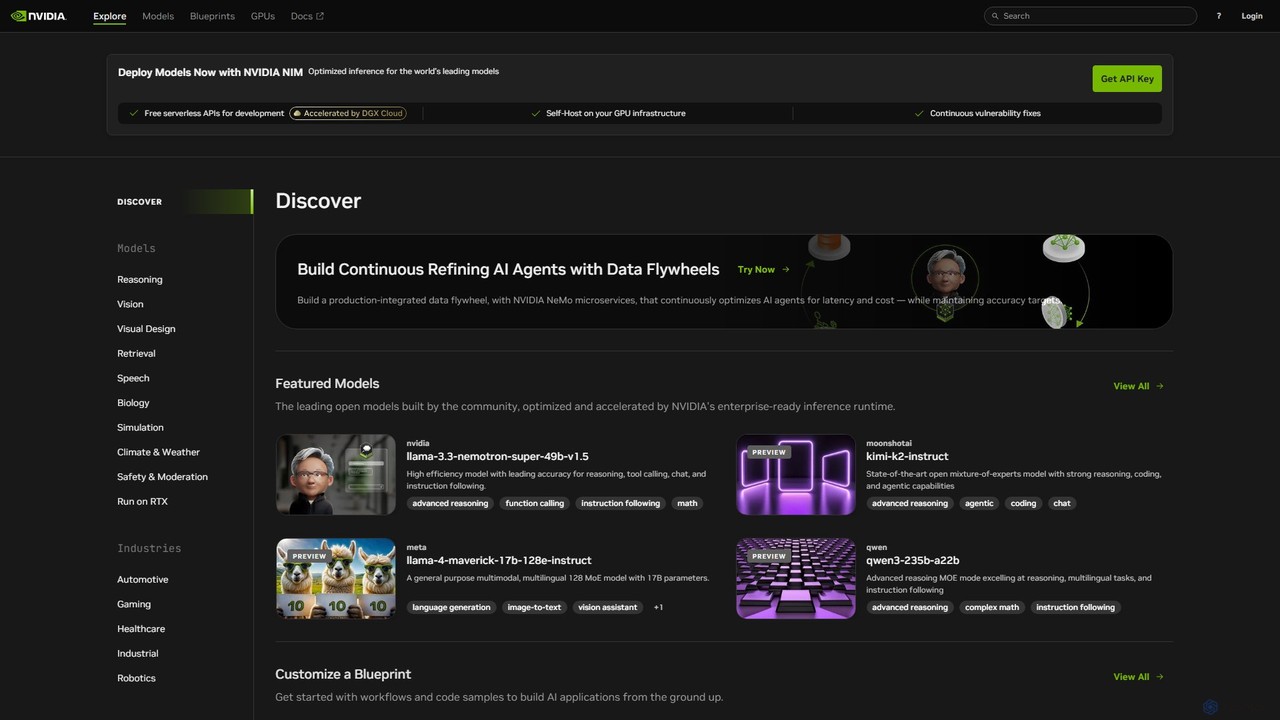
NVIDIA Build
NVIDIA Build est une plateforme complète pour les développeurs et les entreprises afin de découvrir, personnaliser et déployer …
NVIDIA Build est une plateforme complète pour les développeurs et les entreprises afin de découvrir, personnaliser et déployer des modèles d'IA générative prêts pour la production. Elle propose un vaste catalogue de modèles optimisés, des microservices NVIDIA NIM pour une inférence haute performance et des plans d'application pour accélérer le développement.
À propos de Bibliothèque de modèles
Une Bibliothèque de modèles d'IA est une plateforme centralisée qui donne accès à une collection diversifiée de modèles d'intelligence artificielle pré-entraînés. Ces plateformes agissent comme des dépôts, permettant aux utilisateurs de découvrir, d'évaluer et d'intégrer des modèles pour diverses tâches telles que le traitement du langage naturel, la vision par ordinateur et l'analyse audio. La valeur principale d'une Bibliothèque de modèles est d'accélérer le développement et de réduire les coûts en éliminant le besoin de former des modèles complexes à partir de zéro. Elles fournissent une base sur laquelle les développeurs et les chercheurs peuvent s'appuyer, permettant un prototypage et un déploiement rapides de fonctionnalités basées sur l'IA.
Fonctionnalités Clés
- Catalogue de modèles étendu : Offre une grande variété de modèles pré-entraînés pour différentes tâches, domaines et frameworks (par ex., TensorFlow, PyTorch).
- Recherche et filtrage : Outils avancés pour trouver des modèles en fonction de la tâche, de la popularité, de la licence ou des spécifications techniques.
- API d'inférence dans le navigateur : Fournit des widgets interactifs ou des points de terminaison pour tester les performances d'un modèle avec des entrées personnalisées directement sur la plateforme.
- Contrôle de version et documentation : Inclut des fiches de modèle détaillées, des exemples d'utilisation et un historique des versions pour garantir la transparence et la reproductibilité.
- Support d'intégration : Propose des extraits de code, des SDK et des API pour simplifier le processus de déploiement des modèles dans les applications.
