Groq
Visitar sitio web
Groq Visión general
Groq es una empresa de tecnología de IA que ha desarrollado una infraestructura innovadora para la inferencia de IA, diseñada desde cero para la velocidad, la calidad y la rentabilidad. En el corazón de la oferta de Groq se encuentra su Unidad de Procesamiento de Lenguaje (LPU™) patentada, un nuevo tipo de procesador construido específicamente para las demandas computacionales de ejecutar modelos de IA, particularmente grandes modelos de lenguaje (LLM). A diferencia de las GPU, que fueron adaptadas del procesamiento de gráficos, la LPU está diseñada específicamente para la inferencia, lo que le permite ofrecer una latencia predecible, por debajo del milisegundo, y un rendimiento excepcionalmente alto en tokens por segundo. Esto hace posible construir aplicaciones de IA conversacionales verdaderamente en tiempo real que antes eran inviables.
La tecnología es accesible a través de GroqCloud™, una plataforma de pila completa que permite a los desarrolladores y empresas aprovechar el poder de las LPU a través de una API simple y robusta. Groq admite una amplia gama de modelos populares de código abierto, incluidas varias versiones de Llama, Mistral, Qwen y Gemma, así como modelos especializados para el Reconocimiento Automático de Voz (ASR) como Whisper y de Texto a Voz (TTS). Este enfoque en la velocidad y la eficiencia tiene como objetivo impulsar una nueva ola de innovación al hacer que la IA de alto rendimiento sea accesible y asequible para una comunidad global de más de 1.9 millones de desarrolladores.
Cómo usar Groq
Empezar a usar Groq está diseñado para ser sencillo para los desarrolladores. El principal método de interacción es a través de la API de GroqCloud™.
- Regístrate: Crea una cuenta gratuita en el sitio web de Groq para acceder a la consola de desarrollador.
- Obtén la Clave de API: Una vez registrado, puedes generar una clave de API desde tu panel de control. Esta clave autenticará tus solicitudes.
- Integración: Con la clave de API, puedes comenzar a hacer llamadas a los puntos finales de los modelos de Groq. El proceso de integración es simple, a menudo requiere solo unas pocas líneas de código para reemplazar un punto final de API existente (por ejemplo, de OpenAI u otro proveedor) con el punto final de Groq. La plataforma proporciona documentación clara y SDK para facilitar este proceso.
- Elige un Modelo: Selecciona de una lista diversa de modelos LLM, ASR o TTS compatibles según las necesidades de tu aplicación en cuanto a velocidad, ventana de contexto y capacidad.
- Procesamiento por Lotes: Para tareas a gran escala y no en tiempo real, los desarrolladores pueden usar la API por Lotes. Esto permite enviar miles de solicitudes de forma asíncrona con una reducción de costo del 50%, sin afectar los límites de tasa estándar.
- Despliegue Empresarial: Para grandes empresas con necesidades específicas de seguridad o rendimiento, Groq también ofrece soluciones de despliegue en las propias instalaciones (on-premise).
Características principales de Groq
- Motor de Inferencia LPU™: Un procesador diseñado a medida específicamente para la inferencia de lenguaje de IA, que ofrece un rendimiento determinista y de latencia ultrabaja.
- Velocidad de Inferencia Inigualable: Alcanza velocidades líderes en la industria, a menudo medidas en cientos de tokens por segundo, lo que permite interacciones en tiempo real con grandes modelos.
- Plataforma GroqCloud™: Un servicio en la nube totalmente gestionado y escalable que proporciona acceso API a la infraestructura impulsada por LPU.
- Amplio Soporte de Modelos de Código Abierto: Ofrece una selección curada de LLMs de primer nivel (Llama, Mistral, Qwen), modelos ASR (Whisper) y modelos TTS.
- Precios Rentables: Un modelo de precios de pago por uso altamente competitivo basado en tokens, caracteres o tiempo, diseñado para ofrecer el menor costo por token sin sacrificar el rendimiento.
- API por Lotes: Una API asíncrona para procesar grandes cargas de trabajo con un descuento significativo, ideal para el procesamiento y análisis de datos sin conexión.
- Escalabilidad y Consistencia: La arquitectura garantiza que el rendimiento se mantenga constante y rápido, incluso a medida que aumentan el tráfico y las cargas de trabajo.
- API Amigable para el Desarrollador: Una API simple y fácil de integrar que es en gran medida compatible con los estándares existentes, lo que facilita el cambio y la construcción.
