BenchLLM
Website besuchen
BenchLLM Übersicht
BenchLLM ist ein spezialisiertes Open-Source-Evaluierungsframework, das sorgfältig von KI-Ingenieuren für KI-Ingenieure entwickelt wurde. Es befasst sich direkt mit der kritischen Herausforderung, die Zuverlässigkeit und Vorhersagbarkeit von Anwendungen zu gewährleisten, die auf Großen Sprachmodellen (LLMs) basieren. Da KI-Modelle immer leistungsfähiger und in Produkte integriert werden, wird die Notwendigkeit systematischer Tests von einem „Nice-to-have“ zu einem wesentlichen Bestandteil des Entwicklungszyklus. BenchLLM bietet die Werkzeuge, um die Lücke zwischen der probabilistischen Natur von LLMs und der Nachfrage nach deterministischer, qualitativ hochwertiger Leistung zu schließen.
Das Framework ist sowohl leistungsstark als auch flexibel konzipiert und ermöglicht es Entwicklern, umfassende Testsuiten zu erstellen, zu verwalten und auszuführen. Diese Tests können verschiedene Aspekte der Modellleistung bewerten, von der sachlichen Genauigkeit und der Erkennung von Halluzinationen bis hin zur Einhaltung spezifischer Ausgabeformate. Durch die direkte Integration dieser Bewertungen in den Entwicklungsworkflow können Teams mit Zuversicht entwickeln, Regressionen frühzeitig erkennen und konsistent eine überlegene Benutzererfahrung bieten.
Wie man BenchLLM verwendet
Die Verwendung von BenchLLM ist unkompliziert und so konzipiert, dass sie sich in bestehende Entwicklungsworkflows einfügt. Der Prozess umfasst in der Regel einige wichtige Schritte:
- Installation: Als Python-Bibliothek kann BenchLLM einfach mit einem Paketmanager wie pip in Ihre Projektumgebung installiert werden.
- Tests definieren: Sie können Ihre Testfälle intuitiv mit einfachen, für Menschen lesbaren Formaten wie YAML oder JSON definieren. Jeder Testfall besteht aus einer Eingabeaufforderung und einer oder mehreren erwarteten Ausgaben. Dies ermöglicht eine einfache Versionierung und Zusammenarbeit, da Tests zusammen mit Ihrem Quellcode gespeichert werden können.
- Integration in Ihren Code: BenchLLM bietet eine einfache API, um Ihre LLM-aufrufenden Funktionen zu umschließen. Unabhängig davon, ob Sie die OpenAI-Bibliothek direkt, Langchain-Agenten oder eine benutzerdefinierte API verwenden, können Sie sie problemlos mit dem BenchLLM-Tester verbinden.
- Tests ausführen: Tests können entweder über die leistungsstarke Befehlszeilenschnittstelle (CLI) oder programmgesteuert über die Python-API ausgeführt werden. Der CLI-Befehl `bench run` führt Ihre definierten Testsuiten aus und generiert Vorhersagen von Ihrem Modell.
- Bewerten und Berichten: Nach der Ausführung der Tests verwenden Sie einen `Evaluator` (z. B. `SemanticEvaluator`), um die tatsächlichen Ausgaben des Modells mit den erwarteten zu vergleichen. BenchLLM generiert dann aufschlussreiche Berichte, die klar zeigen, welche Tests bestanden wurden und welche fehlgeschlagen sind, und liefert den notwendigen Kontext für das Debugging und die Verbesserung.
Kernfunktionen von BenchLLM
- Flexible Testdefinition: Erstellen und organisieren Sie Tests in einfach zu verwaltenden YAML- oder JSON-Dateien, was klare, versionierbare Testsuiten ermöglicht.
- Leistungsstarke CLI: Eine robuste Befehlszeilenschnittstelle ermöglicht es Ihnen, Bewertungen auszuführen, Berichte zu generieren und Tests nahtlos in CI/CD-Pipelines für eine vollständige Automatisierung zu integrieren.
- Vielseitige API: Eine entwicklerfreundliche Python-API ermöglicht On-the-fly-Tests und benutzerdefinierte Bewertungslogik direkt in Ihrem Anwendungscode.
