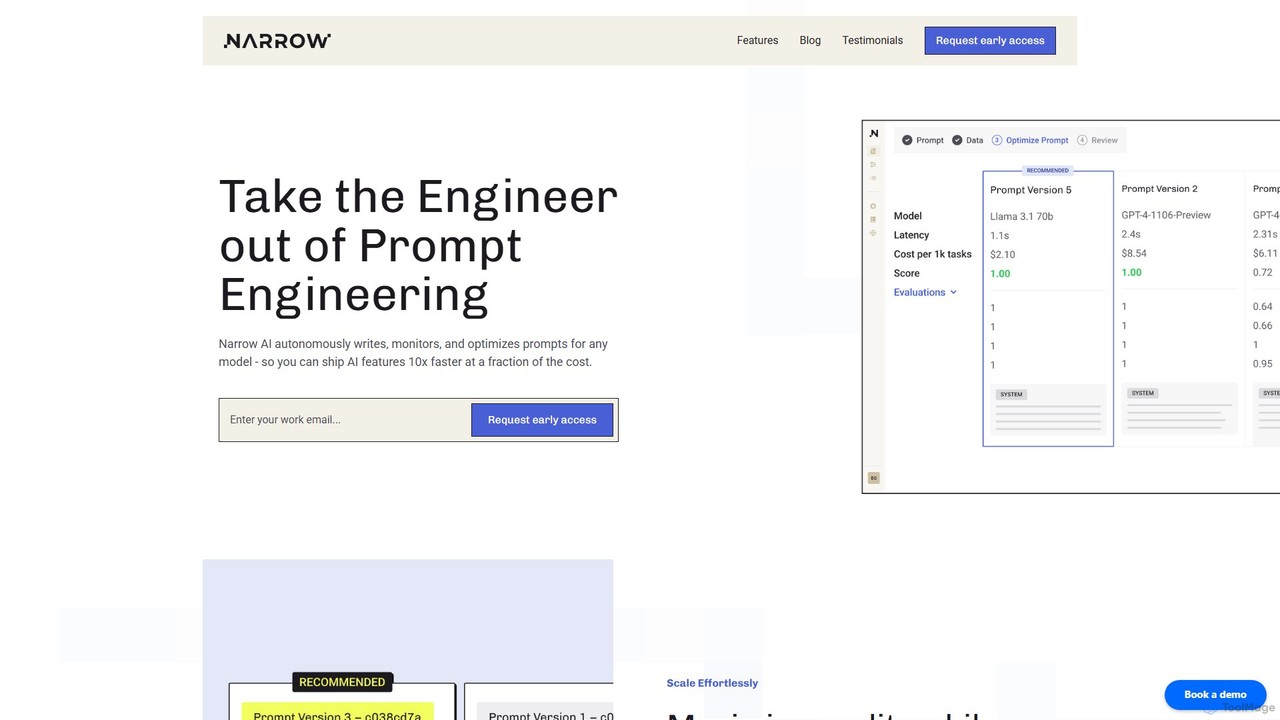
Narrow AI
Narrow AI est une plateforme d'optimisation de LLM pour les développeurs qui automatise l'ingénierie des prompts et la …
Narrow AI est une plateforme d'optimisation de LLM pour les développeurs qui automatise l'ingénierie des prompts et la sélection de modèles pour réduire considérablement les coûts opérationnels de l'IA jusqu'à 95%. Elle rationalise les flux de travail, améliore la précision et accélère le déploiement de fonctionnalités d'IA de haute qualité et à faible latence.
À propos de Optimisation de Modèle
Les outils d'optimisation de modèle sont une catégorie spécialisée de logiciels d'infrastructure IA conçus pour rendre les modèles d'apprentissage automatique entraînés plus petits, plus rapides et plus économes en énergie. Ces outils appliquent des techniques telles que la quantification, l'élagage et la distillation des connaissances pour réduire l'empreinte calculatoire et mémoire d'un modèle sans perte significative de précision. Ce processus est crucial pour déployer une IA complexe sur du matériel aux ressources limitées, comme les téléphones mobiles ou les appareils IoT, et pour réduire les coûts opérationnels des services d'IA à grande échelle dans le cloud. Ils comblent le fossé entre un modèle entraîné et son application pratique dans le monde réel.
Fonctionnalités Clés
- Quantification : Réduit la précision des poids du modèle (par ex., de flottant 32 bits à entier 8 bits) pour diminuer la taille et accélérer le calcul.
- Élagage (Pruning) : Supprime systématiquement les poids ou les connexions moins importants du réseau neuronal pour créer un modèle plus petit et plus épars.
- Distillation des connaissances : Entraîne un modèle "étudiant" plus petit et compact pour imiter le comportement d'un modèle "professeur" plus grand et plus complexe.
- Compilation de modèle : Convertit un modèle en un format exécutable hautement optimisé et spécifique au matériel pour les appareils cibles comme les GPU, TPU ou CPU.
- Profilage des performances : Analyse l'exécution d'un modèle pour identifier et résoudre les goulots d'étranglement liés à la vitesse, la mémoire ou la consommation d'énergie.
