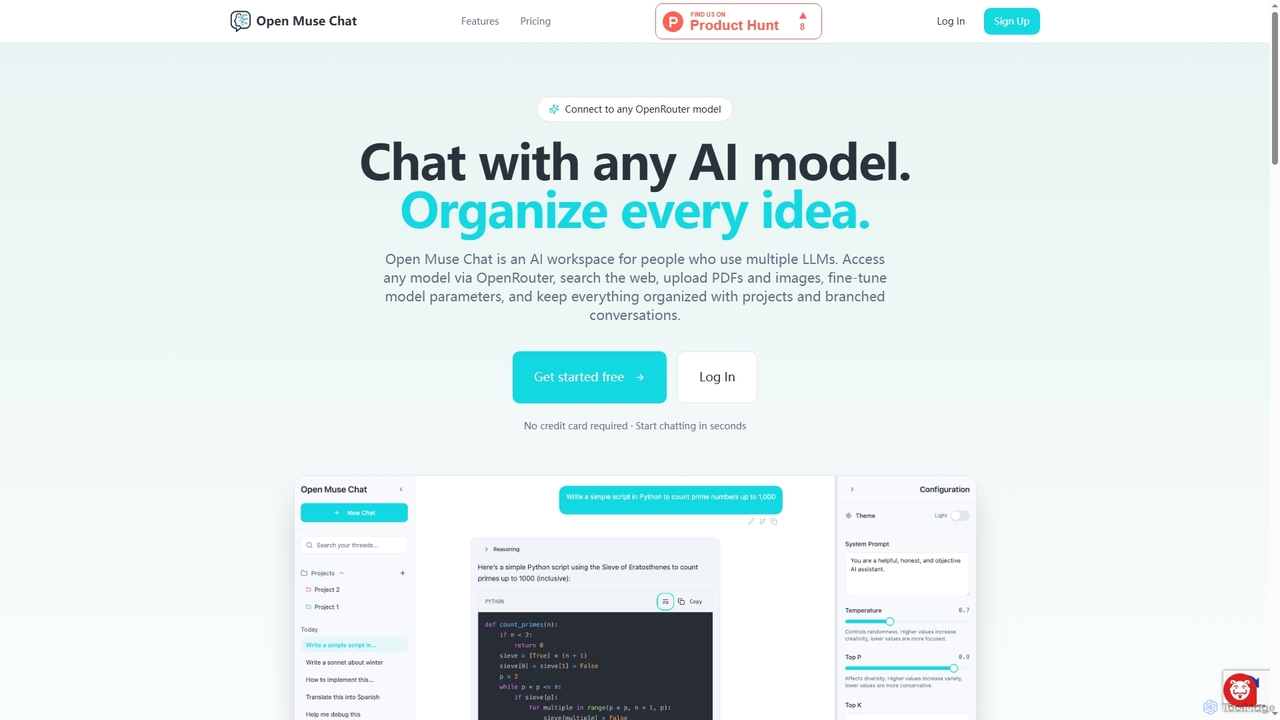
Open Muse Chat
Open Muse Chat ist eine fortschrittliche Multi-Modell-KI-Chat-Oberfläche, die für Benutzer entwickelt wurde, die verschiedene große Sprachmodelle (LLMs) nutzen. …
Open Muse Chat ist eine fortschrittliche Multi-Modell-KI-Chat-Oberfläche, die für Benutzer entwickelt wurde, die verschiedene große Sprachmodelle (LLMs) nutzen. Es verbindet sich mit jedem OpenRouter-Modell, bietet Websuche, Dateiuploads (PDFs, Bilder) als Kontext und ermöglicht eine feingranulare Kontrolle über Modellparameter, alles innerhalb eines organisierten Arbeitsbereichs mit Projekten und verzweigten Konversationen.
