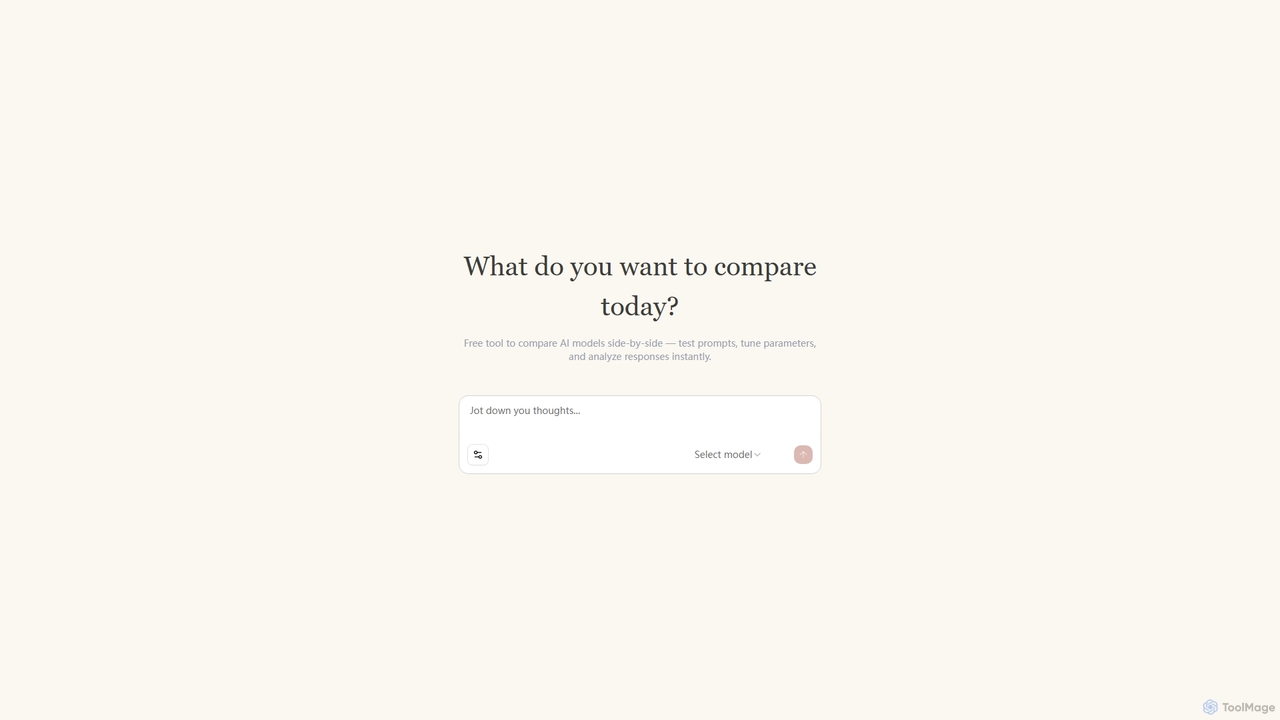
Llm Lab Three
Ein kostenloses Tool für Entwickler und Forscher zum direkten Vergleich von Großen Sprachmodellen (LLMs). Testen Sie Prompts, passen …
Ein kostenloses Tool für Entwickler und Forscher zum direkten Vergleich von Großen Sprachmodellen (LLMs). Testen Sie Prompts, passen Sie Parameter an und analysieren Sie Antworten sofort, um das optimale Modell für jede Aufgabe zu finden.
