Plurai
Plurai ist eine KI-Agent-Vertrauensplattform, die die Entwicklung produktionsbereiter Agenten durch Simulation, Bewertung und Guardrails beschleunigt. Sie reduziert Fehlerraten, …
Plurai ist eine KI-Agent-Vertrauensplattform, die die Entwicklung produktionsbereiter Agenten durch Simulation, Bewertung und Guardrails beschleunigt. Sie reduziert Fehlerraten, Richtlinienverstöße und Kosten erheblich im Vergleich zu großen Sprachmodellen.
Agenta
Agenta ist eine Open-Source-LLMOps-Plattform, die für Teams entwickelt wurde, um zuverlässige LLM-Anwendungen zu erstellen. Sie integriert Prompt-Management, systematische …
Agenta ist eine Open-Source-LLMOps-Plattform, die für Teams entwickelt wurde, um zuverlässige LLM-Anwendungen zu erstellen. Sie integriert Prompt-Management, systematische Evaluierung und Beobachtbarkeit in einen einzigen, kollaborativen Workflow und hilft Entwicklern, Produktmanagern und Fachexperten, von verstreuten Prozessen zu einer strukturierten Entwicklung überzugehen.
Athina
Athina ist eine kollaborative KI-Entwicklungsplattform, die Teams dabei unterstützt, LLM-Anwendungen 10x schneller zu erstellen, zu testen und zu …
Athina ist eine kollaborative KI-Entwicklungsplattform, die Teams dabei unterstützt, LLM-Anwendungen 10x schneller zu erstellen, zu testen und zu überwachen. Sie bietet eine umfassende Suite von Werkzeugen für Prompt-Engineering, Evaluierung, Experimente, Annotation und Produktionsüberwachung. Athina unterstützt sowohl technische als auch nicht-technische Benutzer und gewährleistet eine nahtlose Zusammenarbeit und die Bereitstellung hochwertiger, zuverlässiger KI-Systeme.

LangWatch
LangWatch ist eine All-in-One-Open-Source-Plattform zur Überwachung, Bewertung und Optimierung von LLM-Anwendungen. Sie ist auf das Testen von KI-Agenten …
LangWatch ist eine All-in-One-Open-Source-Plattform zur Überwachung, Bewertung und Optimierung von LLM-Anwendungen. Sie ist auf das Testen von KI-Agenten in simulierten Benutzerumgebungen spezialisiert und hilft Teams, Regressionen und Grenzfälle vor der Produktion zu erkennen. Die Plattform kombiniert Beobachtbarkeit, Bewertung, Optimierung und Leitplanken, um zuverlässige, sichere und leistungsstarke KI-Anwendungen zu gewährleisten.
deepchecks
Deepchecks ist eine End-to-End-Plattform zur Evaluierung, Validierung und Überwachung von LLM-basierten Anwendungen. Sie hilft KI-Teams, den Fortschritt der …
Deepchecks ist eine End-to-End-Plattform zur Evaluierung, Validierung und Überwachung von LLM-basierten Anwendungen. Sie hilft KI-Teams, den Fortschritt der KI zu definieren, zu messen und zu validieren und gewährleistet die Veröffentlichung hochwertiger, zuverlässiger Anwendungen durch die Optimierung von Tests von der Entwicklung über CI/CD bis zur Produktion.
