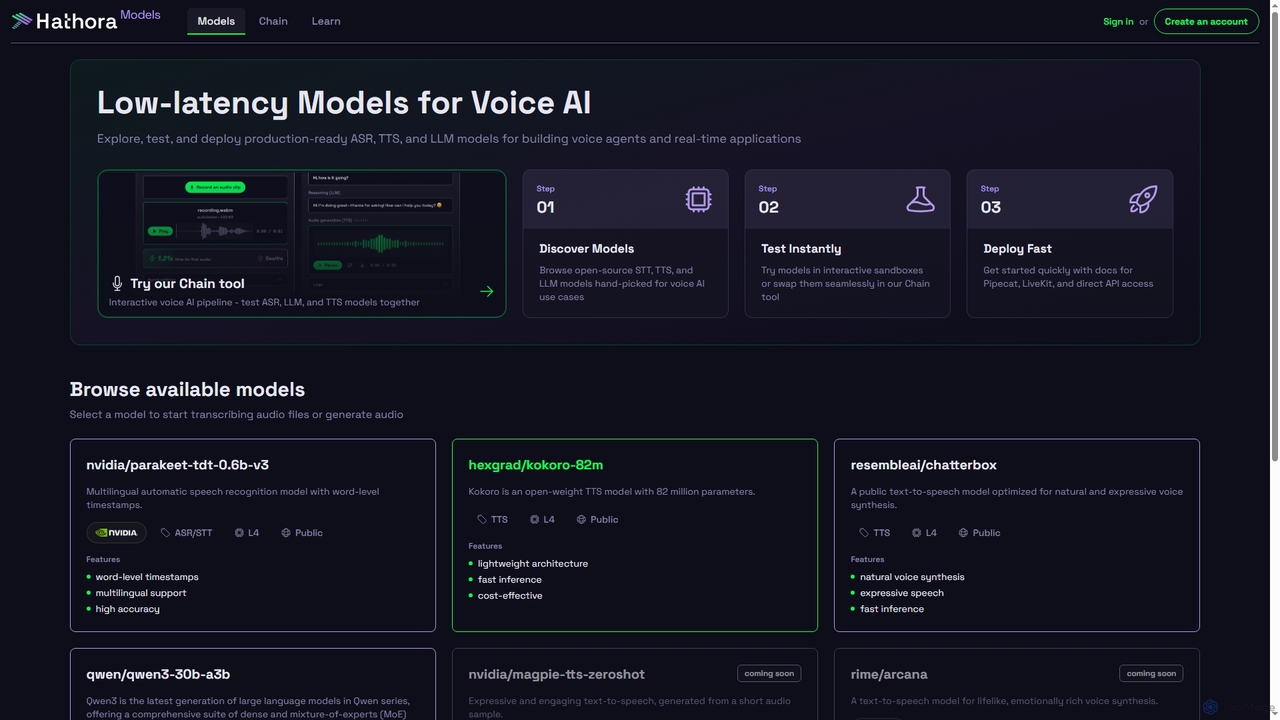
Models
Models de Hathora propose un catalogue sélectionné de modèles ASR, TTS et LLM à faible latence, optimisés pour …
Models de Hathora propose un catalogue sélectionné de modèles ASR, TTS et LLM à faible latence, optimisés pour l'IA vocale et les applications en temps réel. Les développeurs peuvent explorer, tester et déployer rapidement des modèles prêts pour la production, avec des bacs à sable interactifs et un accès direct à l'API pour une intégration transparente dans les agents vocaux et d'autres applications.