Casos de uso para Groq
La velocidad extrema de la LPU de Groq abre una amplia gama de aplicaciones que requieren respuestas de IA en tiempo real:
- IA Conversacional y Chatbots: Construcción de bots de servicio al cliente altamente receptivos, asistentes virtuales y compañeros interactivos que pueden entender y responder al instante.
- Creación de Contenido: Generación de publicaciones de blog, contenido para redes sociales, textos de marketing e incluso libros enteros en segundos.
- Transcripción y Resumen en Tiempo Real: Transcripción de audio de reuniones o eventos en vivo y generación de resúmenes sobre la marcha.
- Aplicaciones Controladas por Voz: Potenciando interfaces de usuario activadas por voz, redactando correos electrónicos mediante dictado y controlando software con comandos de voz.
- Herramientas de Aprendizaje Interactivas: Creación de planes de lecciones dinámicos y personalizados y viajes educativos que se adaptan a la entrada del usuario en tiempo real.
- Análisis Financiero: Desarrollo de agentes de IA que pueden proporcionar análisis de gráficos de acciones en vivo, resúmenes de noticias financieras y selección de mercados.
- Generación y Asistencia de Código: Proporcionando a los desarrolladores sugerencias de código instantáneas, ayuda para la depuración y explicaciones.
Ventajas de Groq
La principal ventaja de Groq reside en su hardware diseñado para un propósito específico, lo que se traduce en varios beneficios clave para los usuarios:
- Velocidad Asombrosa: Al eliminar los cuellos de botella de las arquitecturas de GPU tradicionales, Groq proporciona las velocidades de inferencia más rápidas del mercado, lo cual es crítico para las aplicaciones orientadas al usuario.
- Relación Precio-Rendimiento Superior: La eficiencia de la LPU permite a Groq ofrecer sus servicios a un costo menor por token, haciendo que la IA potente sea más económicamente viable para empresas de todos los tamaños.
- Rendimiento Predecible: A diferencia de algunos sistemas que se ralentizan bajo una carga pesada, la latencia de Groq se mantiene consistentemente baja, asegurando una experiencia de usuario confiable a cualquier escala.
- Tecnología a Prueba de Futuro: A medida que los modelos de IA se vuelven más grandes y complejos, la arquitectura especializada de Groq está diseñada para manejar la próxima generación de cargas de trabajo de IA de manera eficiente.
- Facilidad de Adopción: El enfoque centrado en el desarrollador con una API simple garantiza que los equipos puedan integrar rápidamente la velocidad de Groq en sus aplicaciones existentes o nuevas con un esfuerzo mínimo.
Precios y planes
Groq opera con un modelo de precios freemium y bajo demanda, lo que lo hace accesible para desarrolladores individuales y escalable para grandes empresas.
- Nivel Gratuito: Los usuarios pueden registrarse y comenzar a construir de forma gratuita para probar la plataforma y sus capacidades.
- Pago por Uso: Después del nivel gratuito, el precio es bajo demanda. Para los Grandes Modelos de Lenguaje (LLM), los costos se calculan por millón de tokens, con diferentes tarifas para los tokens de entrada y salida. Por ejemplo, un modelo rápido como Llama 3 8B tiene un precio de aproximadamente $0.05 por millón de tokens de entrada y $0.08 por millón de tokens de salida.
- Precios de ASR y TTS: Los modelos de Reconocimiento Automático de Voz (ASR) como Whisper se cotizan por hora de audio transcrito (por ejemplo, alrededor de $0.02-$0.11/hora). Los modelos de Texto a Voz (TTS) se cotizan por millón de caracteres.
- Descuento de la API por Lotes: El uso de la API por Lotes para grandes trabajos asíncronos ofrece un descuento del 50% sobre las tarifas estándar bajo demanda.
- Soluciones Empresariales: Precios y opciones de despliegue personalizados, incluidas soluciones en las propias instalaciones, están disponibles para clientes empresariales previa solicitud.