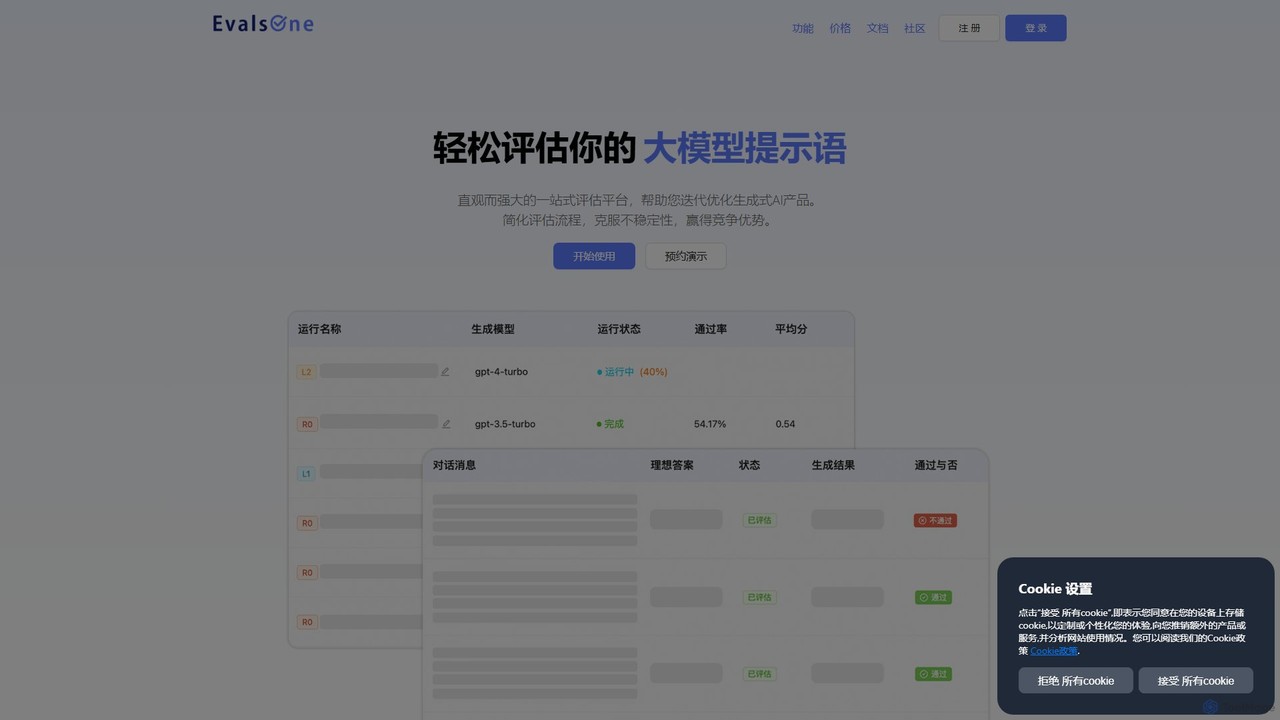
EvalsOne
EvalsOne ist eine All-in-One-Evaluierungsplattform für generative KI-Anwendungen. Sie ermöglicht es Teams, LLM-Prompts, RAG-Pipelines und KI-Agenten mühelos über eine …
EvalsOne ist eine All-in-One-Evaluierungsplattform für generative KI-Anwendungen. Sie ermöglicht es Teams, LLM-Prompts, RAG-Pipelines und KI-Agenten mühelos über eine leistungsstarke, intuitive Benutzeroberfläche zu bewerten, zu iterieren und zu optimieren, um robuste und wettbewerbsfähige KI-Produkte zu gewährleisten.

Prompt Octopus
Eine VSCode-Erweiterung für Entwickler zur Optimierung des Prompt-Engineerings. Sie ermöglicht den direkten Vergleich von Antworten von über 40 …
Eine VSCode-Erweiterung für Entwickler zur Optimierung des Prompt-Engineerings. Sie ermöglicht den direkten Vergleich von Antworten von über 40 LLMs (wie OpenAI, Anthropic, Mistral) nebeneinander in der Codebasis und hilft Ihnen, effizient das beste Modell für jede Aufgabe zu finden.
usevelvet
Velvet ist ein Entwickler-Gateway, jetzt Teil von Arize AI, das für die Analyse, Bewertung und Überwachung von KI-gestützten …
Velvet ist ein Entwickler-Gateway, jetzt Teil von Arize AI, das für die Analyse, Bewertung und Überwachung von KI-gestützten Funktionen entwickelt wurde. Es bietet eine umfassende Suite für KI-Beobachtbarkeit, LLM-Tracing und Modellleistungsmanagement, die Entwicklern hilft, KI-Anwendungen von der Entwicklung bis zur Produktion zu erstellen und zu perfektionieren.