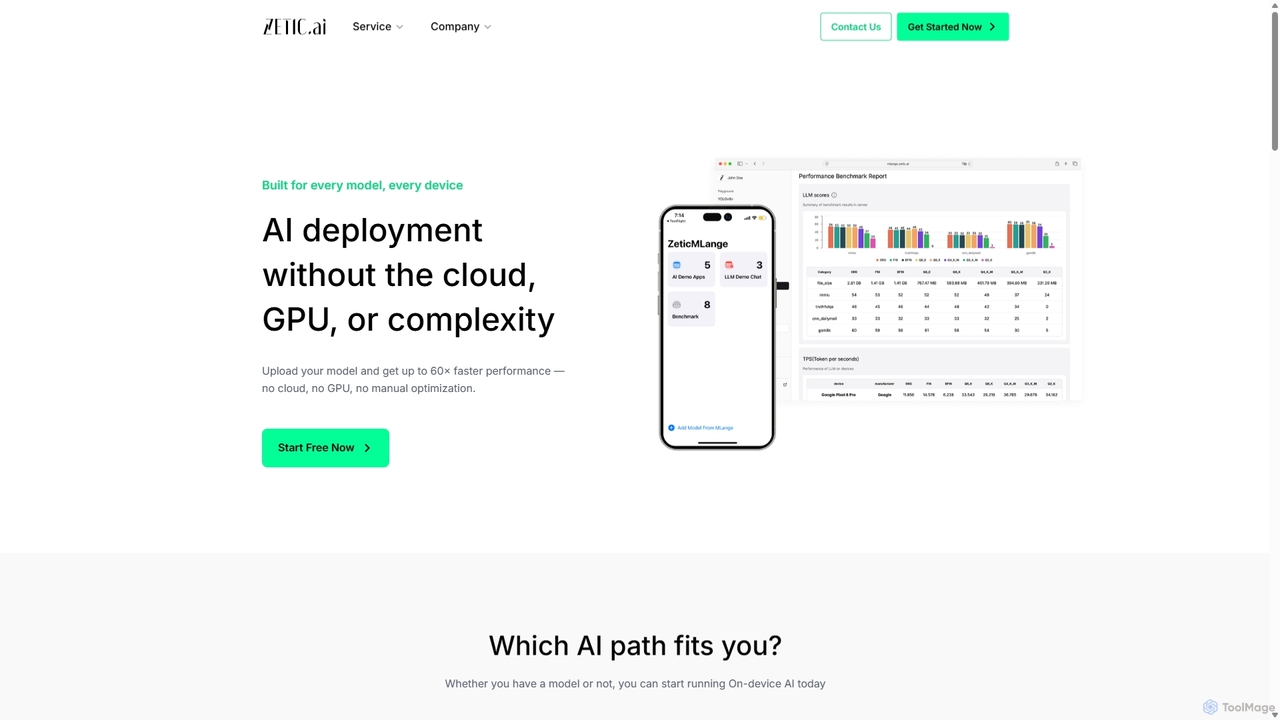
Zetic.ai
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge …
Zetic.ai est une plateforme permettant aux développeurs de déployer des modèles d'IA directement sur des appareils périphériques (edge devices), éliminant le besoin de serveurs GPU coûteux. Son pipeline automatisé, ZETIC.MLange, optimise et convertit les modèles pour une exécution sur l'appareil, atteignant des performances jusqu'à 60 fois plus rapides grâce à l'accélération NPU, tout en garantissant la confidentialité des données et en réduisant la latence.
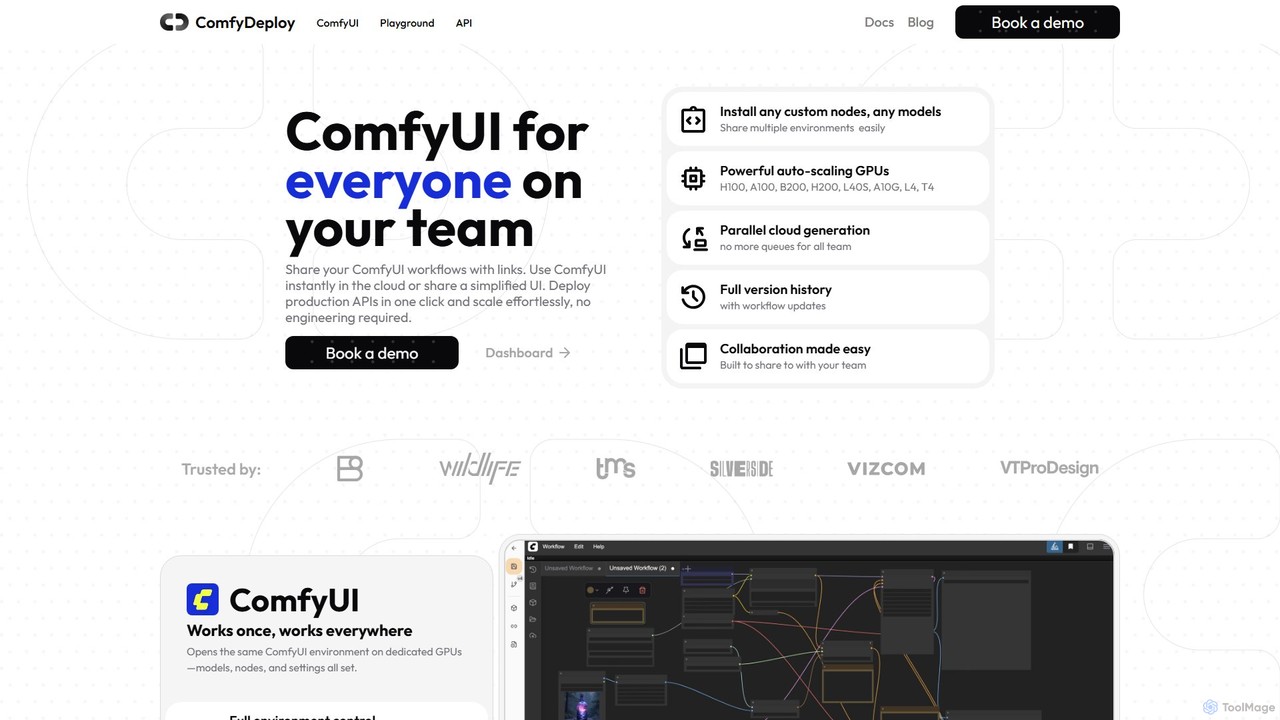
ComfyDeploy
ComfyDeploy est une plateforme cloud conçue pour que les équipes puissent créer, partager et mettre à l'échelle des …
ComfyDeploy est une plateforme cloud conçue pour que les équipes puissent créer, partager et mettre à l'échelle des flux de travail ComfyUI. Elle permet le déploiement