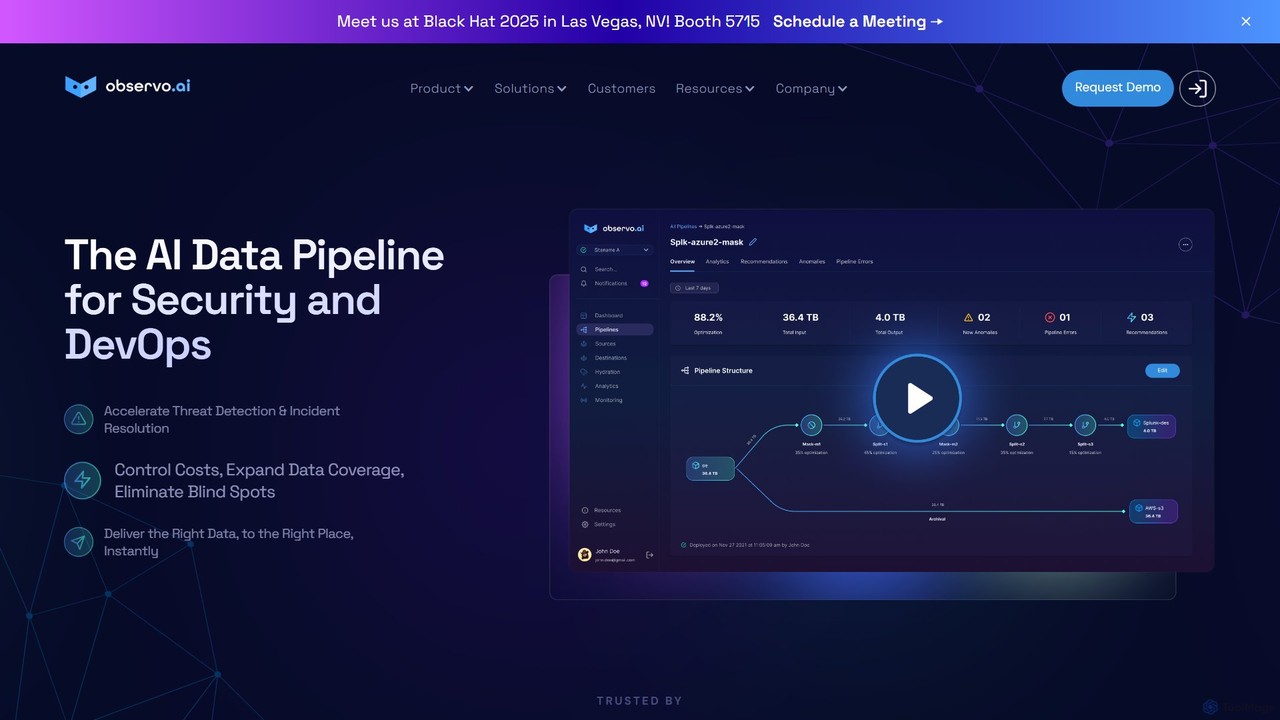
Observo AI
Observo AI est une plateforme de pipeline de données intelligente pour les équipes de sécurité et DevOps. Elle …
Observo AI est une plateforme de pipeline de données intelligente pour les équipes de sécurité et DevOps. Elle utilise l'IA pour optimiser les données de télémétrie, réduisant les volumes de logs jusqu'à 80% et les coûts d'observabilité de plus de 50%. La plateforme accélère la détection des menaces, enrichit les données en temps réel et élimine les angles morts, rendant la sécurité et les opérations plus efficaces et rentables.