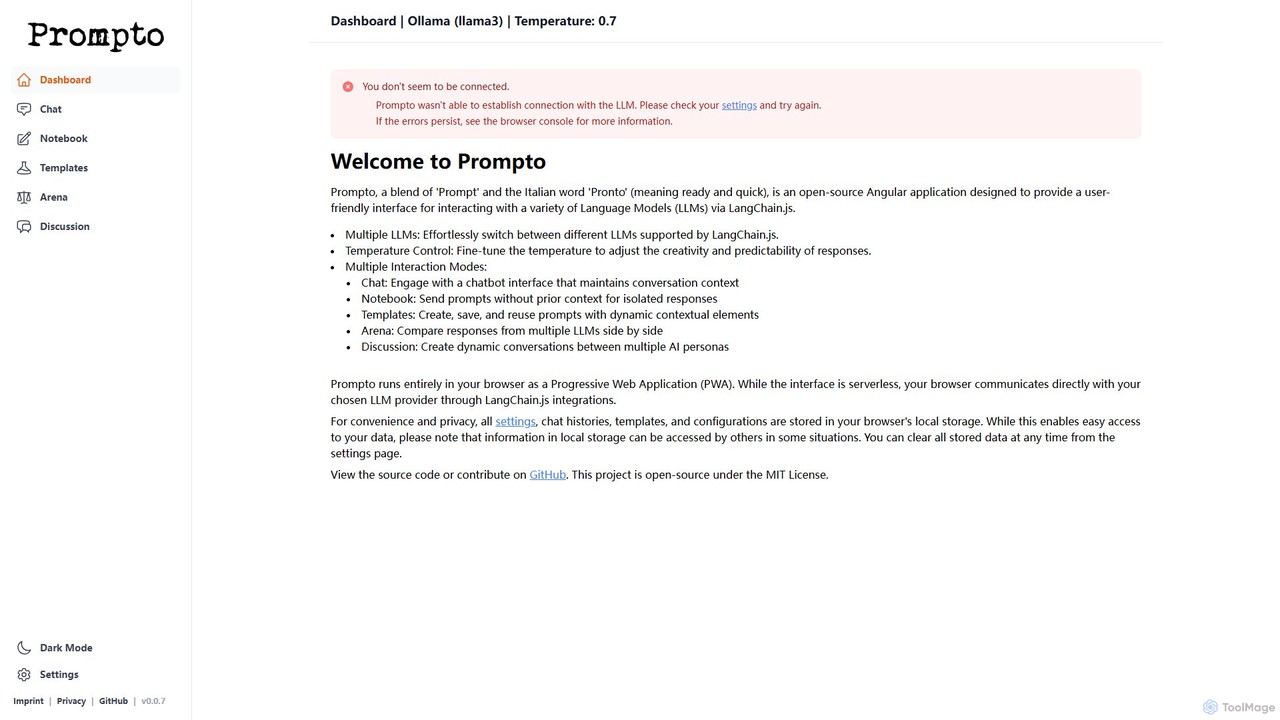
Prompto
Prompto ist eine kostenlose, quelloffene, browserbasierte Oberfläche zur Interaktion mit einer Vielzahl von Großen Sprachmodellen (LLMs). Es nutzt …
Prompto ist eine kostenlose, quelloffene, browserbasierte Oberfläche zur Interaktion mit einer Vielzahl von Großen Sprachmodellen (LLMs). Es nutzt LangChain.js, um sich direkt mit Anbietern wie OpenAI, Anthropic und lokalen Modellen über Ollama zu verbinden, und bietet erweiterte Funktionen wie eine Modellvergleichs-Arena, Prompt-Vorlagen und Multi-KI-Diskussionen, wobei die Privatsphäre der Nutzer durch lokale Datenspeicherung an erster Stelle steht.
Über LLM-Schnittstelle
Eine LLM-Schnittstelle ist ein spezialisiertes Entwicklerwerkzeug, das als einheitliches Gateway für den Zugriff auf mehrere große Sprachmodelle (LLMs) dient. Diese Tools bieten eine einzige, konsistente API, die es Entwicklern ermöglicht, mit verschiedenen Modellen wie GPT, Claude oder Llama zu interagieren, ohne anbieterspezifischen Code schreiben zu müssen. Diese Abstraktionsschicht vereinfacht die Entwicklung, optimiert die Kosten und erhöht die Ausfallsicherheit von Anwendungen, indem sie einen nahtlosen Modellwechsel und Fallbacks ermöglicht. Für Entwickler, die KI-gestützte Anwendungen erstellen, ist eine LLM-Schnittstelle eine entscheidende Komponente zur Bewältigung der Komplexität und zur Verbesserung der betrieblichen Effizienz.