en un clic d'API prêtes pour la production, fournit une infrastructure GPU à mise à l'échelle automatique et offre des interfaces simplifiées pour les utilisateurs non techniques. Collaborez en toute transparence, gérez les nœuds et modèles personnalisés, et transformez des processus créatifs complexes en applications évolutives sans surcharge d'ingénierie.
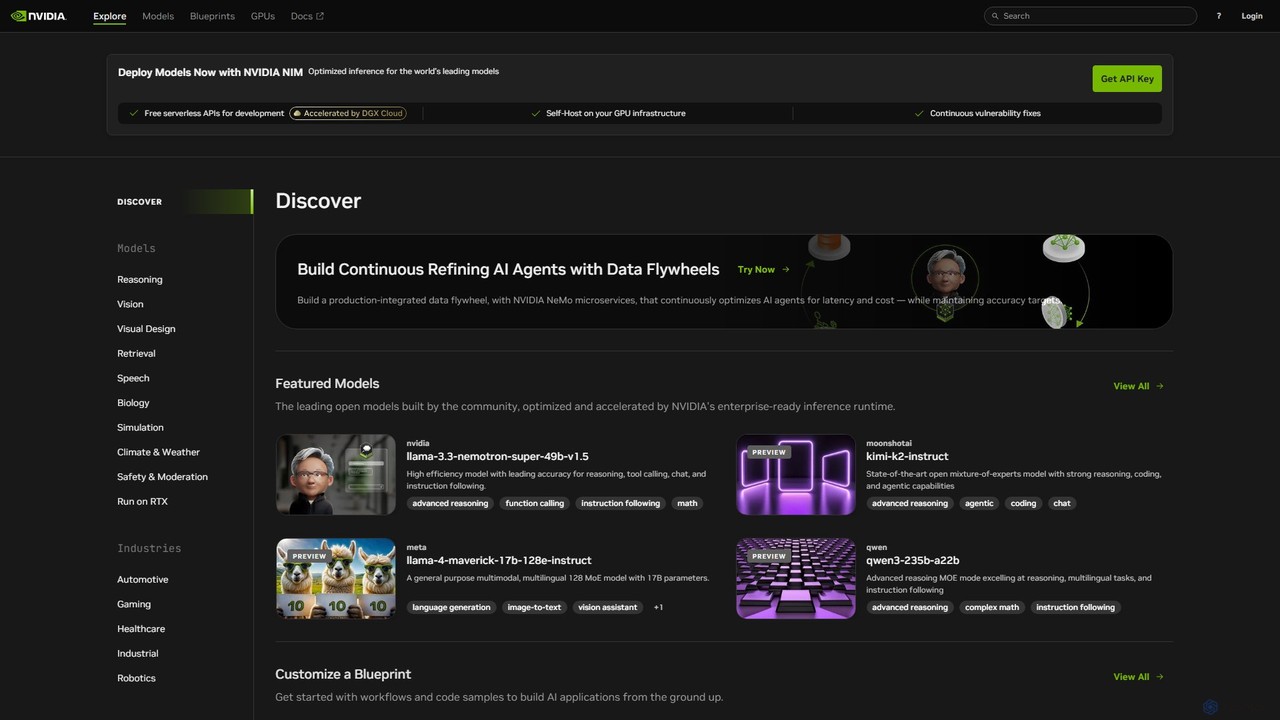
NVIDIA Build
NVIDIA Build est une plateforme complète pour les développeurs et les entreprises afin de découvrir, personnaliser et déployer …
NVIDIA Build est une plateforme complète pour les développeurs et les entreprises afin de découvrir, personnaliser et déployer des modèles d'IA générative prêts pour la production. Elle propose un vaste catalogue de modèles optimisés, des microservices NVIDIA NIM pour une inférence haute performance et des plans d'application pour accélérer le développement.