Cas d'utilisation
Les Bibliothèques de modèles sont principalement utilisées par les développeurs de logiciels, les data scientists et les chercheurs en IA. Elles sont essentielles pour les équipes qui ont besoin de prototyper rapidement de nouvelles fonctionnalités, comme l'ajout d'un résumé de texte à une application ou la reconnaissance d'images à un service. Les startups et les entreprises exploitent également ces bibliothèques pour intégrer des capacités d'IA avancées sans l'investissement important requis pour le développement de modèles en interne.
Comment choisir
Lors de la sélection d'une Bibliothèque de modèles, tenez compte de l'étendue et de la qualité de sa collection de modèles pour vos besoins spécifiques. Évaluez la clarté de sa documentation, la facilité d'utilisation de ses outils de test et d'intégration, et les frameworks pris en charge. Examinez également les termes de licence de chaque modèle pour garantir la conformité pour un usage commercial, et considérez le soutien de la communauté et le niveau d'activité de la plateforme pour le dépannage et la collaboration.
Bibliothèque de modèlesCas d'utilisation
Prototypage rapide d'une fonctionnalité d'application
Un développeur d'applications mobiles doit ajouter une fonctionnalité de résumé de texte à son application d'actualités. Au lieu de passer des mois à développer et à entraîner un modèle propriétaire, il se tourne vers une Bibliothèque de modèles d'IA. En utilisant les filtres de recherche, il trouve rapidement plusieurs modèles de résumé très performants. Il utilise l'outil d'inférence intégré au navigateur pour tester chaque modèle avec des exemples d'articles de presse, en comparant la qualité et la vitesse des résultats. En quelques heures, il sélectionne le meilleur modèle et utilise l'API et les extraits de code fournis pour l'intégrer dans le backend de son application, lançant la nouvelle fonctionnalité en quelques jours au lieu de plusieurs mois.
Sélection d'un modèle pour la recherche universitaire
Un chercheur universitaire étudie les biais dans les modèles de langage. Il a besoin d'un modèle de référence pour le comparer à ses propres modèles expérimentaux. Il accède à une Bibliothèque de modèles pour parcourir divers modèles de langage fondamentaux comme BERT ou des variantes de GPT. Les fiches de modèle fournissent des informations cruciales sur les données d'entraînement, l'architecture et les limitations connues. Il télécharge quelques modèles et leurs ensembles de données associés pour effectuer des tests de référence, économisant ainsi un temps et des ressources de calcul considérables qui auraient été consacrés au pré-entraînement d'un modèle de référence à partir de zéro.
Affinage d'un modèle pour un domaine de niche
Une startup de technologie juridique souhaite créer un chatbot qui comprend la terminologie juridique. Entraîner un grand modèle de langage à partir de zéro est d'un coût prohibitif. À la place, leur équipe de data science sélectionne un modèle de langage puissant et généraliste dans une Bibliothèque de modèles. Ils téléchargent le modèle pré-entraîné, puis l'affinent sur leur propre ensemble de données de documents juridiques et de paires de questions-réponses. Ce processus adapte le modèle général aux nuances spécifiques du langage juridique, aboutissant à un chatbot très précis et spécifique au domaine, pour une fraction du coût et du temps de développement à partir de zéro.
Intégration de la transcription vocale dans un produit
Une entreprise qui développe des logiciels de réunion souhaite ajouter une fonctionnalité de transcription automatique. Son équipe d'ingénieurs explore une Bibliothèque de modèles pour trouver un modèle de reconnaissance vocale approprié. Ils filtrent les modèles par langue prise en charge, benchmarks de précision et latence. Après avoir testé quelques options prometteuses via leurs points de terminaison d'API, ils choisissent un modèle qui offre le meilleur équilibre entre vitesse et précision pour leur cas d'utilisation. En utilisant le SDK de la bibliothèque, ils intègrent le service de transcription dans leur logiciel, offrant ainsi une fonctionnalité de grande valeur aux clients sans avoir besoin d'expertise interne en reconnaissance vocale.
Comparaison de modèles de génération d'images pour des projets créatifs
Un graphiste explore l'IA pour créer des supports marketing uniques. Il utilise une Bibliothèque de modèles qui héberge divers modèles de conversion de texte en image comme Stable Diffusion, Midjourney et des variantes de DALL-E. La plateforme lui permet de saisir la même invite de texte dans plusieurs modèles simultanément et de comparer les résultats côte à côte. Cela l'aide à comprendre le style artistique unique et les points forts de chaque modèle. Il peut rapidement identifier quel modèle correspond le mieux à l'esthétique de sa marque, économisant des heures de tests sur des plateformes distinctes et rationalisant son flux de travail créatif.
Automatisation de la catégorisation des tickets de support client
Un responsable du service client souhaite catégoriser automatiquement les tickets de support entrants pour les acheminer vers la bonne équipe. Son entreprise ne dispose pas d'une équipe de data science dédiée. Le responsable utilise une Bibliothèque de modèles pour trouver un modèle de classification de texte pré-entraîné. Il le teste en utilisant l'interface de la plateforme en y collant des exemples de leurs tickets de support. Voyant des résultats positifs, il travaille avec un développeur pour utiliser l'API du modèle. Désormais, chaque nouveau ticket est automatiquement envoyé à l'API, qui renvoie une catégorie (par ex., « Facturation », « Problème technique »), améliorant ainsi les temps de réponse et l'efficacité de l'équipe sans un investissement technique majeur.