Kernfunktionen
- Einheitliche API: Verbinden Sie sich über einen einzigen, standardisierten API-Endpunkt mit verschiedenen LLMs von unterschiedlichen Anbietern.
- Modell-Routing & Fallbacks: Leiten Sie Anfragen automatisch an das am besten geeignete Modell basierend auf Kosten oder Leistung weiter, mit integrierten Fallback-Mechanismen.
- Kosten- & Nutzungsverfolgung: Überwachen Sie API-Ausgaben, Token-Nutzung und Latenz über alle verbundenen Modelle in einem zentralen Dashboard.
- Prompt-Management: Erstellen, testen, versionieren und implementieren Sie Prompt-Vorlagen zentral für ein konsistentes Anwendungsverhalten.
- Anfrage-Caching: Speichern und wiederverwenden Sie Antworten auf identische Anfragen, um die Latenz zu reduzieren und die API-Kosten zu senken.
Anwendungsfälle
LLM-Schnittstellen werden hauptsächlich von Softwareentwicklern, KI-Ingenieuren und Produktteams verwendet, die Anwendungen erstellen, die Flexibilität und Zuverlässigkeit erfordern. Sie sind ideal für die Erstellung von Multi-Provider-Chatbots, Content-Generierungsplattformen, die die Stärken verschiedener Modelle nutzen, oder komplexe KI-Agenten, die dynamisch das beste Werkzeug für eine Aufgabe auswählen müssen. Unternehmen nutzen sie auch, um den LLM-Zugriff im gesamten Unternehmen zu standardisieren und zu steuern.
Wie man wählt
Bei der Auswahl einer LLM-Schnittstelle sollten Sie Folgendes berücksichtigen: Erstens, bewerten Sie die Liste der unterstützten LLMs und die Geschwindigkeit, mit der neue Modelle integriert werden. Zweitens, bewerten Sie Leistungsmetriken wie Latenz-Overhead und Zuverlässigkeitsgarantien. Drittens, untersuchen Sie die Beobachtbarkeitsfunktionen, wie die Qualität der Protokollierung, Kostenverfolgungs-Dashboards und Analysen. Schließlich, überprüfen Sie die Entwicklererfahrung, einschließlich der Qualität der Dokumentation und der Verfügbarkeit von SDKs für Ihre bevorzugten Programmiersprachen.
LLM-SchnittstelleAnwendungsfälle
Erstellung eines widerstandsfähigen KI-Chatbots mit Modell-Fallbacks
Ein technischer Leiter im Kundenservice muss sicherstellen, dass sein Support-Chatbot eine hohe Verfügbarkeit aufweist. Mithilfe einer LLM-Schnittstelle konfiguriert er ein primäres Modell wie GPT-4 für hochwertige Antworten und ein sekundäres, kostengünstiges Modell wie Claude 3 Sonnet als Fallback. Wenn die API des primären Modells einen Ausfall oder eine hohe Latenz aufweist, leitet die Schnittstelle alle eingehenden Anfragen automatisch an das Fallback-Modell um. Dies stellt sicher, dass der Chatbot betriebsbereit und für die Benutzer reaktionsschnell bleibt und eine Dienstunterbrechung ohne manuellen Eingriff des Ingenieurteams verhindert wird.