Fireworks AI
Une plateforme haute performance pour les développeurs afin de créer, personnaliser et mettre à l'échelle des applications d'IA …
Une plateforme haute performance pour les développeurs afin de créer, personnaliser et mettre à l'échelle des applications d'IA générative. Elle offre un moteur d'inférence rapide de pointe, des capacités de réglage fin avancées et un accès à une large gamme de modèles open-source, permettant des solutions d'IA en temps réel et rentables.
llmware
llmware est une plateforme d'IA destinée aux entreprises pour créer et déployer des flux de travail d'IA privés. …
llmware est une plateforme d'IA destinée aux entreprises pour créer et déployer des flux de travail d'IA privés. Son produit phare, Model HQ, permet aux utilisateurs d'exécuter plus de 100 petits modèles de langage (jusqu'à 32B de paramètres) de manière sécurisée et locale sur des PC IA, sans connexion Internet. Il propose le RAG sur l'appareil, des requêtes SQL et d'autres tâches automatisées, en mettant l'accent sur la confidentialité des données, l'optimisation matérielle et un coût d'inférence par jeton nul.

hypermink
HyperMink fournit Inferenceable, un serveur d'inférence IA gratuit, open-source et auto-hébergeable. Basé sur Node.js et llama.cpp, il permet …
HyperMink fournit Inferenceable, un serveur d'inférence IA gratuit, open-source et auto-hébergeable. Basé sur Node.js et llama.cpp, il permet aux développeurs et aux entreprises d'exécuter des grands modèles de langage localement, garantissant une confidentialité, un contrôle et une rentabilité complets des données. Votre IA, Vos Règles.
À propos de Déploiement de modèle
Les outils de Déploiement de modèle sont des plateformes spécialisées conçues pour prendre un modèle de machine learning entraîné et le rendre opérationnel dans un environnement de production. Ces outils automatisent le processus complexe d'empaquetage du modèle, de création de points de terminaison d'API évolutifs et de gestion de son cycle de vie après le développement. Ils fournissent l'infrastructure critique pour servir des prédictions aux utilisateurs ou à d'autres applications de manière fiable et efficace. En gérant des tâches telles que la configuration des serveurs, la gestion des dépendances et la surveillance des performances, ils comblent le fossé entre la recherche en science des données et la valeur commerciale réelle.
Fonctionnalités Clés
- Génération Automatisée d'API : Créez instantanément des points de terminaison d'API REST sécurisés et évolutifs pour n'importe quel modèle entraîné, le rendant accessible aux applications.
- Gestion d'Infrastructure Évolutive : Gérez et mettez à l'échelle automatiquement les ressources de calcul (CPU/GPU) pour gérer les charges fluctuantes de demandes de prédiction sans intervention manuelle.
- Surveillance des Performances et Journalisation : Suivez les métriques clés comme la latence, le débit, les taux d'erreur et l'utilisation des ressources pour garantir la santé et la fiabilité du modèle.
- Versionnage de Modèles et Rétrogradations : Gérez plusieurs versions d'un modèle, effectuez des tests A/B et revenez rapidement à une version précédente en cas de problème.
- Empaquetage de l'Environnement et des Dépendances : Empaquetez les modèles et leurs dépendances logicielles spécifiques dans des conteneurs reproductibles (par ex. Docker) pour des performances constantes dans tous les environnements.
Cas d'Utilisation
Ces outils sont essentiels pour les ingénieurs ML, les data scientists et les équipes DevOps qui cherchent à mettre l'IA en production. Ils sont largement utilisés dans des secteurs comme la finance pour la détection de fraude en temps réel, le e-commerce pour alimenter les moteurs de recommandation, la santé pour déployer des modèles de diagnostic et le SaaS pour intégrer des fonctionnalités d'IA dans les produits.