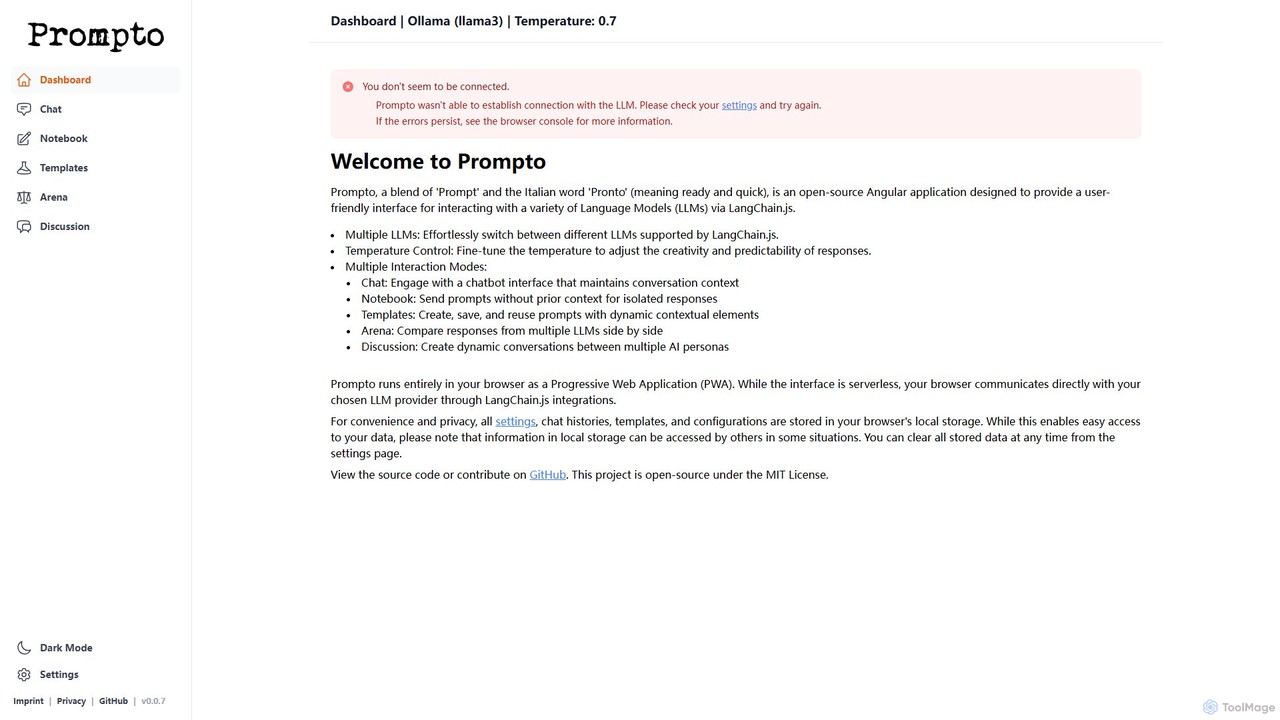
Prompto
Prompto ist eine kostenlose, quelloffene, browserbasierte Oberfläche zur Interaktion mit einer Vielzahl von Großen Sprachmodellen (LLMs). Es nutzt …
Prompto ist eine kostenlose, quelloffene, browserbasierte Oberfläche zur Interaktion mit einer Vielzahl von Großen Sprachmodellen (LLMs). Es nutzt LangChain.js, um sich direkt mit Anbietern wie OpenAI, Anthropic und lokalen Modellen über Ollama zu verbinden, und bietet erweiterte Funktionen wie eine Modellvergleichs-Arena, Prompt-Vorlagen und Multi-KI-Diskussionen, wobei die Privatsphäre der Nutzer durch lokale Datenspeicherung an erster Stelle steht.
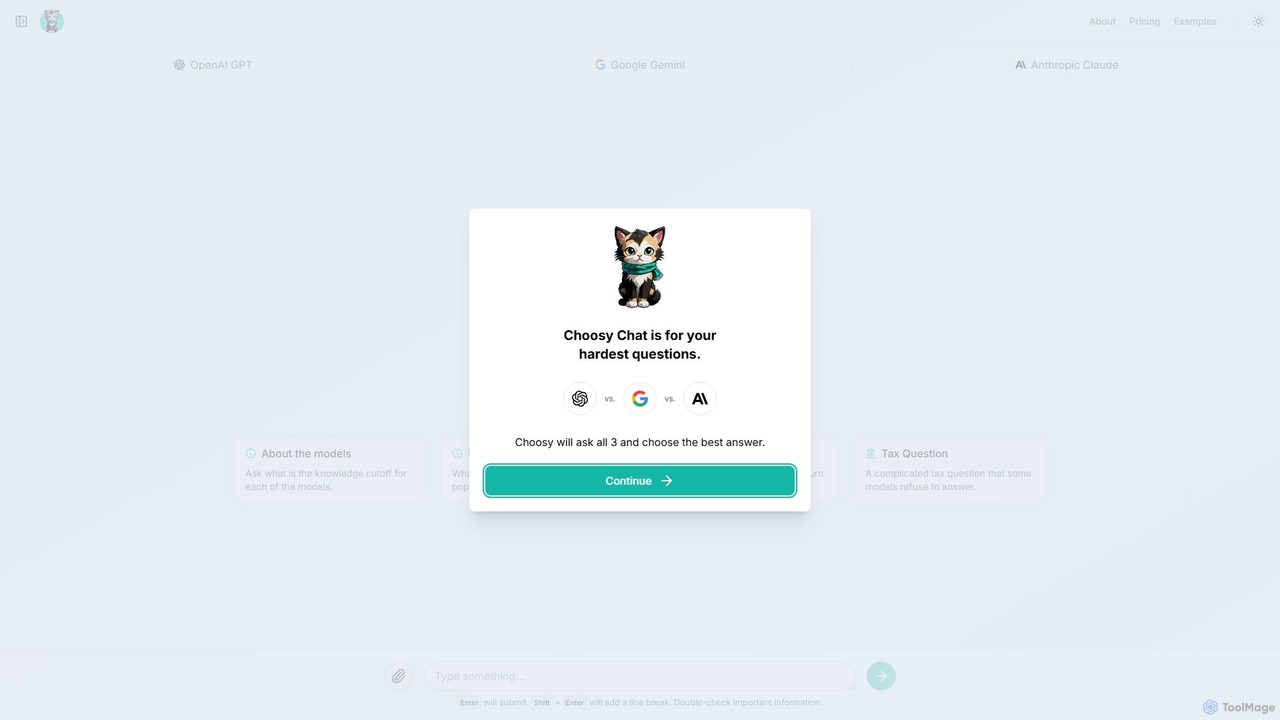
Choosy Chat
Choosy Chat ist ein KI-Tool, das Ihre Anfrage gleichzeitig an GPT, Gemini und Claude sendet, sodass Sie deren …
Choosy Chat ist ein KI-Tool, das Ihre Anfrage gleichzeitig an GPT, Gemini und Claude sendet, sodass Sie deren Antworten nebeneinander vergleichen können. Es hilft Ihnen, die bestmögliche Antwort für jede Anfrage zu finden, vom Programmieren bis zum kreativen Schreiben.
Über Modellvergleich
Modellvergleichs-Tools sind spezialisierte Plattformen zur Bewertung und zum Benchmarking der Leistung verschiedener KI-Modelle nebeneinander. Diese Tools bieten eine strukturierte Umgebung zum Testen von Modellen mit standardisierten Datensätzen, benutzerdefinierten Prompts und wichtigen Leistungsindikatoren wie Genauigkeit, Geschwindigkeit und Kosten. Sie sind für Entwickler, Forscher und Unternehmen unerlässlich, um datengestützte Entscheidungen bei der Auswahl des am besten geeigneten KI-Modells für eine bestimmte Anwendung zu treffen. Dies ermöglicht eine objektive Analyse jenseits von Marketingaussagen und gewährleistet optimale Leistung und Kosteneffizienz.
