pdfparser
Website besuchen
pdfparser Übersicht
pdfparser ist ein spezialisiertes, leistungsstarkes Werkzeug, das entwickelt wurde, um die in PDF-Dateien gefangenen Daten freizusetzen. Durch den Einsatz fortschrittlicher KI und optischer Zeichenerkennung (OCR) bietet es eine einfache, aber leistungsstarke Lösung zur Umwandlung von unstrukturiertem PDF-Inhalt in strukturierte, verwertbare Daten. Egal, ob Sie mit nativen oder gescannten PDFs, Rechnungen, Berichten oder Formularen arbeiten, pdfparser automatisiert den Extraktionsprozess, spart unzählige Stunden manueller Dateneingabe und reduziert menschliche Fehler. Die primäre Ausgabe ist sauberes, gut organisiertes JSON, was es für Entwickler unglaublich einfach macht, es in jede Anwendung oder Datenverarbeitungspipeline zu integrieren.
Wie man pdfparser verwendet
Die Verwendung von pdfparser ist als unkomplizierter Prozess konzipiert, der über seine API für eine nahtlose Integration in Ihre Projekte zugänglich ist.
- Anmelden und Credits erhalten: Erstellen Sie ein Konto auf der pdfparser-Website und kaufen Sie ein Credit-Paket, das Ihren Bedürfnissen entspricht. Ein Credit entspricht der Verarbeitung eines Dokuments.
- API-Integration: Verwenden Sie Ihren einzigartigen API-Schlüssel, um Ihre Anfragen zu authentifizieren. Die Dokumentation bietet klare Beispiele für API-Aufrufe.
- Senden Sie Ihr PDF: Senden Sie eine POST-Anfrage an den pdfparser-API-Endpunkt und fügen Sie die zu verarbeitende PDF-Datei in den Anforderungskörper ein.
- KI-gestützte Verarbeitung: Das Backend des Dienstes analysiert das Dokument automatisch. Es erkennt das Layout, identifiziert Textblöcke, erkennt Tabellen und verwendet OCR für jeden bildbasierten Text.
- Strukturiertes JSON erhalten: Die API gibt ein detailliertes JSON-Objekt zurück, das alle extrahierten Inhalte enthält, einschließlich des Rohtextes, strukturierter Tabellendaten (mit Zeilen und Spalten) und Metadaten zum Dokument.
Kernfunktionen von pdfparser
- Fortschrittliche OCR-Engine: Extrahiert präzise Text aus gescannten Dokumenten, Bildern mit niedriger Auflösung und komplexen Layouts und unterstützt mehrere Sprachen.
- Intelligente Tabellenextraktion: Erkennt automatisch Tabellen in PDFs und behält ihre Struktur bei, indem Zeilen und Spalten in ein verschachteltes JSON-Array umgewandelt werden, um das Parsen zu erleichtern.
- Strukturierte JSON-Ausgabe: Alle extrahierten Daten werden in einem sauberen, vorhersagbaren und entwicklerfreundlichen JSON-Format geliefert, das sofort in Datenbanken, Anwendungen oder Analysetools verwendet werden kann.
- Skalierbare API: Die robuste, für Entwickler entwickelte API kann hohe Dokumentenvolumina verarbeiten und ermöglicht die Stapelverarbeitung und Echtzeit-Datenextraktion in Unternehmensanwendungen.
- Einfaches Credit-basiertes System: Das transparente Pay-as-you-go-Preismodell ermöglicht es Ihnen, nur für das zu bezahlen, was Sie nutzen, was es sowohl für kleine Projekte als auch für große Operationen kostengünstig macht.
Anwendungsfälle für pdfparser
pdfparser ist ein vielseitiges Werkzeug, das in zahlreichen Branchen anwendbar ist:
- Finanzautomatisierung: Extrahieren Sie automatisch Daten aus Rechnungen, Bestellungen, Quittungen und Kontoauszügen, um die Buchhaltung zu optimieren.
- Datenwissenschaft & Forschung: Parsen Sie wissenschaftliche Arbeiten, Forschungsberichte und Datensätze aus PDFs, um Informationen für die Analyse ohne manuelle Transkription zu sammeln.