- Mehrere Bewertungsstrategien: Unterstützt verschiedene Bewertungsmethoden, einschließlich exakter Übereinstimmung, Regex und fortgeschrittener semantischer Ähnlichkeitsprüfungen, um die Qualität der Modellausgabe genau zu bewerten.
- Breite Kompatibilität: Bietet sofortige Unterstützung für beliebte Bibliotheken wie OpenAI und Langchain und ist erweiterbar, um mit jeder benutzerdefinierten LLM-API zu arbeiten.
- Umfassende Berichterstattung: Erstellt klare und umsetzbare Bewertungsberichte, die Fehler, Leistungsmetriken und Regressionen hervorheben und einfach mit Ihrem Team geteilt werden können.
- Produktionsüberwachung: Das Framework kann zur Überwachung der Modellleistung in der Produktion verwendet werden, um Leistungsabweichungen zu erkennen und die fortlaufende Zuverlässigkeit zu gewährleisten.
Anwendungsfälle für BenchLLM
BenchLLM ist vielseitig und kann in zahlreichen Szenarien während des gesamten KI-Entwicklungszyklus angewendet werden. Wichtige Anwendungsfälle sind: Regressionstests in CI/CD, bei denen automatisch überprüft wird, ob neue Änderungen die Leistung des Modells nicht beeinträchtigt haben; Halluzinationserkennung, durch Erstellen von Tests mit Fragen, auf die es keine bekannte Antwort gibt (z. B. zukünftige Ereignisse), um sicherzustellen, dass das Modell angemessen reagiert; Modell-Benchmarking, mit dem Sie dieselbe Testsuite gegen verschiedene LLMs (z. B. GPT-4 vs. Claude 3) oder Prompt-Variationen ausführen können, um deren Leistung objektiv zu messen und zu vergleichen; und Qualitätssicherung, durch Festlegung einer Qualitätsbasislinie, die alle Modellversionen vor der Bereitstellung erfüllen müssen.
Vorteile von BenchLLM
Der Hauptvorteil von BenchLLM besteht darin, dass es mit einer „Developer-First“-Mentalität entwickelt wurde. Es ist ein offenes und flexibles Werkzeug, das Ingenieuren die volle Kontrolle über den Bewertungsprozess gibt, im Gegensatz zu einigen Black-Box-Lösungen. Da es Open-Source ist, bietet es maximale Transparenz und Anpassbarkeit. Es verwandelt die LLM-Entwicklung in eine strukturiertere, vorhersagbarere Ingenieurdisziplin, weg von Versuch und Irrtum. Durch die Automatisierung der mühsamen und fehleranfälligen Aufgabe des manuellen Testens wird der Entwicklungszyklus erheblich rationalisiert, die Produktqualität verbessert und die Entwicklerproduktivität gesteigert.
Preise und Pläne
BenchLLM ist ein vollständig kostenloses Open-Source-Tool, das vom Team bei V7 entwickelt und gewartet wird. Es steht jedem zur Verfügung, um es über sein GitHub-Repository herunterzuladen, zu verwenden und dazu beizutragen. Es gibt keine kostenpflichtigen Pläne, Abonnements oder versteckten Kosten, um den vollen Funktionsumfang zu nutzen, was es zu einer zugänglichen Wahl für einzelne Entwickler, Start-ups und große Unternehmen gleichermaßen macht.
BenchLLM Kommentare (0)
Melden Sie sich an, um einen Kommentar zu hinterlassen
Jetzt anmeldenBenchLLM Alternativen
Alle anzeigen
TestZeus
TestZeus ist eine KI-gestützte, No-Code-Testautomatisierungsplattform, die speziell für Salesforce entwickelt wurde. Sie nutzt autonome KI-Agenten, um Tests aus …
TestZeus ist eine KI-gestützte, No-Code-Testautomatisierungsplattform, die speziell für Salesforce entwickelt wurde. Sie nutzt autonome KI-Agenten, um Tests aus natürlichsprachlichen Eingaben zu schreiben, auszuführen und zu warten, wodurch eine Testabdeckung von bis zu 100 % in Tagen erreicht und der Wartungsaufwand eliminiert wird.
