BlickState
BlickState es una herramienta avanzada de depuración de viaje en el tiempo para agentes de IA, que permite …
BlickState es una herramienta avanzada de depuración de viaje en el tiempo para agentes de IA, que permite a los desarrolladores restaurar e inspeccionar el estado completo de la memoria de las ejecuciones de herramientas de agente en el milisegundo exacto del fallo. Transforma el comportamiento de agente de caja negra en procesos transparentes e inspeccionables, acelerando significativamente la depuración para ingenieros de IA.
Flutch
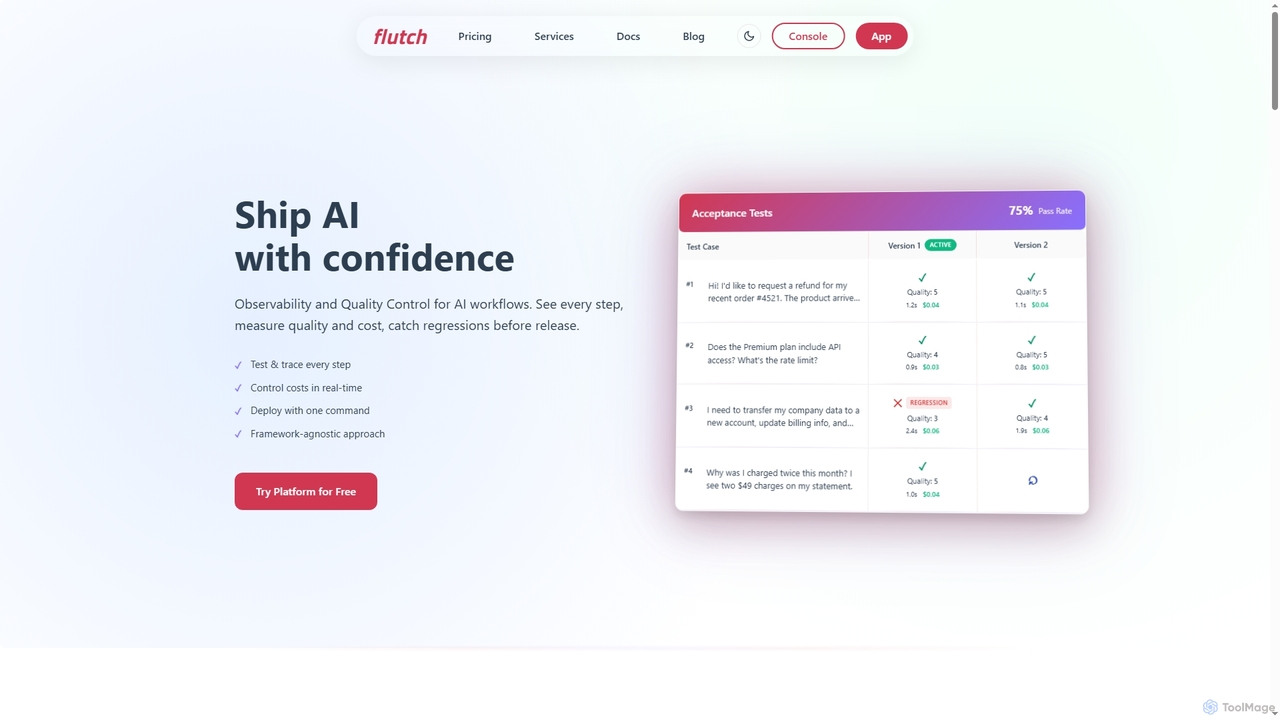
Flutch es una plataforma integral para desarrollar, implementar y gestionar agentes de IA personalizados con un fuerte enfoque …
Flutch es una plataforma integral para desarrollar, implementar y gestionar agentes de IA personalizados con un fuerte enfoque en la observabilidad, el control de calidad y la gestión de costos. Permite a los desarrolladores construir flujos de trabajo de IA confiables, probar agentes rigurosamente, monitorear el rendimiento en tiempo real e integrarse sin problemas en los sistemas existentes, asegurando que las soluciones de IA se entreguen con confianza y operen de manera eficiente.
Splunk
Splunk es la clave para la resiliencia empresarial, ofreciendo una plataforma unificada y impulsada por IA para la …
Splunk es la clave para la resiliencia empresarial, ofreciendo una plataforma unificada y impulsada por IA para la seguridad y la observabilidad. Permite a las organizaciones investigar, monitorear, analizar y actuar sobre datos de cualquier fuente a cualquier escala. Ahora, como empresa de Cisco, Splunk ayuda a los equipos de SecOps, ITOps e ingeniería a mantener sus sistemas digitales seguros y fiables en la era de la IA.
