍵因素。評估模型針對您特定用途(如醫療與零售物體)的準確率和精確度。考量API的速度、可擴展性和可靠性,尤其對於即時應用。檢查預訓練模型的覆蓋範圍以及使用自有數據訓練自訂模型的便利性。最後,比較不同的定價模式,如按API呼叫次數、訂閱等級或處理時間計費。
圖像識別應用場景
電商產品自動化標籤
一位負責數千種商品目錄的電商經理,使用圖像識別工具來簡化產品上架流程。當上傳新產品照片時,AI會自動分析每張圖片,識別出「長袖襯衫」、「藍色」、「棉質」和「花卉圖案」等屬性。這些屬性隨後被轉換為可搜尋的標籤。這個過程省去了數小時的人工數據錄入,減少了人為錯誤,並提升了客戶對產品的可發現性,從而帶來更好的搜尋結果和可能更高的轉換率。
社交媒體內容審核
一家社交媒體公司的信任與安全團隊部署了圖像識別API,以自動掃描用戶上傳的內容。該系統經過訓練,能夠即時偵測並標記含有違禁內容的圖片,如暴力、仇恨符號或露骨材料。當偵測到潛在違規時,圖片會被傳送給人工審核員進行最終審查。這種自動化的初審大大減輕了審核員的工作量和接觸有害內容的頻率,同時加快了刪除違規貼文的速度,以維護一個更安全的網路環境。
使用OCR數位化文件
一家律師事務所需要處理大量的紙本合約和案件檔案。他們使用OCR工具代替了手動轉錄。行政助理掃描文件後,軟體的圖像識別引擎會分析掃描影像,識別文字,並將其轉換為可編輯和可搜尋的數位格式,如Word或PDF。這使得律師能夠快速在數千份文件中搜尋特定條款、姓名或日期,從而節省大量時間,並提高法律研究和案件準備的效率。
輔助放射科醫學診斷
一位放射科醫生使用AI驅動的圖像識別工具來分析MRI或CT掃描等醫學影像。該AI經過數百萬張帶註釋的醫學影像訓練,能夠偵測並高亮顯示人眼可能忽略的細微異常、腫瘤或骨折,尤其是在高工作量的情況下。該工具並非取代放射科醫生,而是作為第二雙眼睛,提供量化數據並突顯關注區域。這提高了診斷的準確性,加快了審查過程,並有助於疾病的早期發現。
零售貨架監控與分析
一家大型零售連鎖店在其走道安裝了連接到圖像識別系統的攝影機。該系統持續分析視訊流以監控貨架庫存。它能識別特定產品何時缺貨,偵測錯放的商品,並驗證促銷陳列是否設置正確。當偵測到問題時,例如貨架空了,系統會自動向店員的行動裝置發送警報,以便立即補貨。這確保了產品的可得性,改善了顧客的購物體驗,並提供了關於產品流動性的寶貴數據。
社交媒體品牌監控
一家全球飲料公司的行銷分析師使用圖像識別工具來追蹤其品牌在網路上的曝光度。該工具每天掃描社交媒體平台上發布的數百萬張公開圖片,搜尋該公司的Logo。這使得分析師能夠識別包含其產品的用戶生成內容,監控品牌的呈現方式,並發現潛在的影響者行銷機會。與基於文本的搜尋不同,這種方法能捕捉到未明確寫出品牌名稱的視覺提及,從而提供更全面的品牌知名度和參與度視圖。