codegate
Codegate ist ein Open-Source-Sicherheitsgateway und Multiplexing-Framework für KI-Agentensysteme. Entwickelt von Stacklok, bietet es sichere Arbeitsbereiche und richtlinienbasierte Zugriffskontrolle, …
Codegate ist ein Open-Source-Sicherheitsgateway und Multiplexing-Framework für KI-Agentensysteme. Entwickelt von Stacklok, bietet es sichere Arbeitsbereiche und richtlinienbasierte Zugriffskontrolle, die es Entwicklern ermöglichen, komplexe Multi-Agenten-Anwendungen sicher und effizient zu erstellen und zu verwalten.
vocode
Vocode ist eine Open-Source-Plattform zum Erstellen, Bereitstellen und Skalieren von hyperrealistischen Sprach-KI-Agenten. Sie bietet Entwicklern ein Kern-Framework und …
Vocode ist eine Open-Source-Plattform zum Erstellen, Bereitstellen und Skalieren von hyperrealistischen Sprach-KI-Agenten. Sie bietet Entwicklern ein Kern-Framework und eine unternehmenstaugliche API zur Erstellung anspruchsvoller sprachbasierter LLM-Anwendungen für Aufgaben wie automatisierten Kundenservice, Verkaufsanrufe und interaktive Sprachdialogsysteme (IVR).
Confident AI
Confident AI ist eine LLM-Evaluierungs- und Beobachtbarkeitsplattform für Ingenieurteams. Entwickelt von den Schöpfern der Open-Source-Bibliothek DeepEval, hilft es …
Confident AI ist eine LLM-Evaluierungs- und Beobachtbarkeitsplattform für Ingenieurteams. Entwickelt von den Schöpfern der Open-Source-Bibliothek DeepEval, hilft es beim Benchmarking, Absichern und Verbessern von LLM-Anwendungen durch umfassende Metriken, Regressionstests und detailliertes Tracing, um eine konsistente KI-Leistung zu gewährleisten.
CrewAI
CrewAI ist ein fortschrittliches Open-Source-Framework zur Orchestrierung von rollenbasierten, autonomen KI-Agenten. Durch die Förderung kollaborativer Intelligenz ermöglicht es …
CrewAI ist ein fortschrittliches Open-Source-Framework zur Orchestrierung von rollenbasierten, autonomen KI-Agenten. Durch die Förderung kollaborativer Intelligenz ermöglicht es Agenten mit unterschiedlichen Rollen und Werkzeugen, nahtlos zusammenzuarbeiten, um komplexe Aufgaben zu lösen. Dieses Multi-Agenten-System vereinfacht die Entwicklung anspruchsvoller Anwendungen, von der automatisierten Inhaltserstellung bis zur komplexen Datenanalyse, indem es Agenteninteraktionen, Aufgaben-Delegation und Workflow-Prozesse verwaltet.
CopilotKit
CopilotKit ist ein Open-Source-Full-Stack-Framework für Entwickler, um In-App-KI-Copiloten und agentische Anwendungen zu erstellen, bereitzustellen und anzupassen. Es bietet …
CopilotKit ist ein Open-Source-Full-Stack-Framework für Entwickler, um In-App-KI-Copiloten und agentische Anwendungen zu erstellen, bereitzustellen und anzupassen. Es bietet Frontend-Komponenten, Backend-Logik und nahtlose Integrationen mit jedem LLM oder Agenten-Framework und ermöglicht die Erstellung leistungsstarker, benutzerorientierter KI-Assistenten.
phidata
phidata ist ein Open-Source-Python-Framework zum Erstellen autonomer KI-Assistenten. Es vereinfacht die Integration von LLMs mit Gedächtnis, Wissensdatenbanken und …
phidata ist ein Open-Source-Python-Framework zum Erstellen autonomer KI-Assistenten. Es vereinfacht die Integration von LLMs mit Gedächtnis, Wissensdatenbanken und externen Tools und ermöglicht es Entwicklern, mühelos leistungsstarke, zustandsbehaftete KI-Anwendungen zu erstellen.