- Recht und Compliance: Extrahieren Sie schnell Klauseln, Falldetails und wichtige Informationen aus Verträgen, Gerichtsakten und regulatorischen Dokumenten.
- Logistik und Lieferkette: Digitalisieren Sie Frachtbriefe, Versandmanifeste und Lieferscheine, um die Nachverfolgung und Bestandsverwaltung zu automatisieren.
- Personalwesen: Verarbeiten Sie Lebensläufe und Bewerbungsformulare, um Kandidateninformationen zu extrahieren und HR-Managementsysteme zu befüllen.
Vorteile von pdfparser
Der Hauptvorteil von pdfparser liegt in seinem Fokus auf Einfachheit und Leistung. Es abstrahiert die Komplexität des PDF-Parsings und der OCR und bietet einen zuverlässigen Dienst, der einfach funktioniert. Dies führt zu deutlich schnelleren Entwicklungszyklen für Anwendungen, die auf Dokumentendaten angewiesen sind. Seine hohe Genauigkeit bei der Extraktion von Text und Tabellen minimiert die Notwendigkeit manueller Überprüfung und Korrektur. Das skalierbare, kreditbasierte Modell stellt sicher, dass Unternehmen jeder Größe eine unternehmenstaugliche Dokumentenverarbeitung ohne hohe Vorabinvestitionen nutzen können.
Preise und Pläne
pdfparser arbeitet mit einem unkomplizierten Pay-as-you-go-Credit-System, bei dem 1 Credit für das Parsen von 1 Dokument verwendet wird.
- Lite: 1,00 $ für 10 Credits
- Standard: 5,00 $ für 60 Credits
- Pro: 25,00 $ für 500 Credits
Zahlungen werden sicher per Karte oder PayPal abgewickelt. Diese flexible Preisgestaltung macht es für Entwickler, die eine Idee testen, kleine Unternehmen, die einen Workflow automatisieren, oder große Unternehmen, die Dokumente in großem Maßstab verarbeiten, zugänglich.
pdfparser Kommentare (0)
Melden Sie sich an, um einen Kommentar zu hinterlassen
Jetzt anmeldenpdfparser Alternativen
Alle anzeigen
Finigami AI
Finigami AI bietet KI-Lösungen für Unternehmen an, die auf intelligente Dokumentenverarbeitung (IDP) und benutzerdefinierte KI-Entwicklung spezialisiert sind. Es …
Finigami AI bietet KI-Lösungen für Unternehmen an, die auf intelligente Dokumentenverarbeitung (IDP) und benutzerdefinierte KI-Entwicklung spezialisiert sind. Es bietet eine leistungsstarke Plattform zur Extraktion von Daten aus beliebigen Dokumenten, einschließlich handschriftlicher Texte und komplexer Tabellen, und arbeitet mit Unternehmen zusammen, um maßgeschneiderte KI-Systeme für Bereiche wie Finanzen, Personalwesen und Betrieb zu entwickeln.
CambioML
CambioML bietet die AnyParser API, ein leistungsstarkes Vision LLM, das für hochpräzises Dokumenten-Parsing entwickelt wurde. Es extrahiert Text, …
CambioML bietet die AnyParser API, ein leistungsstarkes Vision LLM, das für hochpräzises Dokumenten-Parsing entwickelt wurde. Es extrahiert Text, Tabellen, Diagramme und Schlüssel-Wert-Paare aus PDFs, Bildern und Office-Dokumenten. Mit Funktionen wie PII-Schwärzung, konfigurierbaren Ausgaben und Echtzeitverarbeitung ist es ideal für Entwickler und Unternehmen in den Bereichen Finanzen, Forschung und Datenanalyse, um Datenextraktions-Workflows zu automatisieren und dabei Datenschutz und Effizienz zu gewährleisten.
hand_check
hand_check ist ein fortschrittliches OCR-Tool, das maschinelles Lernen nutzt, um Text aus PDFs und Bildern zu extrahieren. Es …
hand_check ist ein fortschrittliches OCR-Tool, das maschinelles Lernen nutzt, um Text aus PDFs und Bildern zu extrahieren. Es ist spezialisiert auf die Konvertierung komplexer Dokumente, einschließlich handschriftlicher Notizen und Tabellen, in bearbeitbaren Text oder strukturierte JSON-Daten. Mit einer benutzerfreundlichen Oberfläche und einer leistungsstarken API für Entwickler ist es ideal für Einzelpersonen, Entwickler und Unternehmen, die die Dokumentenverarbeitung und Datenextraktion automatisieren möchten.