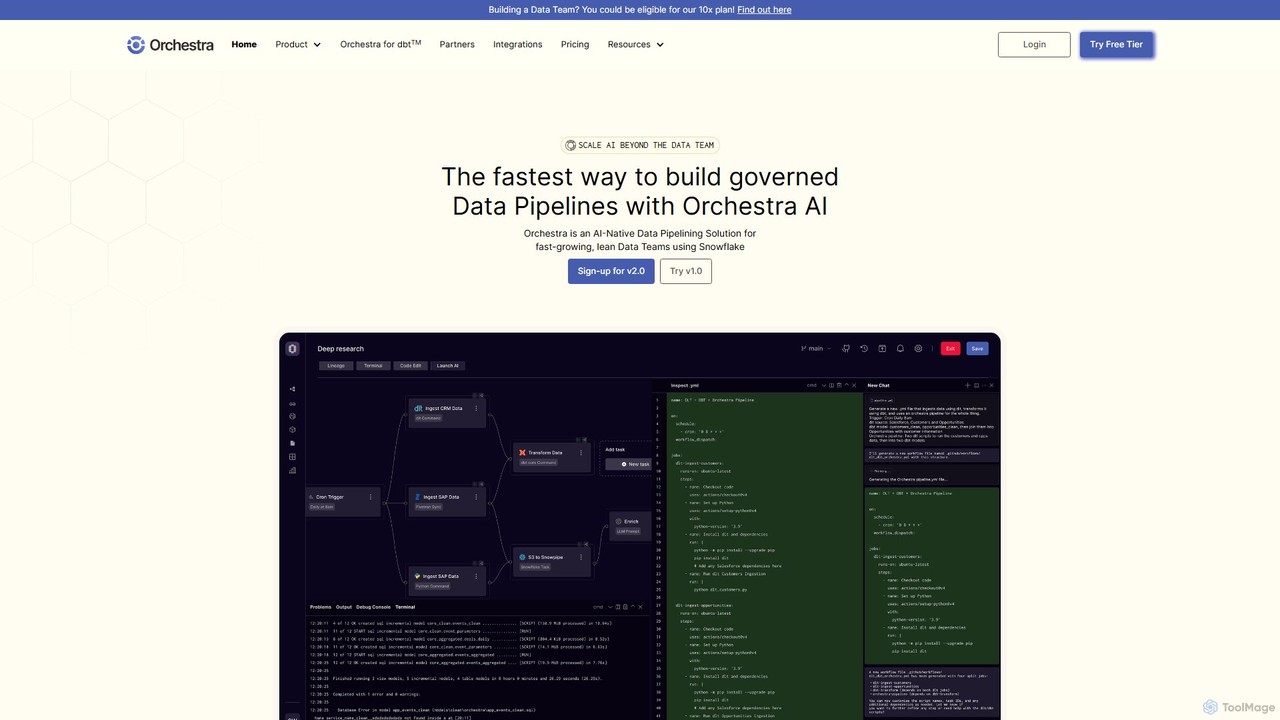
Orchestra
Orchestra est un plan de contrôle unifié pour l'orchestration et la gestion de pipelines de données, conçu pour …
Orchestra est un plan de contrôle unifié pour l'orchestration et la gestion de pipelines de données, conçu pour les équipes de données agiles. Il offre une solution native de l'IA pour construire, surveiller et gérer des pipelines de données gouvernés avec une observabilité de bout en bout, des alertes proactives et des intégrations étendues. Il simplifie les flux de travail de données complexes, réduit le temps de maintenance et garantit que les données sont fiables et prêtes pour l'IA.
À propos de Pipeline de données
Les outils de Pipeline de données sont des plateformes conçues pour automatiser le mouvement et la transformation des données de diverses sources vers une destination pour analyse. Ils orchestrent des flux de travail complexes impliquant l'ingestion, le traitement et le chargement des données, souvent en temps réel ou selon un calendrier. Ces outils sont essentiels pour maintenir des données cohérentes, fiables et à jour pour l'informatique décisionnelle, les modèles d'apprentissage automatique et les rapports opérationnels. Ils offrent une surveillance robuste, une gestion des erreurs et une évolutivité pour gérer efficacement les flux de données au sein de l'écosystème de données plus large.
Fonctionnalités Clés
- Connecteurs de Sources de Données : Se connectent nativement à un large éventail de bases de données, d'API, de stockage cloud et d'applications SaaS pour l'extraction de données.
- Orchestration de Flux de Travail : Conçoivent, planifient et gèrent visuellement des tâches de traitement de données en plusieurs étapes et leurs dépendances.
- Transformation en Transit : Nettoient, enrichissent, agrègent et reformatent les données au fur et à mesure de leur passage dans le pipeline à l'aide de logique SQL ou de code (ETL/ELT).
- Surveillance et Alertes : Suivent l'état du pipeline, la qualité des données et les performances en temps réel avec des alertes automatisées en cas de défaillances ou d'anomalies.
Cas d'Utilisation
Les outils de Pipeline de données sont largement utilisés par les ingénieurs de données, les analystes et les scientifiques dans les secteurs de la technologie, de la finance et du commerce électronique. Ils sont fondamentaux pour créer des systèmes de reporting automatisés, alimenter les modèles d'apprentissage automatique pour l'entraînement ou synchroniser les données entre les systèmes opérationnels comme les CRM et les ERP.