Ragas
Ragas ist ein Open-Source-Python-Framework zur Evaluierung und zum Testen von Retrieval-Augmented Generation (RAG)-Pipelines. Es bietet eine Reihe von …
Ragas ist ein Open-Source-Python-Framework zur Evaluierung und zum Testen von Retrieval-Augmented Generation (RAG)-Pipelines. Es bietet eine Reihe von Metriken zur Messung der Leistung Ihrer LLM-Anwendungen, von der Kontextabfrage bis zur Antwortgenerierung. Ragas wird von Branchenführern wie LangChain und LlamaIndex geschätzt und hilft Entwicklern, robustere, zuverlässigere und genauere KI-Systeme zu erstellen, indem es Probleme wie Halluzinationen und irrelevante Antworten identifiziert und abschwächt.
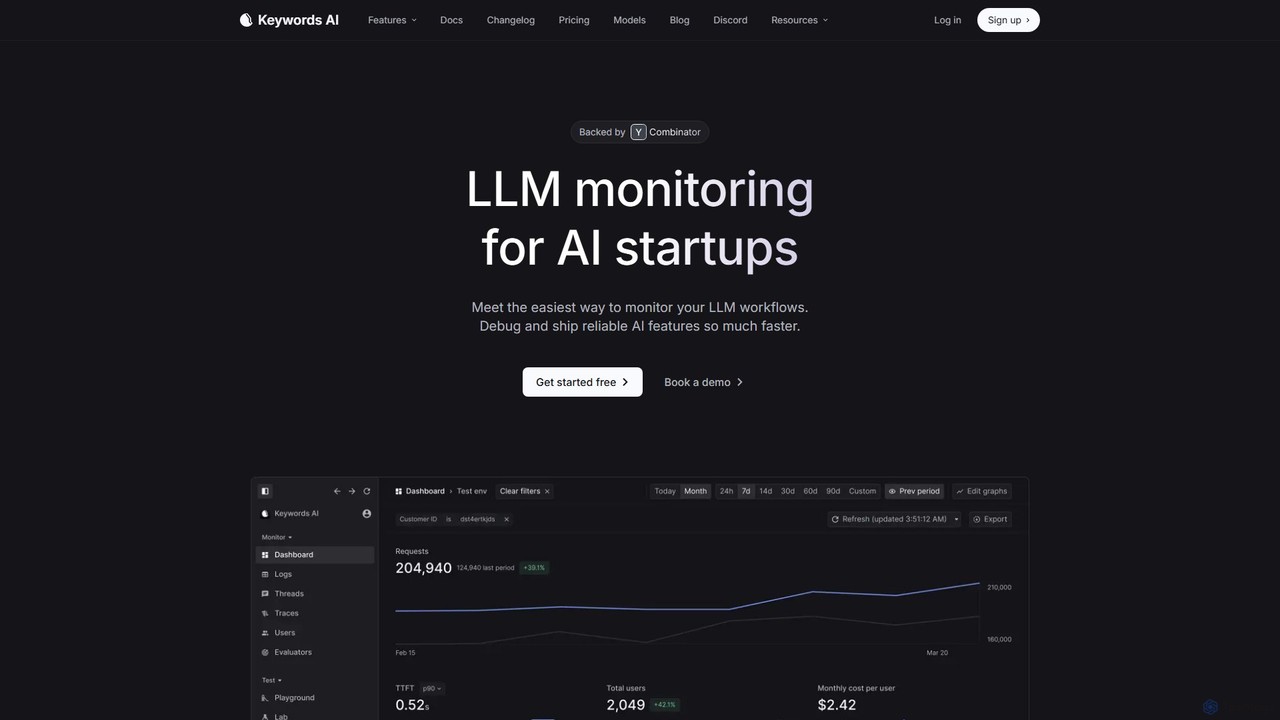
Keywords AI
Keywords AI ist eine umfassende LLM-Observability- und Monitoring-Plattform für KI-Startups und Entwickler. Sie bietet eine einheitliche API zum …
Keywords AI ist eine umfassende LLM-Observability- und Monitoring-Plattform für KI-Startups und Entwickler. Sie bietet eine einheitliche API zum Bereitstellen, Testen, Überwachen und Optimieren von LLM-Workflows, unterstützt über 200 Modelle und ermöglicht mit einer einfachen Zwei-Zeilen-Integration, dass Teams zuverlässige KI-Funktionen schneller entwickeln und ausliefern können.