Groq Comentarios (0)
Inicie sesión para publicar comentarios
Iniciar sesión yaGroqAnálisis de tráfico del sitio web
Estado del tráfico más reciente
Estado
Tendencia de tráfico mensual
Ubicación geográfica
Top 5 países/regiones
-
🇮🇳 India46,80%
-
🇺🇸 United States25,05%
-
🇧🇷 Brazil14,86%
-
🇵🇰 Pakistan6,67%
-
🇮🇩 Indonesia6,62%
Fuente de tráfico
| Tipo de fuente | Porcentaje |
|---|---|
|
Tráfico directo
|
77,78% |
|
Tráfico de referencia
|
20,42% |
|
Correo
|
1,80% |
Palabras clave populares
| Palabra clave | Costo por clic |
|---|---|
|
$1,75
|
|
|
$1,72
|
|
|
$2,67
|
|
|
$1,49
|
|
|
$1,80
|
Groq Alternativas
Ver todo
OpenAI
OpenAI es una empresa líder en investigación e implementación de IA dedicada a garantizar que la inteligencia artificial …
OpenAI es una empresa líder en investigación e implementación de IA dedicada a garantizar que la inteligencia artificial general (AGI) beneficie a toda la humanidad. Desarrolla modelos de vanguardia como GPT-5, ChatGPT para IA conversacional, Sora para texto a video y DALL-E para generación de imágenes. A través de su robusta plataforma API, OpenAI permite a desarrolladores y empresas integrar potentes capacidades de IA en sus aplicaciones, impulsando la innovación en diversas industrias.

Inception Labs
Inception Labs presenta una nueva generación de Modelos de Lenguaje Grandes de Difusión (dLLMs) que son hasta 10 …
Inception Labs presenta una nueva generación de Modelos de Lenguaje Grandes de Difusión (dLLMs) que son hasta 10 veces más rápidos y económicos que los modelos tradicionales. Utilizando un enfoque paralelo basado en difusión, ofrece una velocidad, calidad y control sin precedentes para la generación de texto y código, ideal para aplicaciones de nivel empresarial.
TextSynth
TextSynth ofrece a los desarrolladores un acceso potente y rentable a un conjunto de modelos de IA, incluidos …
TextSynth ofrece a los desarrolladores un acceso potente y rentable a un conjunto de modelos de IA, incluidos grandes modelos de lenguaje (LLM), texto a imagen, texto a voz y voz a texto, a través de una API REST flexible y un playground interactivo. Cuenta con modelos como Llama, Mistral, Stable Diffusion y Whisper, optimizados para velocidad y asequibilidad.
fal.ai
Una plataforma de medios generativos para desarrolladores, que proporciona API ultrarrápidas para ejecutar y ajustar modelos avanzados de …
Una plataforma de medios generativos para desarrolladores, que proporciona API ultrarrápidas para ejecutar y ajustar modelos avanzados de IA para imágenes, vídeo y 3D. Acceda a modelos de última generación con velocidades de inferencia hasta 4 veces más rápidas.

Ollama
Ollama es un potente marco de código abierto para ejecutar grandes modelos de lenguaje (LLMs) como Llama 3, …
Ollama es un potente marco de código abierto para ejecutar grandes modelos de lenguaje (LLMs) como Llama 3, Mistral y Gemma localmente en tu propio hardware. Disponible para macOS, Windows y Linux, simplifica la configuración y gestión de modelos de código abierto, permitiendo un desarrollo y uso de IA privado, sin conexión y rentable.
Outspeed
Una API y SDK para que los desarrolladores construyan e implementen compañeros de voz de IA con emoción …
Una API y SDK para que los desarrolladores construyan e implementen compañeros de voz de IA con emoción y memoria en tiempo real. Integre fácilmente interacciones de voz naturales y de baja latencia en aplicaciones web y móviles.
SiliconFlow
SiliconFlow es una plataforma de infraestructura de IA unificada diseñada para la inferencia de alto rendimiento de Modelos …
SiliconFlow es una plataforma de infraestructura de IA unificada diseñada para la inferencia de alto rendimiento de Modelos de Lenguaje Grandes (LLMs) y modelos multimodales. Ofrece a desarrolladores y empresas opciones de despliegue escalables, rentables y flexibles, incluyendo APIs sin servidor, GPUs reservadas y capacidades de ajuste fino, todo accesible a través de una única API compatible con OpenAI.