Cas d'Usage
L'optimisation de modèle est essentielle pour les ingénieurs MLOps, les développeurs IA et les ingénieurs en systèmes embarqués. Elle est largement utilisée dans des secteurs comme l'électronique grand public pour l'IA sur appareil, l'automobile pour les systèmes de perception en temps réel, et le cloud computing pour gérer les coûts d'inférence des grands modèles de langage (LLM) et des moteurs de recommandation. Toute application nécessitant une inférence IA efficace bénéficie de ces outils.
Comment Choisir
Lors de la sélection d'un outil d'optimisation de modèle, considérez sa compatibilité avec vos frameworks d'IA (par ex., TensorFlow, PyTorch, ONNX). Évaluez son support pour votre matériel cible, des GPU de serveur aux NPU mobiles. Analysez la gamme de techniques d'optimisation qu'il propose et le degré d'automatisation par rapport au contrôle manuel fourni. Enfin, analysez sa capacité à gérer le compromis entre les gains de performance et la dégradation potentielle de la précision.
Optimisation de ModèleCas d'utilisation
Déploiement de modèles d'IA sur des appareils en périphérie (Edge)
Un développeur d'applications mobiles doit intégrer une fonctionnalité de détection d'objets en temps réel dans son application. Le modèle original est trop volumineux et trop lent pour fonctionner de manière fluide sur un smartphone, ce qui entraîne une décharge rapide de la batterie et une mauvaise expérience utilisateur. En utilisant un outil d'optimisation de modèle, le développeur applique une quantification 8 bits et un élagage au modèle. Cela réduit sa taille de 75 % et triple la vitesse d'inférence, permettant à la fonctionnalité de s'exécuter efficacement sur l'appareil avec un impact minimal sur la durée de vie de la batterie, offrant ainsi une expérience utilisateur réactive et puissante.
Réduction des coûts d'inférence dans le cloud pour les LLM
Une startup technologique gère un service de chatbot populaire alimenté par un grand modèle de langage (LLM). Le coût élevé des serveurs GPU pour l'inférence a un impact sur leur rentabilité. L'équipe MLOps utilise une suite d'optimisation de modèle pour appliquer la distillation des connaissances et l'élagage structuré. Ils créent un modèle plus petit et spécialisé qui conserve 98 % des performances de l'original sur leurs tâches spécifiques. Ce modèle optimisé peut gérer 2,5 fois plus d'utilisateurs simultanés sur le même matériel, réduisant directement leur facture d'infrastructure cloud de plus de 50 % et améliorant l'évolutivité du service.
Activation de l'IA en temps réel dans les systèmes automobiles
Un ingénieur automobile développe un système avancé d'aide à la conduite (ADAS) qui utilise un réseau neuronal pour la détection des piétons. Le système a des exigences de latence strictes — une décision doit être prise en quelques millisecondes. L'ingénieur utilise un outil de compilation de modèle pour convertir son modèle PyTorch en un moteur hautement optimisé pour le GPU embarqué spécifique de la voiture. Le processus de compilation fusionne les couches et optimise l'accès à la mémoire, réduisant la latence d'inférence de 60 % et garantissant que le système atteint ses objectifs de performance en temps réel critiques pour la sécurité.
Intégration de modèles sur des microcontrôleurs à faible consommation
Un ingénieur en systèmes embarqués conçoit un appareil domestique intelligent avec une fonction de détection de mots-clés. Le matériel cible est un minuscule microcontrôleur avec seulement 256 Ko de RAM. Le modèle initial TensorFlow Lite est trop volumineux pour y être intégré. À l'aide d'une boîte à outils d'optimisation avancée, l'ingénieur applique un élagage de poids agressif et une quantification en entiers 8 bits. Cela réduit la taille du modèle de 1 Mo à seulement 180 Ko, permettant son déploiement réussi sur le microcontrôleur tout en maintenant une précision de plus de 95 % pour les mots-clés cibles, rendant ainsi la fonctionnalité intelligente viable.
Accélération des moteurs de recommandation e-commerce
Une équipe MLOps d'une grande entreprise de commerce électronique gère un modèle de recommandation par apprentissage profond. Pour fournir des suggestions en temps réel, la latence d'inférence doit être extrêmement faible. Ils utilisent un outil de profilage des performances pour identifier que des couches spécifiques de leur modèle sont des goulots d'étranglement computationnels sur leurs GPU de serveur. L'outil d'optimisation suggère des optimisations ciblées, y compris la compilation de ces couches spécifiques avec une précision différente (précision mixte). Après avoir appliqué ces changements, la latence de bout en bout du service de recommandation chute de 40 %, ce qui accélère le chargement des pages et entraîne une augmentation mesurable de l'engagement des utilisateurs et des ventes.
Optimisation des modèles NLP pour des réponses d'API plus rapides
Une entreprise SaaS propose une API de résumé de texte. Les clients se plaignent de la lenteur des temps de réponse pour les documents volumineux. L'équipe backend identifie le modèle NLP comme étant le goulot d'étranglement. Au lieu de ré-entraîner un nouveau modèle à partir de zéro, ils utilisent la distillation des connaissances. Ils entraînent un modèle Transformer plus petit et plus rapide (l'« étudiant ») pour reproduire la sortie de leur grand modèle précis (le « professeur »). Le nouveau modèle étudiant est 4 fois plus rapide et est déployé en production, réduisant le temps de réponse moyen de l'API de 3 secondes à moins de 700 millisecondes, améliorant ainsi considérablement la satisfaction des clients.