withpi.ai
Eine auf Entwickler ausgerichtete Plattform zur Erstellung anpassbarer, schneller und kostengünstiger Bewertungs- und Evaluationssysteme für KI-Anwendungen. Sie wandelt …
Eine auf Entwickler ausgerichtete Plattform zur Erstellung anpassbarer, schneller und kostengünstiger Bewertungs- und Evaluationssysteme für KI-Anwendungen. Sie wandelt qualitative Kriterien in präzise, quantitative Metriken für Modellüberwachung, Ranking und RAG-Optimierung um.
Basalt
Basalt ist eine End-to-End-Plattform für Entwickler und Produktteams zum Erstellen, Bewerten und Überwachen zuverlässiger KI-Agenten. Sie bietet eine …
Basalt ist eine End-to-End-Plattform für Entwickler und Produktteams zum Erstellen, Bewerten und Überwachen zuverlässiger KI-Agenten. Sie bietet eine umfassende Suite von Tools, einschließlich automatisierter Bewertungen, A/B-Tests, Prompt-Engineering mit einem KI-Copiloten und einem entwicklerfreundlichen SDK, um sicherzustellen, dass Ihre KI-Funktionen vertrauenswürdig und produktionsreif sind.
Evidently AI
Evidently AI ist eine umfassende Test- und Evaluierungsplattform für KI-Produkte, spezialisiert auf das Monitoring von LLM- und ML-Modellen. …
Evidently AI ist eine umfassende Test- und Evaluierungsplattform für KI-Produkte, spezialisiert auf das Monitoring von LLM- und ML-Modellen. Sie hilft Teams, die Sicherheit, Zuverlässigkeit und Leistung von KI durch automatisierte Evaluierung, Generierung synthetischer Daten, kontinuierliche Tests und adversarische Angriffe zu gewährleisten. Basierend auf einer leistungsstarken Open-Source-Bibliothek ist sie für Datenwissenschaftler und MLOps-Ingenieure konzipiert, um Probleme wie Halluzinationen, Daten-Drift und PII-Lecks zu erkennen, bevor sie Benutzer beeinträchtigen.

Adaline
Adaline ist eine End-to-End-Plattform für Produkt- und Engineering-Teams zum Iterieren, Evaluieren, Bereitstellen und Überwachen von Large Language Models …
Adaline ist eine End-to-End-Plattform für Produkt- und Engineering-Teams zum Iterieren, Evaluieren, Bereitstellen und Überwachen von Large Language Models (LLMs). Sie optimiert den gesamten Lebenszyklus von KI-Anwendungen und ermöglicht eine schnellere Entwicklung, verbesserte Zusammenarbeit und eine zuverlässige Bereitstellung von KI-gestützten Funktionen.
Confident AI
Confident AI ist eine LLM-Evaluierungs- und Beobachtbarkeitsplattform für Ingenieurteams. Entwickelt von den Schöpfern der Open-Source-Bibliothek DeepEval, hilft es …
Confident AI ist eine LLM-Evaluierungs- und Beobachtbarkeitsplattform für Ingenieurteams. Entwickelt von den Schöpfern der Open-Source-Bibliothek DeepEval, hilft es beim Benchmarking, Absichern und Verbessern von LLM-Anwendungen durch umfassende Metriken, Regressionstests und detailliertes Tracing, um eine konsistente KI-Leistung zu gewährleisten.