Comment Choisir
Lors de la sélection d'un outil de Pipeline de données, tenez compte de la variété et du volume de vos sources de données. Évaluez ses capacités de transformation (basées sur le code ou low-code), son évolutivité pour la croissance future et son intégration avec votre pile de données existante (par exemple, entrepôts de données, outils de BI). Évaluez également les fonctionnalités de surveillance et le modèle de tarification (par exemple, basé sur le volume ou sur le calcul).
Pipeline de donnéesCas d'utilisation
Automatisation des Rapports de Business Intelligence
Une équipe d'analyse de données utilise un outil de pipeline de données pour consolider les informations de plusieurs sources. Chaque nuit, le pipeline extrait automatiquement les données de vente de Salesforce, les métriques de campagne marketing de Google Ads et les tickets de support client de Zendesk. Il nettoie, standardise et joint ensuite ces ensembles de données avant de charger les données unifiées dans un entrepôt de données BigQuery. Cela garantit que les tableaux de bord Tableau de l'entreprise sont mis à jour avec des données fraîches et complètes au début de chaque journée de travail, éliminant des heures de collecte et de traitement manuels des données.
Alimenter l'Entraînement des Modèles de Machine Learning
Une équipe de science des données doit ré-entraîner régulièrement un modèle de prédiction de l'attrition client. Ils mettent en place un pipeline de données pour extraire les données brutes d'activité des utilisateurs de la base de données de leur application et les journaux d'utilisation du produit d'un bucket de stockage cloud. Le pipeline effectue de l'ingénierie de caractéristiques en transformant les données brutes en caractéristiques significatives, telles que 'derniere_date_connexion' et 'nombre_transactions_mensuelles'. L'ensemble de données traité et riche en caractéristiques est ensuite versionné et stocké dans un emplacement accessible par leur plateforme d'entraînement ML, garantissant que le modèle est toujours entraîné sur les données les plus récentes et de haute qualité.
Synchronisation des Données en Temps Réel entre Systèmes
Une entreprise de commerce électronique doit maintenir la cohérence de ses données d'inventaire sur son site web, son application mobile et son système de gestion d'entrepôt (WMS). Ils mettent en œuvre un pipeline de données en temps réel à l'aide d'une plateforme de streaming. Lorsqu'un client passe une commande sur le site web, un événement est capturé et envoyé via le pipeline. Le pipeline met instantanément à jour le décompte des stocks dans le WMS et reflète le nouveau niveau de stock sur le site web et l'application mobile. Cela évite la survente et garantit une expérience client cohérente sur tous les canaux.
Migration de Données vers un Entrepôt de Données Cloud
Une entreprise migre d'une base de données SQL Server sur site vers un entrepôt de données basé sur le cloud comme Snowflake. Un ingénieur de données utilise un outil de pipeline de données pour gérer cette migration complexe. Le pipeline est configuré pour effectuer d'abord un chargement en masse historique de toutes les données existantes. Ensuite, il passe en mode de capture de données modifiées (CDC) incrémentielle, qui réplique en continu tout enregistrement nouveau ou mis à jour de SQL Server vers Snowflake. Cela garantit une transition en douceur avec un temps d'arrêt minimal et assure la cohérence des données entre les anciens et les nouveaux systèmes pendant la période de migration.
Agrégation de Journaux pour l'Analyse de Sécurité
Une équipe de cybersécurité a besoin d'une vue centralisée de tous les journaux système et applicatifs pour la détection des menaces. Ils déploient un pipeline de données qui collecte les journaux en temps réel des serveurs web, des bases de données et des pare-feu. Le pipeline analyse les données de journal non structurées, standardise les horodatages et les enrichit avec des informations de géolocalisation basées sur les adresses IP. Les journaux traités sont ensuite diffusés dans un système de gestion des informations et des événements de sécurité (SIEM). Cela permet aux analystes de sécurité d'exécuter des requêtes complexes, d'identifier des modèles suspects et de répondre aux incidents de sécurité beaucoup plus rapidement.
Enrichissement des Données CRM avec des Informations Tierces
Une équipe des opérations marketing souhaite améliorer la notation des prospects en enrichissant ses contacts CRM. Ils utilisent un outil de pipeline de données pour extraire de nouveaux prospects de leur CRM Salesforce. Le pipeline envoie ensuite le nom de l'entreprise de chaque prospect à l'API d'un fournisseur de données tiers (comme Clearbit) pour récupérer des données firmographiques, telles que la taille de l'entreprise et le secteur d'activité. Enfin, le pipeline réécrit ces données enrichies dans les enregistrements de contact correspondants dans Salesforce. Ce processus automatisé fournit à l'équipe de vente un contexte plus riche sur chaque prospect, conduisant à une priorisation plus précise et à une prise de contact plus efficace.