Metoro
Metoro es una plataforma de observabilidad impulsada por IA diseñada para Kubernetes. Utiliza tecnología eBPF para un monitoreo …
Metoro es una plataforma de observabilidad impulsada por IA diseñada para Kubernetes. Utiliza tecnología eBPF para un monitoreo sin instrumentación, permitiendo la detección autónoma de problemas, análisis de causa raíz y correcciones de código automatizadas a través de pull requests. Operativo en menos de un minuto, ofrece una alternativa completa y rentable a las herramientas de monitoreo tradicionales.
Middleware
Middleware es una plataforma de observabilidad en la nube full-stack impulsada por IA, diseñada para modernizar la infraestructura …
Middleware es una plataforma de observabilidad en la nube full-stack impulsada por IA, diseñada para modernizar la infraestructura de TI. Unifica registros, métricas, trazas y datos de RUM en una sola vista, permitiendo a los equipos monitorear todo su stack tecnológico en tiempo real. Con su función principal, OpsAI, Middleware detecta, diagnostica e incluso resuelve automáticamente hasta el 70% de los problemas, reduciendo significativamente el tiempo de resolución y mejorando la productividad de los desarrolladores. Ofrece una solución rentable y escalable para empresas de todos los tamaños.
Signal0ne
Signal0ne es una plataforma AIOps impulsada por IA que actúa como asistente de guardia para equipos de DevOps …
Signal0ne es una plataforma AIOps impulsada por IA que actúa como asistente de guardia para equipos de DevOps y SRE. Automatiza el análisis de causa raíz correlacionando señales de su pila de observabilidad existente, enriqueciendo alertas con contexto crucial y sugiriendo pasos de mitigación. Esto ayuda a los equipos a reducir la fatiga de alertas y a disminuir significativamente el Tiempo Medio de Resolución (MTTR).
Site24x7
Site24x7 es una plataforma de observabilidad todo en uno impulsada por IA para DevOps y operaciones de TI. …
Site24x7 es una plataforma de observabilidad todo en uno impulsada por IA para DevOps y operaciones de TI. Proporciona un monitoreo completo para sitios web, servidores, infraestructura en la nube (AWS, Azure, GCP), redes y aplicaciones desde una única consola. Ayuda a garantizar el tiempo de actividad, solucionar problemas de rendimiento y optimizar la experiencia del usuario.
Pezzo
Pezzo es una plataforma de IA de código abierto y centrada en el desarrollador, diseñada para agilizar todo …
Pezzo es una plataforma de IA de código abierto y centrada en el desarrollador, diseñada para agilizar todo el ciclo de vida del desarrollo de funciones de IA. Permite a los equipos construir, probar, monitorear y lanzar funciones impulsadas por IA hasta 10 veces más rápido a través de una gestión centralizada de prompts, observabilidad en tiempo real y herramientas colaborativas.
OpenLIT
OpenLIT es una plataforma de observabilidad de código abierto y nativa de OpenTelemetry para aplicaciones de IA Generativa …
OpenLIT es una plataforma de observabilidad de código abierto y nativa de OpenTelemetry para aplicaciones de IA Generativa y LLM. Simplifica el desarrollo con herramientas para el seguimiento de solicitudes, control de costos, monitoreo de excepciones y análisis de rendimiento. Con un repositorio centralizado de prompts, una bóveda segura para secretos y un playground para comparar LLMs, OpenLIT ofrece una solución integral para monitorear y escalar aplicaciones de IA de manera eficiente.

Valyr
Valyr (anteriormente Helicone) es una plataforma de observabilidad de LLM de código abierto y puerta de enlace de …
Valyr (anteriormente Helicone) es una plataforma de observabilidad de LLM de código abierto y puerta de enlace de IA. Ayuda a los desarrolladores a monitorear, depurar y analizar sus aplicaciones de IA, proporcionando una única integración para acceder a más de 100 modelos, gestionar costos y mejorar la fiabilidad con funciones como el almacenamiento en caché y la limitación de velocidad.
Mezmo
Mezmo es una plataforma integral de pipeline de datos de telemetría diseñada para desarrolladores, equipos de DevOps y …
Mezmo es una plataforma integral de pipeline de datos de telemetría diseñada para desarrolladores, equipos de DevOps y SRE. Permite a los usuarios ingerir, procesar y analizar registros, métricas y trazas de cualquier fuente. Con un enfoque en el control y la eficiencia de costos, Mezmo le permite filtrar, transformar y enrutar sus datos de observabilidad a cualquier destino, optimizando el rendimiento y reduciendo gastos.
Acerca de Observabilidad
Las herramientas de Observabilidad son soluciones impulsadas por IA diseñadas para proporcionar una visión profunda del estado interno y el comportamiento de sistemas de software complejos. Al recopilar y analizar métricas, registros y trazas, estas herramientas permiten a los equipos de desarrollo y operaciones comprender por qué ocurren los problemas, predecir posibles fallos y optimizar el rendimiento. Son esenciales para mantener la fiabilidad, eficiencia y resiliencia de las aplicaciones modernas, especialmente en entornos distribuidos y nativos de la nube.