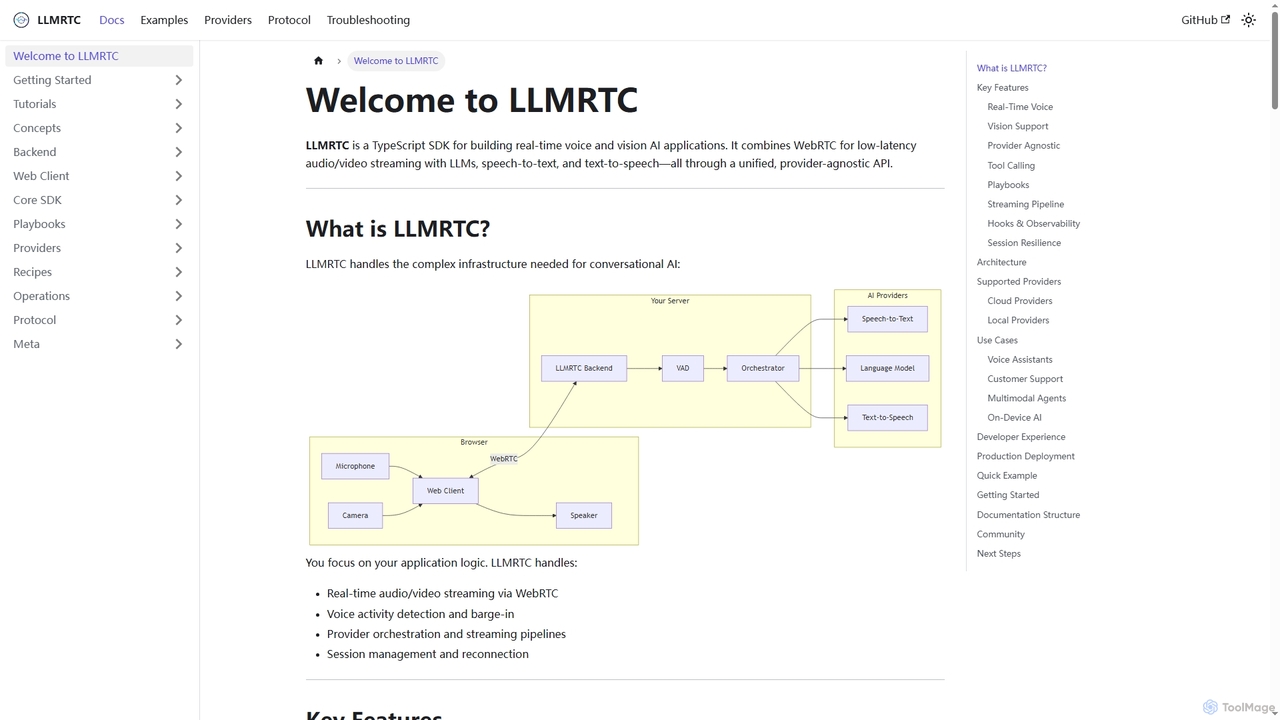
LLMRTC
LLMRTC es un SDK de TypeScript para construir aplicaciones de IA de voz y visión en tiempo real. …
LLMRTC es un SDK de TypeScript para construir aplicaciones de IA de voz y visión en tiempo real. Integra WebRTC para la transmisión de audio/video de baja latencia con LLM, voz a texto y texto a voz, todo a través de una API unificada e independiente del proveedor. Los desarrolladores pueden centrarse en la lógica de la aplicación mientras LLMRTC maneja la compleja infraestructura de IA conversacional.

InternAI (Shusheng)
InternAI (Shusheng) es un completo conjunto de modelos de fundación de código abierto y alto rendimiento desarrollado por …
InternAI (Shusheng) es un completo conjunto de modelos de fundación de código abierto y alto rendimiento desarrollado por el Laboratorio de IA de Shanghái. Abarca lenguaje, multimodalidad, predicción meteorológica, diseño aeroespacial, modelado 3D, finanzas e investigación científica, con el objetivo de potenciar la innovación global.
ComfyOnline
Una plataforma basada en la nube para ejecutar flujos de trabajo de ComfyUI en línea sin hardware costoso. …
Una plataforma basada en la nube para ejecutar flujos de trabajo de ComfyUI en línea sin hardware costoso. Ofrece un entorno sin servidor, implementación de API con un solo clic para aplicaciones de IA y acceso de pago por uso a GPU de alto rendimiento como H100 y A100. Simplifica todo el proceso, desde la creación del flujo de trabajo hasta la implementación escalable.
Groq Categoría
Groq Etiquetas
Groq Herramienta de IA
Groq Función de incrustar
Simplemente copie el código de inserción de abajo y pegue la insignia en su blog, artículo o sitio web oficial para dirigir el tráfico directamente a la página de detalles de esta herramienta, ¡aumentando rápidamente la exposición y el número de usuarios!

Aún no hay comentarios, ¡sé el primero en comentar!