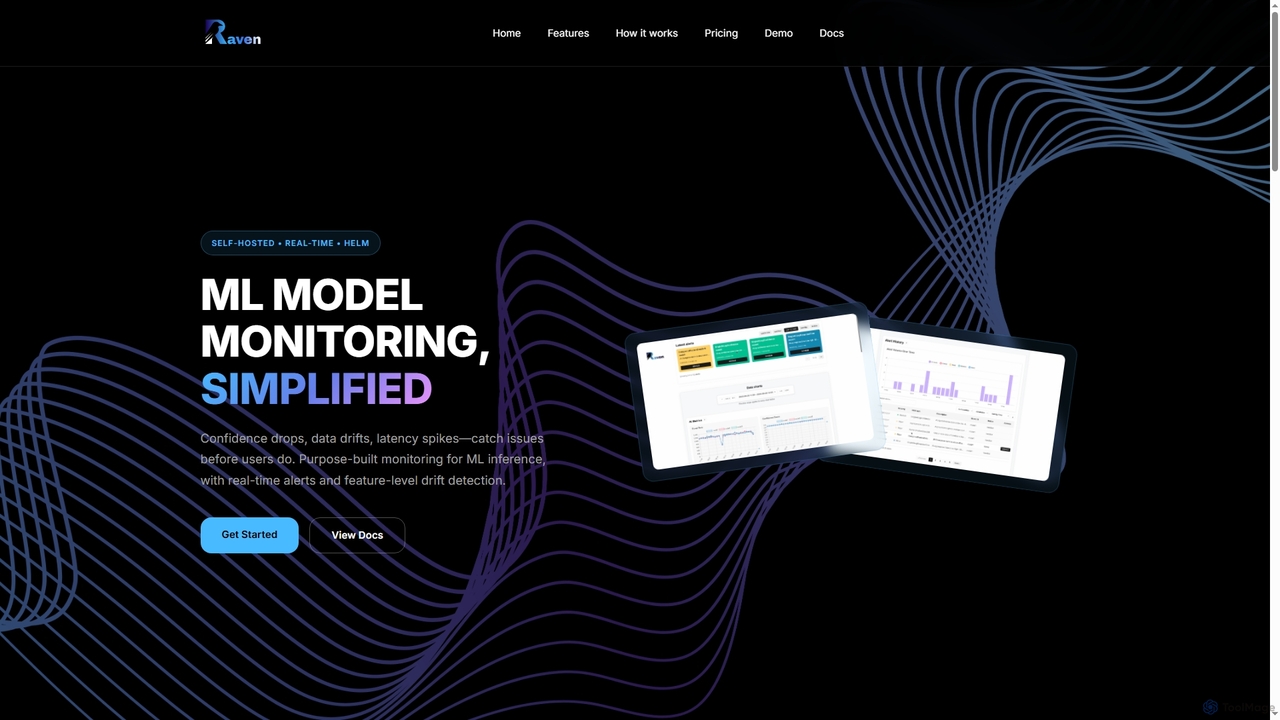
Raven
Raven ist eine selbstgehostete Echtzeit-ML-Modellüberwachungsplattform, die entwickelt wurde, um die Beobachtbarkeit von KI-Pipelines zu vereinfachen. Sie erkennt Daten-Drift, …
Raven ist eine selbstgehostete Echtzeit-ML-Modellüberwachungsplattform, die entwickelt wurde, um die Beobachtbarkeit von KI-Pipelines zu vereinfachen. Sie erkennt Daten-Drift, Latenzspitzen und Vertrauensabfälle und liefert sofortige Warnungen, um die Zuverlässigkeit und Leistung des Modells in Produktionsumgebungen zu gewährleisten.