Comment Choisir
Lors de la sélection d'un outil de Déploiement de modèle, tenez compte de sa prise en charge de vos frameworks ML spécifiques (comme TensorFlow, PyTorch), de ses cibles de déploiement (cloud, sur site ou en périphérie) et de ses capacités de mise à l'échelle automatique. Évaluez également la qualité de ses tableaux de bord de surveillance, son intégration avec les pipelines CI/CD existants (comme Jenkins ou GitHub Actions) et ses fonctionnalités de sécurité pour protéger les modèles et les données.
Déploiement de modèleCas d'utilisation
Servir un Modèle de Détection de Fraude en Temps Réel
Une entreprise de technologie financière doit déployer un modèle de machine learning qui évalue le risque de fraude des transactions en quelques millisecondes. En utilisant une plateforme de déploiement de modèles, leurs ingénieurs ML empaquettent le modèle entraîné et créent un point de terminaison d'API à faible latence. Ce point de terminaison est intégré à leur système de traitement des paiements. La plateforme met automatiquement à l'échelle l'infrastructure pour gérer les pics de volume de transactions, garantissant une haute disponibilité et des temps de réponse constants, ce qui est essentiel pour prévenir les transactions frauduleuses sans impacter l'expérience utilisateur.
Alimenter un Moteur de Recommandation E-commerce
Un détaillant en ligne souhaite fournir des recommandations de produits personnalisées aux acheteurs. Son équipe de science des données construit un modèle de filtrage collaboratif. Ils utilisent un outil de déploiement de modèle pour héberger ce modèle et l'exposer en tant qu'API interne. Le site de commerce électronique appelle cette API pour chaque utilisateur afin d'obtenir une liste de produits recommandés. La fonction de gestion des versions de l'outil leur permet de déployer en toute sécurité de nouvelles versions du modèle de recommandation, de tester leurs performances en A/B et de revenir rapidement en arrière si un nouveau modèle diminue l'engagement des utilisateurs ou les ventes.
Déployer un Modèle de Vision par Ordinateur sur des Appareils en Périphérie (Edge)
Une entreprise manufacturière utilise la vision par ordinateur pour le contrôle qualité sur sa chaîne de montage. Elle doit déployer un modèle de détection d'objets sur de petits appareils à faible consommation d'énergie directement sur le site de l'usine pour une analyse en temps réel. Un outil de déploiement de modèle prenant en charge les déploiements en périphérie (edge) est utilisé pour optimiser le modèle pour le matériel cible et l'empaqueter avec toutes les dépendances nécessaires. Cela permet une détection de défauts à faible latence directement à la source, réduisant la dépendance à la connectivité réseau vers un serveur cloud central et permettant une action immédiate sur la ligne de production.
Intégrer un Modèle NLP dans un Chatbot de Support Client
Une entreprise SaaS souhaite améliorer son support client avec un chatbot alimenté par l'IA. Après avoir entraîné un modèle de traitement du langage naturel (NLP) pour comprendre les requêtes des utilisateurs, elle utilise une plateforme de déploiement pour l'héberger. La plateforme fournit une API à haute disponibilité avec laquelle l'application front-end du chatbot communique. Les fonctionnalités de surveillance de l'outil sont cruciales pour suivre les performances du modèle, identifier les requêtes qu'il ne parvient pas à comprendre et collecter des données pour les futurs cycles de réentraînement, créant ainsi une boucle d'amélioration continue pour la précision du chatbot.
Test A/B de Différents Modèles de Prédiction de Désabonnement
Une équipe d'analyse marketing développe deux modèles différents pour prédire le désabonnement des clients. Ils ne savent pas lequel sera le plus performant dans un scénario réel. En utilisant une plateforme de déploiement de modèles qui prend en charge la répartition du trafic, ils déploient les deux modèles simultanément. La plateforme achemine 50 % des demandes de prédiction vers le modèle A et 50 % vers le modèle B. Après une semaine de collecte de données de performance en direct, l'équipe peut déterminer avec confiance quel modèle est le plus précis et déployer la version gagnante sur 100 % du trafic, optimisant ainsi leurs campagnes de rétention.
Offrir un Modèle d'IA Propriétaire en tant que Service API Payant
Une startup en IA a développé un modèle génératif unique pour créer de la musique. Pour monétiser leur technologie, ils décident de l'offrir en tant que service via une API payante. Ils utilisent une plateforme de déploiement de modèles pour héberger leur modèle, générer un point de terminaison d'API public et gérer l'authentification et la limitation de débit pour différents niveaux d'abonnement. L'infrastructure robuste de la plateforme garantit que leur service est fiable et peut évoluer à mesure que leur clientèle s'agrandit, leur permettant de se concentrer sur l'amélioration de leur technologie de modèle de base au lieu de gérer une infrastructure de serveurs complexe.