Kernfunktionen
- Side-by-Side-Schnittstelle: Vergleichen Sie Modellausgaben für denselben Prompt direkt in einer einheitlichen Ansicht.
- Automatisiertes Benchmarking: Führen Sie standardisierte Tests (z. B. MMLU, HellaSwag) durch, um die objektive Leistung zu messen.
- Kosten- & Latenzanalyse: Verfolgen Sie API-Kosten und Antwortzeiten, um die Effizienz verschiedener Modelle zu bewerten.
- Qualitative Ranglisten: Greifen Sie auf Crowdsourcing- oder Experten-Rankings zu, die auf menschlichen Vorlieben und Qualität basieren.
- Benutzerdefinierte Testsuiten: Laden Sie Ihre eigenen Datensätze und Prompts hoch, um Modelle bei domänenspezifischen Aufgaben zu bewerten.
Anwendungsfälle
Diese Tools werden häufig von KI-Entwicklern verwendet, die ein Basismodell für eine neue Anwendung auswählen, von MLOps-Teams, die die Modelldegradation überwachen, und von Produktmanagern, die das Preis-Leistungs-Verhältnis von Anbietern wie OpenAI, Anthropic und Google vergleichen. Forscher nutzen sie auch, um die Leistung neuer Modelle anhand etablierter Benchmarks zu validieren.
Wie man wählt
Berücksichtigen Sie bei der Auswahl eines Tools die Bandbreite der unterstützten Modelle (Open Source vs. proprietär), die verfügbaren Bewertungsmetriken und Benchmarks, die Möglichkeit, benutzerdefinierte Daten für Tests zu verwenden, und ob Sie eine benutzerfreundliche Benutzeroberfläche, eine API zur Automatisierung oder beides benötigen. Bewerten Sie auch das Preismodell, um sicherzustellen, dass es zu Ihrem Testvolumen passt.