Blaxel
Blaxel ist eine serverlose Computing-Plattform für KI-Entwickler, die die Infrastruktur und Werkzeuge zum effizienten Erstellen, Bereitstellen und Skalieren …
Blaxel ist eine serverlose Computing-Plattform für KI-Entwickler, die die Infrastruktur und Werkzeuge zum effizienten Erstellen, Bereitstellen und Skalieren von agentenbasierten KI-Anwendungen bietet. Sie verfügt über gesandboxte VMs, ein einheitliches LLM-Gateway und tiefgehende Beobachtbarkeit.
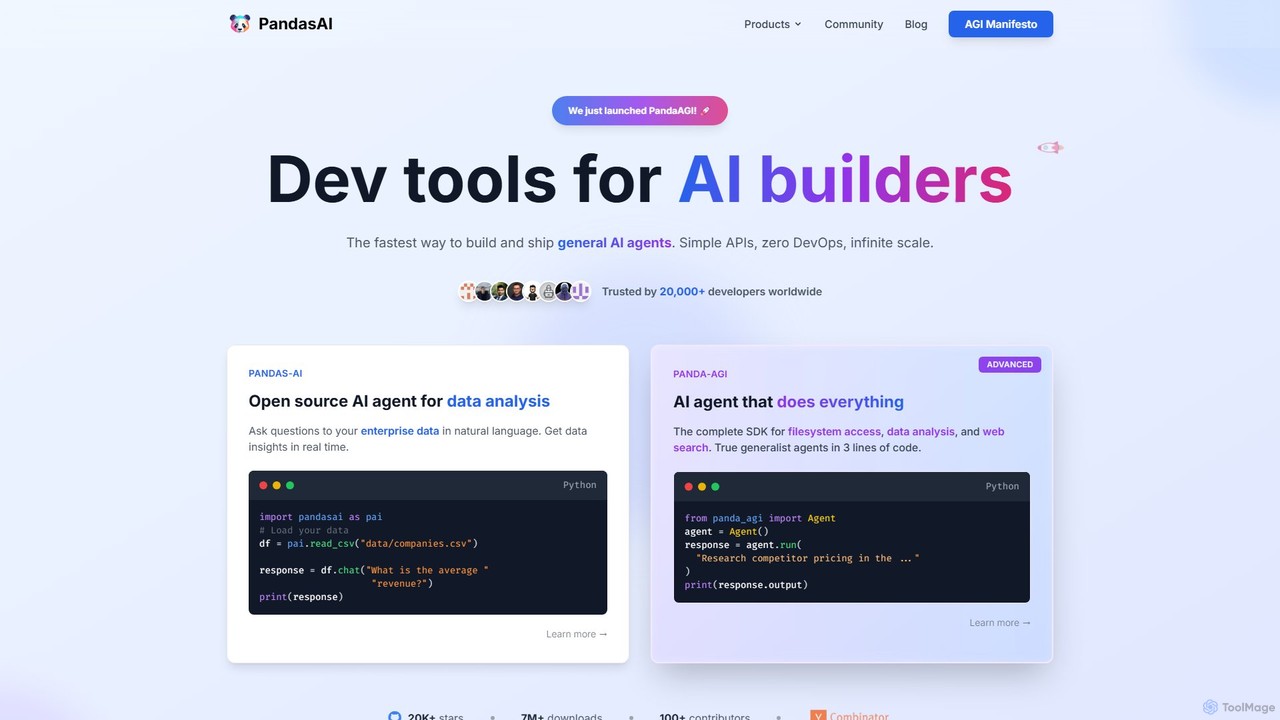
PandasAI
PandasAI bietet eine Suite von Entwickler-Tools zum Erstellen von KI-Anwendungen. Es umfasst eine Open-Source-Bibliothek für die konversationelle Datenanalyse …
PandasAI bietet eine Suite von Entwickler-Tools zum Erstellen von KI-Anwendungen. Es umfasst eine Open-Source-Bibliothek für die konversationelle Datenanalyse mittels natürlicher Sprache und PandaAGI, ein fortschrittliches SDK zur Erstellung generalistischer KI-Agenten, die komplexe Aufgaben wie Websuchen und Dateisystemzugriffe durchführen können.