A/B-Testen von Prompts für einen Marketing-Textgenerator
Ein Marketing-Technologe möchte den effektivsten Prompt zur Generierung von Werbeüberschriften finden. Mit dem Prompt-Management-System der LLM-Schnittstelle erstellt er zwei Varianten eines Prompts ('Prompt A' und 'Prompt B'). Die Schnittstelle wird so konfiguriert, dass 50 % der Generierungsanfragen an jede Prompt-Version weitergeleitet werden. Das integrierte Analyse-Dashboard verfolgt wichtige Metriken wie Klickraten und Nutzerengagement für die von jedem Prompt generierten Überschriften. Nach der Analyse der Daten kann das Team den gewinnenden Prompt mit einem einzigen Klick zuversichtlich auf 100 % des Traffics anwenden und so die Kampagnenleistung optimieren.
Optimierung der API-Kosten für einen Inhaltszusammenfassungsdienst
Das Zusammenfassungstool eines Startups muss die LLM-API-Kosten effektiv verwalten. Sie verwenden eine LLM-Schnittstelle, um intelligentes Routing zu implementieren. Einfache Anfragen, wie das Zusammenfassen eines kurzen Absatzes, werden an ein schnelles, kostengünstiges Modell gesendet. Komplexere Aufgaben, wie das Zusammenfassen eines 20-seitigen Dokuments, werden an ein leistungsstarkes, hochfähiges Modell weitergeleitet. Das Kostenverfolgungs-Dashboard der Schnittstelle bietet eine Echtzeitansicht der Ausgaben pro Modell, sodass das Team seine Routing-Regeln und Caching-Strategie feinabstimmen kann, um im Budget zu bleiben und gleichzeitig eine hohe Ausgabequalität für alle Benutzer aufrechtzuerhalten.
Standardisierung des LLM-Zugriffs in einem großen Unternehmen
Ein Unternehmens-IT-Architekt muss Entwicklern einen sicheren, gesteuerten Zugriff auf verschiedene LLMs ermöglichen. Sie implementieren eine zentrale LLM-Schnittstelle als Gateway. Dies ermöglicht es ihnen, alle API-Schlüssel in einem sicheren Tresor zu verwalten, Ausgabenlimits und Nutzungskontingente für verschiedene Teams festzulegen und Datenschutzrichtlinien durchzusetzen. Die Schnittstelle protokolliert jede Anfrage und bietet einen vollständigen Audit-Trail für Compliance-Zwecke. Dieser zentralisierte Ansatz befähigt Entwicklungsteams, mit verschiedenen Modellen zu innovieren, während die Organisation die Kontrolle über Sicherheit, Kosten und Governance behält.
Schnelles Prototyping einer KI-gestützten Funktion
Ein Produktteam erstellt schnell einen Prototyp für eine neue KI-Funktion. Anstatt separate Integrationen für OpenAI, Anthropic und Google zu schreiben, verwenden sie ein einziges LLM-Schnittstellen-SDK. Dies ermöglicht es ihnen, zwischen GPT-4, Claude und Gemini zu wechseln, indem sie nur eine Zeile Konfigurationscode ändern. Sie können schnell testen, welches Modell die beste Qualität, Geschwindigkeit und Kosteneffizienz für ihren spezifischen Anwendungsfall bietet. Dies beschleunigt die Prototyping-Phase dramatisch und ermöglicht es ihnen, ihre Idee zu validieren und viel schneller in die Produktion zu gehen.
Caching von Antworten für ein stark frequentiertes Q&A-System
Ein Entwickler erstellt einen FAQ-Bot für eine beliebte E-Commerce-Website, die viele sich wiederholende Fragen erhält. Er aktiviert die Caching-Funktion in seiner LLM-Schnittstelle. Wenn eine Frage wie „Was ist Ihre Rückgaberichtlinie?“ zum ersten Mal gestellt wird, generiert das LLM eine Antwort, und die Schnittstelle speichert dieses Frage-Antwort-Paar in einem Cache. Bei allen nachfolgenden identischen Fragen wird die Antwort direkt aus dem Cache in Millisekunden bereitgestellt. Diese Strategie reduziert die API-Aufrufe an den LLM-Anbieter erheblich, senkt die Kosten um über 70 % und liefert den Benutzern bei häufigen Anfragen nahezu sofortige Antworten.