Sensible
Sensible ist eine API-first-Plattform für intelligente Dokumentenverarbeitung für Entwickler. Sie nutzt fortschrittliches LLM-Parsing und visuelle layoutbasierte Regeln, um …
Sensible ist eine API-first-Plattform für intelligente Dokumentenverarbeitung für Entwickler. Sie nutzt fortschrittliches LLM-Parsing und visuelle layoutbasierte Regeln, um strukturierte Daten aus beliebigen Dokumenten wie PDFs, Bildern und Tabellenkalkulationen präzise zu extrahieren. Sie ist für nahtlose Integration, Skalierbarkeit und unternehmenstaugliche Sicherheit, einschließlich SOC 2- und HIPAA-Konformität, konzipiert.
Monkt
Monkt ist eine KI-gestützte Plattform, die Dokumente und Websites in sauberes, KI-fähiges Markdown oder strukturiertes JSON umwandelt. Es …
Monkt ist eine KI-gestützte Plattform, die Dokumente und Websites in sauberes, KI-fähiges Markdown oder strukturiertes JSON umwandelt. Es unterstützt verschiedene Formate wie PDF, Word und Excel und bietet Funktionen wie OCR, Stapelverarbeitung und eine REST-API zur Automatisierung der Datenextraktion und zur Vorbereitung von Datensätzen für das LLM-Training.
Doctly
Doctly ist ein KI-gestütztes Werkzeug, das Daten aus PDFs und anderen Dokumenten präzise extrahiert. Es wandelt Text, Tabellen, …
Doctly ist ein KI-gestütztes Werkzeug, das Daten aus PDFs und anderen Dokumenten präzise extrahiert. Es wandelt Text, Tabellen, Abbildungen und Diagramme in strukturiertes Markdown oder JSON um und bewahrt dabei die ursprüngliche Formatierung. Mit einer einfachen API und hoher Präzision ist es für Entwickler und Unternehmen konzipiert, um Dokumentenverarbeitungs-Workflows zu automatisieren.
extracta.ai
extracta.ai ist eine KI-gestützte Plattform zur intelligenten Datenextraktion aus Dokumenten und Bildern. Sie automatisiert die Erfassung strukturierter Daten …
extracta.ai ist eine KI-gestützte Plattform zur intelligenten Datenextraktion aus Dokumenten und Bildern. Sie automatisiert die Erfassung strukturierter Daten aus verschiedenen Quellen wie Rechnungen, Belegen, Verträgen und Formularen, wodurch die manuelle Dateneingabe entfällt und Geschäftsprozesse optimiert werden.
Upstage
Upstage bietet hochleistungsfähige, unternehmenstaugliche KI-Modelle für Unternehmen. Die Suite umfasst das leistungsstarke Solar LLM für Sprachaufgaben, fortschrittliche Dokumenten-KI …
Upstage bietet hochleistungsfähige, unternehmenstaugliche KI-Modelle für Unternehmen. Die Suite umfasst das leistungsstarke Solar LLM für Sprachaufgaben, fortschrittliche Dokumenten-KI zum Parsen und Extrahieren von Daten mit hoher Genauigkeit sowie flexible Bereitstellungsoptionen (API, On-Premise, Cloud) zur Automatisierung komplexer Arbeitsabläufe.