Características Principales
- Ingesta Automatizada de Datos: Recopila automáticamente métricas, registros y trazas de diversas fuentes (aplicaciones, infraestructura, servicios).
- Monitoreo y Alertas en Tiempo Real: Proporciona paneles para la visualización en tiempo real del estado del sistema y activa alertas sobre anomalías o umbrales predefinidos.
- Trazado Distribuido: Rastrea las solicitudes a través de múltiples servicios para identificar cuellos de botella de latencia y puntos de fallo en arquitecturas de microservicios.
- Gestión y Análisis de Registros: Centraliza, indexa y analiza grandes volúmenes de datos de registro para la resolución de problemas y auditorías de seguridad.
- Detección de Anomalías Impulsada por IA: Utiliza el aprendizaje automático para identificar patrones inusuales en el comportamiento del sistema que podrían indicar problemas emergentes.
Escenarios de Aplicación
Las herramientas de Observabilidad son indispensables para SREs, ingenieros de DevOps y desarrolladores que gestionan sistemas en producción. Se utilizan para diagnosticar rápidamente la causa raíz de errores de aplicación, monitorear el rendimiento de microservicios y asegurar que se cumplan los objetivos de nivel de servicio (SLOs). Por ejemplo, un equipo de DevOps podría usar estas herramientas para identificar una fuga de memoria en un servicio específico después de un nuevo despliegue o para entender por qué una solicitud de usuario está experimentando alta latencia a través de varios componentes de backend.
Cómo Elegir
Al seleccionar una herramienta de Observabilidad, considere sus capacidades de recopilación de datos (métricas, registros, trazas), la integración con su pila tecnológica existente y la escalabilidad para manejar volúmenes de datos crecientes. Evalúe sus características de análisis y visualización en tiempo real, incluyendo paneles personalizables y mecanismos de alerta. Además, evalúe sus conocimientos impulsados por IA para la detección de anomalías y el análisis de la causa raíz, así como su modelo de precios basado en la ingesta y retención de datos.
ObservabilidadEscenario de uso
Diagnóstico más rápido de incidentes en producción
Los Ingenieros de Fiabilidad del Sitio (SREs) utilizan plataformas de observabilidad para identificar rápidamente la causa raíz de problemas críticos en producción. Al correlacionar métricas, registros y trazas a través de servicios distribuidos, pueden identificar rápidamente qué componente específico está fallando o experimentando degradación del rendimiento, reduciendo el tiempo medio de resolución (MTTR) y minimizando el tiempo de inactividad para los usuarios finales.
Optimización del rendimiento de microservicios
Los desarrolladores y equipos de DevOps aprovechan el trazado distribuido para visualizar el flujo completo de solicitudes a través de una compleja arquitectura de microservicios. Esto les permite identificar cuellos de botella de latencia, consultas de bases de datos ineficientes o llamadas a API lentas entre servicios, lo que posibilita optimizaciones dirigidas para mejorar la capacidad de respuesta general de la aplicación y la experiencia del usuario.
Detección proactiva de anomalías
Los equipos de operaciones implementan herramientas de observabilidad impulsadas por IA para detectar automáticamente patrones inusuales en el comportamiento del sistema que podrían indicar un problema inminente. Por ejemplo, un pico repentino en las tasas de error para una API específica o una caída inesperada en el rendimiento pueden ser señalados antes de que afecten a los usuarios, permitiendo una intervención proactiva y previniendo interrupciones.
Garantizar el cumplimiento y las auditorías de seguridad
Los responsables de seguridad y cumplimiento utilizan las funciones de gestión centralizada de registros para recopilar, almacenar y analizar los registros de auditoría de todos los componentes del sistema. Esto proporciona un rastro completo de actividades, ayudando a detectar intentos de acceso no autorizados, investigar incidentes de seguridad y demostrar el cumplimiento de requisitos normativos como GDPR o HIPAA.
Planificación de capacidad y gestión de recursos
Los ingenieros de infraestructura utilizan métricas de rendimiento históricas recopiladas por herramientas de observabilidad para comprender las tendencias de utilización de recursos (CPU, memoria, red). Estos datos informan decisiones estratégicas para la planificación de capacidad, asegurando que haya recursos suficientes disponibles para manejar cargas máximas mientras se evita el aprovisionamiento excesivo y los costos de infraestructura innecesarios.
Validación de nuevas implementaciones y características
Los equipos de desarrollo integran la observabilidad en sus pipelines de CI/CD para monitorear el impacto de nuevas implementaciones de código o lanzamientos de características en tiempo real. Al observar los indicadores clave de rendimiento (KPIs) y las tasas de error inmediatamente después de un despliegue, pueden identificar rápidamente regresiones o comportamientos inesperados e iniciar reversiones si es necesario, asegurando lanzamientos estables.