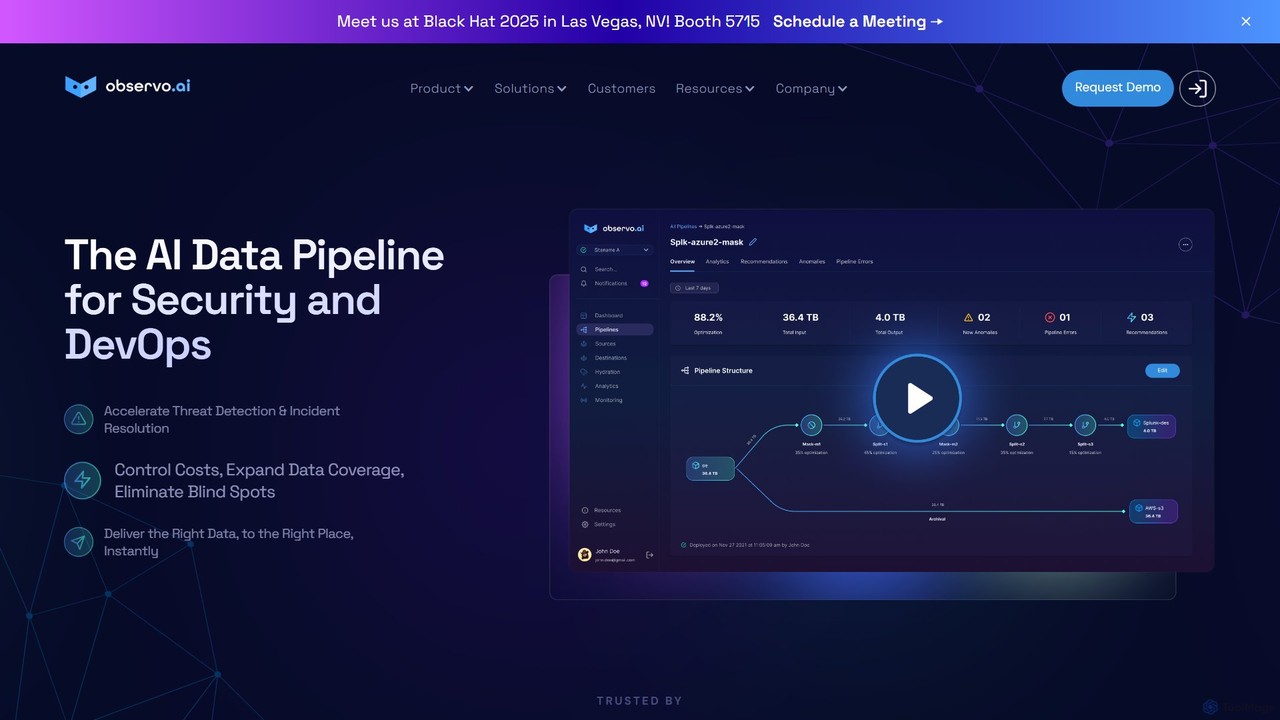
Observo AI
Observo AI ist eine intelligente Datenpipeline-Plattform für Sicherheits- und DevOps-Teams. Sie nutzt KI, um Telemetriedaten zu optimieren, das …
Observo AI ist eine intelligente Datenpipeline-Plattform für Sicherheits- und DevOps-Teams. Sie nutzt KI, um Telemetriedaten zu optimieren, das Protokollvolumen um bis zu 80 % und die Beobachtbarkeitskosten um über 50 % zu senken. Die Plattform beschleunigt die Bedrohungserkennung, reichert Daten in Echtzeit an und beseitigt blinde Flecken, wodurch Sicherheit und Betrieb effizienter und kostengünstiger werden.
Über Beobachtbarkeit
Observability AI-Tools sind fortschrittliche Plattformen, die künstliche Intelligenz und maschinelles Lernen nutzen, um tiefe Einblicke in den internen Zustand komplexer Softwaresysteme, Infrastrukturen und KI-Modelle zu ermöglichen. Diese Tools automatisieren die Sammlung, Korrelation und Analyse von Telemetriedaten – Protokollen, Metriken und Traces – aus verteilten Umgebungen. Indem sie Rohdaten in verwertbare Informationen umwandeln, versetzen sie Engineering- und Betriebsteams in die Lage, Leistungsengpässe proaktiv zu identifizieren, Probleme zu diagnostizieren und potenzielle Ausfälle vorherzusagen, wodurch die Systemzuverlässigkeit und eine optimale Benutzererfahrung im Rahmen eines DevOps-Frameworks gewährleistet werden.
Kernfunktionen
- Automatisierte Telemetriedatenerfassung: Sammelt Protokolle, Metriken und Traces aus verschiedenen Quellen in Hybrid- und Multi-Cloud-Umgebungen.
- KI-gesteuerte Anomalieerkennung: Identifiziert automatisch ungewöhnliche Muster und Abweichungen vom normalen Systemverhalten, wodurch die Alarmmüdigkeit reduziert wird.
- Verteiltes Tracing & Ursachenanalyse: Visualisiert End-to-End-Transaktionsflüsse und korreliert Ereignisse, um die Ursache von Leistungsproblemen schnell zu lokalisieren.
- Prädiktive Analyse: Nutzt maschinelles Lernen, um zukünftige Systemleistung und potenzielle Ausfälle basierend auf historischen Daten vorherzusagen.
- Intelligente Alarmierung & Incident Management: Erzeugt kontextreiche Alarme und integriert sich in Incident-Response-Workflows für eine schnellere Lösung.
Anwendungsfälle
DevOps-Teams und Site Reliability Engineers (SREs) nutzen Observability AI-Tools, um die hohe Verfügbarkeit und Leistung kritischer Anwendungen aufrechtzuerhalten. Sie sind unerlässlich für die Überwachung von Microservices-Architekturen, Serverless-Funktionen und containerisierten Bereitstellungen und bieten eine einheitliche Ansicht des Systemzustands. Diese Tools helfen auch bei der Optimierung der Ressourcennutzung und der Sicherstellung der Compliance in stark regulierten Branchen.