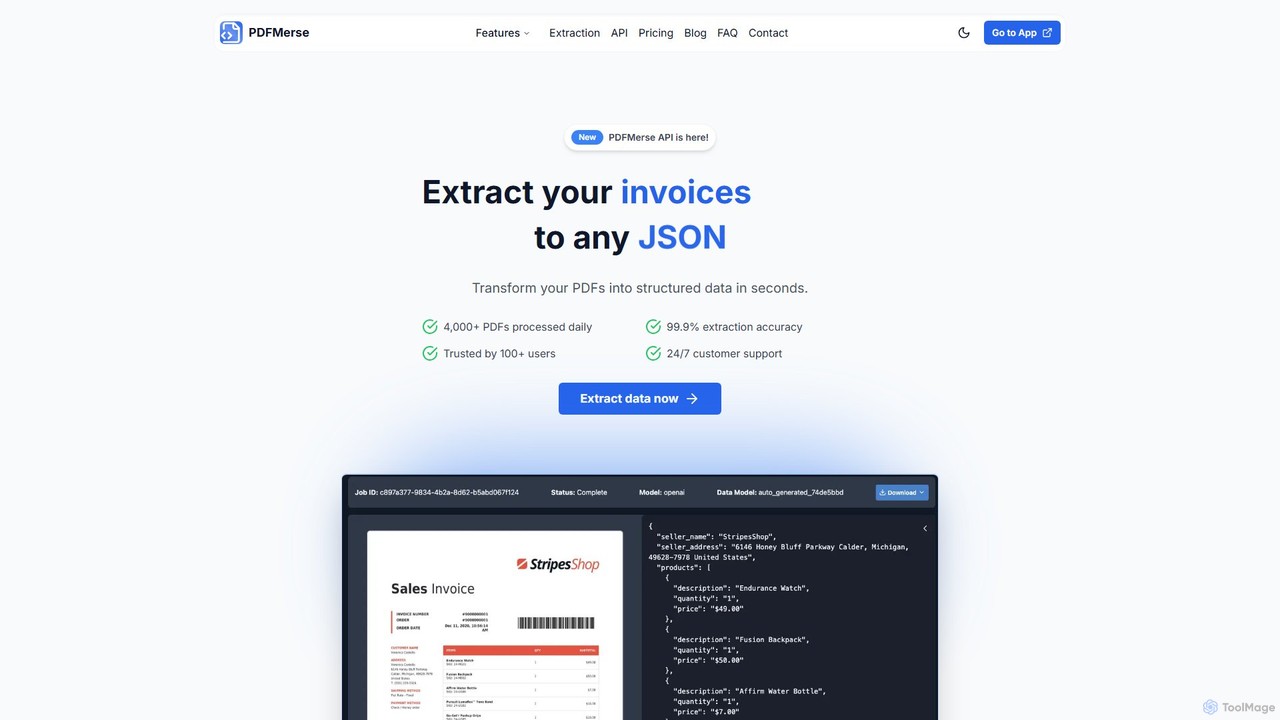
pdfmerse
pdfmerse ist ein KI-gestützter Datenextraktor, der den Prozess der Informationserfassung aus jedem PDF-Dokument automatisiert. Er wandelt unstrukturierte PDF-Daten …
pdfmerse ist ein KI-gestützter Datenextraktor, der den Prozess der Informationserfassung aus jedem PDF-Dokument automatisiert. Er wandelt unstrukturierte PDF-Daten intelligent in strukturierte Formate wie JSON und Text um. Ideal für Unternehmen und Einzelpersonen, die die Dokumentenverarbeitung optimieren, die manuelle Dateneingabe reduzieren und die Workflow-Effizienz mit hoher Genauigkeit verbessern möchten.

FormX.ai
FormX.ai ist eine KI-gestützte Plattform, die die Datenextraktion aus beliebigen Dokumenten automatisiert. Sie nutzt fortschrittliche KI, einschließlich LLMs …
FormX.ai ist eine KI-gestützte Plattform, die die Datenextraktion aus beliebigen Dokumenten automatisiert. Sie nutzt fortschrittliche KI, einschließlich LLMs und Vision-Modelle, um Rechnungen, Belege, Ausweise und mehr zu verarbeiten, wodurch Geschäftsworkflows optimiert und die betriebliche Effizienz gesteigert werden.
pdfparser Kategorie
pdfparser Tags
pdfparser KI-Tool
pdfparser Einbettungsfunktion
Kopieren Sie einfach den Einbettungscode unten und fügen Sie das ansprechende Abzeichen in Ihren Blog, Artikel oder auf die offizielle Website Ihrer App ein, um den Traffic direkt auf die Detailseite dieses Tools zu leiten und so schnell die Sichtbarkeit und Nutzerzahlen zu steigern!

Noch keine Kommentare, seien Sie der Erste!