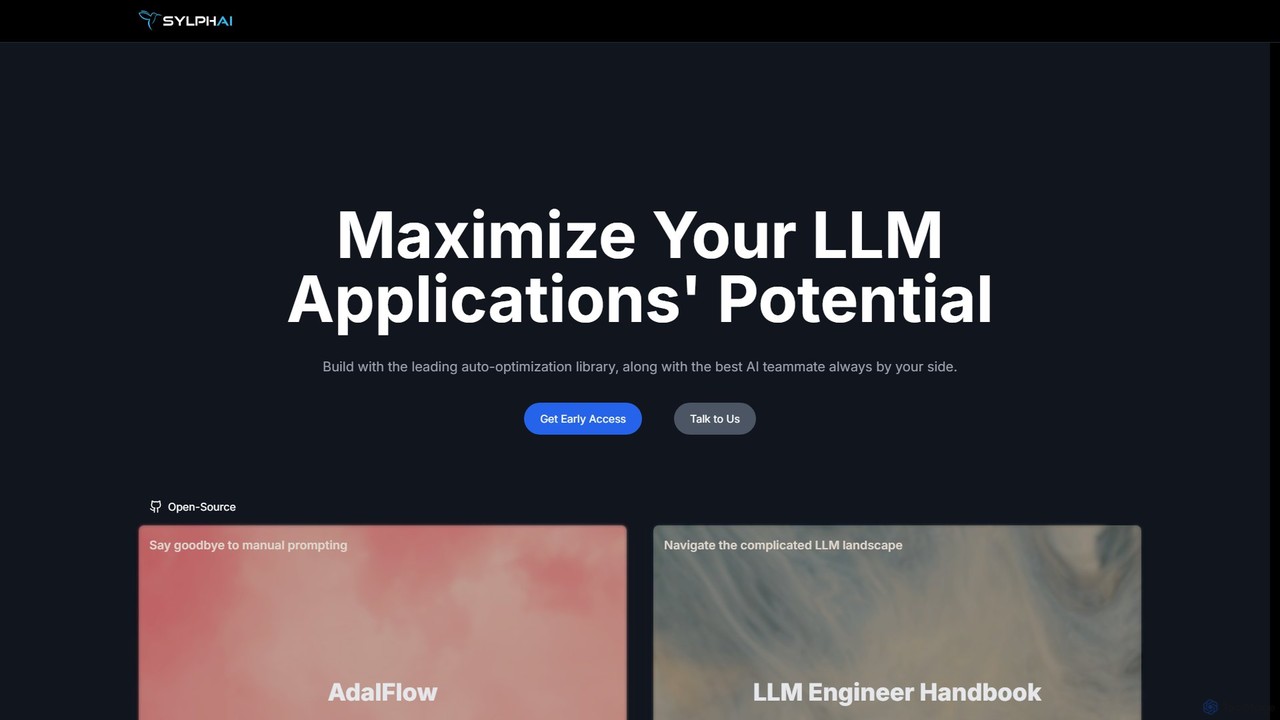
Sylph AI
Sylph AI ist eine Entwicklungsplattform, die darauf ausgelegt ist, das Potenzial von LLM-Anwendungen zu maximieren. Sie bietet AdalFlow, …
Sylph AI ist eine Entwicklungsplattform, die darauf ausgelegt ist, das Potenzial von LLM-Anwendungen zu maximieren. Sie bietet AdalFlow, eine führende Open-Source-Bibliothek zum Erstellen und automatischen Optimieren von LLM-Task-Pipelines, sowie einen KI-Teamkollegen, der während des gesamten Entwicklungsworkflows, von der Idee bis zur Produktion, fachkundige Anleitung bietet.
BenchLLM Kategorie
BenchLLM Tags
BenchLLM KI-Tool
BenchLLM Einbettungsfunktion
Kopieren Sie einfach den Einbettungscode unten und fügen Sie das ansprechende Abzeichen in Ihren Blog, Artikel oder auf die offizielle Website Ihrer App ein, um den Traffic direkt auf die Detailseite dieses Tools zu leiten und so schnell die Sichtbarkeit und Nutzerzahlen zu steigern!

Noch keine Kommentare, seien Sie der Erste!