RagaAI
RagaAI ist eine umfassende KI-Test- und Beobachtbarkeitsplattform, die Entwicklern und Unternehmen hilft, zuverlässige KI-Anwendungen zu erstellen. Sie bietet …
RagaAI ist eine umfassende KI-Test- und Beobachtbarkeitsplattform, die Entwicklern und Unternehmen hilft, zuverlässige KI-Anwendungen zu erstellen. Sie bietet eine Reihe von Werkzeugen zur Beobachtung, Bewertung und Fehlerbehebung von KI-Agenten, LLMs und RAG-Systemen. Zu den Hauptfunktionen gehören agentenbasiertes Testen, Echtzeit-Leitplanken (Guardrails), die Generierung synthetischer Daten und Feinabstimmungsfunktionen. RagaAI unterstützt multimodale Daten (LLMs, Computer Vision, tabellarische Daten) und zielt darauf ab, den gesamten Lebenszyklus der KI-Qualitätssicherung zu automatisieren, von der Problemerkennung bis zur Lösung, um robuste und vertrauenswürdige KI-Implementierungen zu gewährleisten.
AfterQuery
AfterQuery ist ein KI-Forschungslabor, das sich der Weiterentwicklung von Foundational Models durch die Erstellung hochwertiger, von Menschen erzeugter …
AfterQuery ist ein KI-Forschungslabor, das sich der Weiterentwicklung von Foundational Models durch die Erstellung hochwertiger, von Menschen erzeugter Datensätze und kontaminationsfreier Benchmarks widmet. Es konzentriert sich auf die Verbesserung der Modellleistung durch überlegene Trainingsdaten und rigorose Evaluierung.
promptfoo
promptfoo ist ein umfassendes Test- und Evaluierungs-Framework für große Sprachmodelle (LLMs). Es hilft Entwicklern und Unternehmen, die Qualität …
promptfoo ist ein umfassendes Test- und Evaluierungs-Framework für große Sprachmodelle (LLMs). Es hilft Entwicklern und Unternehmen, die Qualität von Prompts zu vergleichen, die Modellleistung zu bewerten und die KI-Sicherheit durch systematisches Testen, Benchmarking und KI-gestütztes Red Teaming zu verbessern. Es unterstützt über 50 LLM-Anbieter, einschließlich lokaler Modelle, und bietet eine entwicklerfreundliche CLI für eine nahtlose Integration in Entwicklungsworkflows.
BenchLLM
Ein leistungsstarkes Open-Source-Framework für KI-Ingenieure zur Bewertung und zum Testen von Anwendungen mit Großen Sprachmodellen (LLM). BenchLLM bietet …
Ein leistungsstarkes Open-Source-Framework für KI-Ingenieure zur Bewertung und zum Testen von Anwendungen mit Großen Sprachmodellen (LLM). BenchLLM bietet eine flexible API und eine robuste CLI zum Erstellen von Testsuiten, Generieren von Qualitätsberichten und Integrieren der Modellevaluierung in CI/CD-Pipelines, um vorhersagbare und qualitativ hochwertige Ergebnisse zu gewährleisten.
getmaxim
getmaxim ist eine umfassende GenAI-Evaluierungs- und Beobachtbarkeitsplattform für KI-Entwicklungsteams. Sie ermöglicht es Benutzern, KI-Anwendungen zu testen, zu überwachen …
getmaxim ist eine umfassende GenAI-Evaluierungs- und Beobachtbarkeitsplattform für KI-Entwicklungsteams. Sie ermöglicht es Benutzern, KI-Anwendungen zu testen, zu überwachen und zu verbessern, indem sie umfangreiche Evaluierungen von LLMs und RAG-Pipelines durchführt, Tests automatisiert und Echtzeit-Produktionsüberwachung bereitstellt, um hochwertige, zuverlässige und verantwortungsvolle KI zu gewährleisten.
Giskard
Giskard ist eine KI-Testplattform, die zur Sicherung und Validierung von LLM-basierten Anwendungen entwickelt wurde. Sie hilft Unternehmensteams, Risiken …
Giskard ist eine KI-Testplattform, die zur Sicherung und Validierung von LLM-basierten Anwendungen entwickelt wurde. Sie hilft Unternehmensteams, Risiken wie Halluzinationen, Sicherheitslücken, Voreingenommenheit und Leistungsprobleme vor der Bereitstellung zu erkennen und zu mindern. Durch die Automatisierung der Testgenerierung und kontinuierliches Red Teaming stellt Giskard sicher, dass KI-Agenten zuverlässig, sicher und konform sind.