Auswahlkriterien
Bei der Auswahl eines Observability AI-Tools sollten Sie dessen Datenaufnahmefähigkeiten über Ihren gesamten Technologie-Stack hinweg, die Komplexität seiner KI/ML-Algorithmen für Anomalieerkennung und Ursachenanalyse sowie dessen Integration mit bestehenden DevOps-Tools und -Workflows berücksichtigen. Bewerten Sie seine Skalierbarkeit zur Bewältigung wachsender Datenmengen, die Klarheit seiner Visualisierungs-Dashboards und sein Preismodell basierend auf Datenverbrauch oder überwachten Entitäten. Achten Sie auf robuste Sicherheitsfunktionen und Compliance-Zertifizierungen.
BeobachtbarkeitAnwendungsfälle
Proaktive Anomalieerkennung in Microservices
Ein Site Reliability Engineer (SRE) verwendet ein Observability AI-Tool, um Hunderte von Microservices in einer Cloud-nativen Anwendung kontinuierlich zu überwachen. Die KI lernt automatisch Basisverhaltensweisen und markiert subtile Anomalien bei Antwortzeiten oder Fehlerraten, die bei manueller Überwachung übersehen werden könnten. Dies ermöglicht es dem SRE, potenzielle Probleme zu untersuchen und zu beheben, bevor sie zu weitreichenden Ausfällen eskalieren, und so die Service Level Objectives (SLOs) einzuhalten.
Beschleunigung der Ursachenanalyse bei Produktionsvorfällen
Während eines kritischen Produktionsvorfalls nutzt ein DevOps-Team die verteilten Tracing- und KI-gesteuerten Korrelationsfunktionen einer Observability-Plattform. Das Tool verknüpft automatisch Protokolle, Metriken und Traces über mehrere Dienste und Infrastrukturkomponenten hinweg und identifiziert visuell den genauen Dienst oder die Codeänderung, die die Verschlechterung verursacht hat. Dies reduziert die mittlere Reparaturzeit (MTTR) drastisch von Stunden auf Minuten.
Optimierung der Cloud-Ressourcennutzung und -kosten
Ein Cloud-Architekt setzt Observability AI ein, um die Ressourcennutzungsmuster (CPU, Speicher, Netzwerk-I/O) seiner gesamten Cloud-Infrastruktur zu analysieren. Die KI identifiziert ungenutzte Ressourcen und gibt Empfehlungen zur Größenanpassung von Instanzen oder zur Optimierung von Auto-Scaling-Regeln. Dies führt zu erheblichen Kosteneinsparungen, indem unnötige Ausgaben für überprovisionierte Cloud-Dienste ohne Leistungseinbußen vermieden werden.
Überwachung der KI-Modellleistung und -drift
Datenwissenschaftler und MLOps-Ingenieure verwenden Observability-Tools, die speziell auf KI-Modelle zugeschnitten sind, um die Inferenzlatenz, Daten-Drift und Modellgenauigkeit in der Produktion zu verfolgen. Die KI erkennt, wenn Modellvorhersagen vom erwarteten Verhalten abweichen oder wenn sich Eingabedaten erheblich ändern. Dies stellt sicher, dass KI-Modelle über die Zeit effektiv und fair bleiben und bei Bedarf ein erneutes Training oder Eingreifen auslösen.
Sicherstellung von Compliance und Sicherheitslage
Ein Sicherheitsteam integriert eine Observability-Plattform, um Systemprotokolle und Netzwerkverkehr auf verdächtige Aktivitäten und Compliance-Verstöße zu überwachen. Die KI-Engine identifiziert ungewöhnliche Zugriffsmuster, unautorisierte Konfigurationsänderungen oder potenzielle Datenexfiltrationsversuche. Dies bietet Echtzeit-Bedrohungserkennung und Audit-Trails, die Unternehmen dabei helfen, regulatorische Anforderungen wie DSGVO oder HIPAA zu erfüllen.
Verbesserung der Benutzererfahrung durch Identifizierung von Frontend-Engpässen
Ein Produktentwicklungsteam nutzt Observability AI, um Einblicke in Real User Monitoring (RUM)-Daten zu gewinnen und Frontend-Leistungsmetriken mit der Backend-Service-Gesundheit zu korrelieren. Das Tool identifiziert spezifische Benutzerpfade, bei denen langsame Ladezeiten oder Fehler auftreten, und verfolgt diese auf ineffiziente API-Aufrufe oder Frontend-Code-Probleme zurück. Dies ermöglicht gezielte Optimierungen, die die Endbenutzererfahrung direkt verbessern.