ModellvergleichAnwendungsfälle
Auswahl eines LLM für einen Kundenservice-Chatbot
Ein Produktmanager eines E-Commerce-Unternehmens muss ein großes Sprachmodell (LLM) für seinen neuen KI-Chatbot auswählen. Mit einem Modellvergleichs-Tool erstellt er eine Testsuite mit 100 häufigen Kundenanfragen. Er führt diese Suite mit Modellen wie GPT-4, Claude 3 und Llama 3 aus und vergleicht sie hinsichtlich Antwortgenauigkeit, Höflichkeit, Latenz und Kosten pro 1.000 Anfragen. Die Side-by-Side-Ansicht der Plattform zeigt, dass Claude 3 das beste Gleichgewicht zwischen Qualität und Kosten für ihren spezifischen Anwendungsfall bietet, was eine datengestützte Entscheidung in Stunden statt in Wochen manueller Tests ermöglicht.
Benchmarking eines feingetunten Open-Source-Modells
Ein ML-Engineering-Team hat ein Llama 3-Modell auf der internen Wissensdatenbank ihres Unternehmens feingetunt. Um seine Wirksamkeit zu validieren, verwenden sie eine Modellvergleichsplattform, um es mit dem Basis-Llama-3-Modell und GPT-4 zu benchmarken. Sie führen branchenübliche Tests wie MMLU für Allgemeinwissen und ein benutzerdefiniertes Testset mit 50 internen F&A-Paaren durch. Die Ergebnisse zeigen, dass ihr feingetuntes Modell das Basismodell bei internen Fragen um 30 % übertrifft, was die für das Feintuning aufgewendeten Ressourcen rechtfertigt.
Kostenoptimierung für eine KI-gestützte Inhaltsfunktion
Ein Startup bietet eine KI-Funktion an, die Artikel für Benutzer zusammenfasst. Da das Benutzerwachstum beschleunigt, werden die Kosten ihrer aktuellen High-End-Modell-API zu einem Problem. Das Entwicklungsteam verwendet ein Modellvergleichs-Tool, um günstigere, kleinere Modelle für ihre Zusammenfassungsaufgabe zu testen. Sie vergleichen die Ausgaben hinsichtlich Qualität, Kohärenz und Länge und überwachen gleichzeitig das Kostenanalyse-Dashboard. Sie entdecken ein kleineres, destilliertes Modell, das 95 % der Qualität zu nur 40 % der Kosten liefert und so ihre Gewinnmargen erheblich verbessert.
A/B-Test von Bilderzeugungsmodellen für das Marketing
Ein Marketingteam muss Visuals für eine neue Werbekampagne erstellen. Sie sind sich unsicher, ob sie Midjourney, Stable Diffusion oder DALL-E 3 für ihre gewünschte Ästhetik verwenden sollen. Sie verwenden ein Modellvergleichs-Tool, um denselben Satz kreativer Prompts in alle drei Modelle einzugeben. Die Plattform organisiert die Ausgaben, sodass das Team die generierten Bilder nach Markenausrichtung, visueller Anziehungskraft und Kreativität bewerten und einstufen kann. Dieser strukturierte Prozess hilft ihnen, schnell zu erkennen, dass Stable Diffusion am besten zum Stil ihrer Kampagne passt.
Akademische Forschung zu Modellfähigkeiten
Ein Universitätsforscher untersucht die Denkfähigkeiten der neuesten KI-Modelle. Er nutzt die API einer Modellvergleichsplattform, um programmatisch Tausende von Logikrätseln und mathematischen Problemen über ein Dutzend verschiedene Modelle laufen zu lassen. Das Tool automatisiert die Tests, sammelt die Ergebnisse und liefert aggregierte Genauigkeitswerte. Dies erspart dem Forscher Hunderte von Stunden manueller Skripterstellung und Ausführung und ermöglicht es ihm, sich auf die Analyse der Daten und die Veröffentlichung seiner Ergebnisse zu den Leistungstrends der Modelle zu konzentrieren.
Auswahl eines Codegenerierungsmodells für Entwickler-Tools
Ein Unternehmen, das ein IDE-Plugin entwickelt, möchte eine KI-Codevervollständigungsfunktion hinzufügen. Der technische Leiter muss sich zwischen Modellen wie GitHub Copilot (GPT-basiert), Code Llama und anderen spezialisierten Codierungsmodellen entscheiden. Sie verwenden ein Modellvergleichs-Tool mit einer Benchmark-Suite wie HumanEval. Dies ermöglicht es ihnen, die Fähigkeit jedes Modells, korrekte und effiziente Code-Schnipsel in verschiedenen Programmiersprachen zu generieren, objektiv zu messen und sicherzustellen, dass sie die zuverlässigste und leistungsfähigste Option für ihre Benutzer integrieren.