ParadeDB
Visiter le site web
ParadeDB Aperçu
ParadeDB se positionne comme une alternative puissante et moderne à Elasticsearch, spécifiquement conçue pour fonctionner de manière transparente au sein de l'écosystème PostgreSQL. Il transforme une base de données Postgres standard en un moteur de recherche et d'analyse haute performance, conçu pour gérer des charges de travail en temps réel et à fortes mises à jour. La mission principale de ParadeDB est de libérer les équipes de développement des complexités et des surcharges associées à la mise à l'échelle, à la gestion et à la synchronisation d'un cluster Elasticsearch distinct. En intégrant les capacités de recherche et d'analyse directement dans Postgres, il simplifie la pile de données, réduit les coûts opérationnels et élimine les problèmes courants de cohérence des données.
En tant que projet open-source, ParadeDB a gagné une traction significative au sein de la communauté des développeurs, comme en témoignent des milliers d'étoiles sur GitHub et plus de cent mille déploiements Docker. Il est approuvé par un large éventail d'entreprises, des startups à croissance rapide comme Bilt Rewards et Modern Treasury aux entreprises du Fortune 500 comme Alibaba Cloud, pour alimenter des applications critiques.
Comment utiliser ParadeDB
La prise en main de ParadeDB est conçue pour être simple pour les développeurs familiers avec Postgres. Il existe deux méthodes de déploiement principales :
- Conteneur Docker : Le moyen le plus rapide de tester et d'exécuter ParadeDB est via son image Docker officielle. Une simple commande suffit pour lancer une nouvelle instance :
docker run --name paradedb -e POSTGRES_PASSWORD=password paradedb/paradedb
Une fois en cours d'exécution, vous pouvez vous y connecter en utilisant n'importe quel client Postgres standard comme `psql`. - Extension Postgres : Pour les bases de données Postgres existantes et autogérées, ParadeDB peut être installé comme une extension standard. Cela vous permet d'augmenter votre base de données actuelle avec les fonctionnalités de ParadeDB sans migrer les données vers un nouveau système. Il s'intègre aux mécanismes internes de Postgres, tels que la réplication logique, lui permettant d'agir comme un réplica en lecture haute performance qui décharge les requêtes de recherche et d'analyse exigeantes de votre base de données principale.
Une fois installé, vous interagissez avec ParadeDB en utilisant le SQL Postgres standard. Il n'est pas nécessaire d'apprendre un nouveau langage de requête comme le Query DSL d'Elasticsearch. Vous pouvez créer des index de recherche et exécuter des requêtes complexes, filtrées et à facettes en utilisant la syntaxe SQL familière.
Fonctionnalités principales de ParadeDB
- Recherche Plein Texte Avancée : Va au-delà de la recherche intégrée de Postgres pour offrir des fonctionnalités telles que le scoring de pertinence BM25, des tokenizers personnalisés, la correspondance approximative (fuzzy matching), les requêtes de phrase et la logique booléenne complexe.
- Analyse Haute Performance : Inclut le support pour les requêtes analytiques rapides et la facettisation, alimenté par un index en colonnes. C'est idéal pour construire des tableaux de bord, des panneaux d'informations en temps réel et des explorations détaillées (drill-down).
- Zéro ETL & Synchronisation en Temps Réel : En utilisant la réplication logique native de Postgres, ParadeDB reste parfaitement synchronisé avec votre source de données principale en temps réel, éliminant le besoin de pipelines ETL complexes et fragiles (par exemple, Kafka, Debezium).
- Conformité ACID : Hérite des garanties ACID de Postgres, ce qui signifie que les données sont immédiatement et de manière cohérente consultables après une transaction d'écriture réussie.
- Opérations Simplifiées : S'intègre au processus de vacuum de Postgres pour le nettoyage automatique des index obsolètes et s'appuie sur l'écosystème robuste de Postgres pour les sauvegardes, la haute disponibilité et la reprise après sinistre.
- Interface SQL Standard : Toutes les fonctionnalités sont accessibles via le dialecte SQL standard de Postgres, ce qui réduit la courbe d'apprentissage et tire parti de l'expertise existante de l'équipe.
Cas d'utilisation pour ParadeDB
ParadeDB est testé en conditions réelles dans des environnements de production exigeants pour diverses applications :
- Bilt Rewards : La plateforme de récompenses pour le logement a déployé ParadeDB en tant que réplica logique de leur Postgres principal. Cela a permis de décharger leurs requêtes de recherche à facettes et approximatives les plus coûteuses, entraînant une réduction de 95 % des délais d'attente des requêtes et une baisse de 50 % de la latence P95 des requêtes.
- Alibaba Cloud : Le géant de la technologie a choisi ParadeDB pour intégrer de puissantes capacités de recherche plein texte dans son entrepôt de données basé sur Postgres, gérant des ensembles de données massifs avec une haute performance.
- Modern Treasury : L'API de traitement des paiements utilise ParadeDB pour alimenter la recherche sur les données de transactions financières. Ils bénéficient de sa sécurité transactionnelle, de sa nature relationnelle et de sa synchronisation parfaite, qui sont essentielles pour les applications financières.
- Applications d'Entreprise Générales : Toute application construite sur Postgres qui nécessite une recherche sophistiquée (par exemple, catalogues de produits de commerce électronique, analyse de logs, systèmes de gestion de contenu) ou des tableaux de bord d'analyse en temps réel peut bénéficier de ParadeDB.
Avantages de ParadeDB
Le principal avantage de ParadeDB est son intégration native avec Postgres, ce qui entraîne plusieurs avantages clés :
- Pile de Données Simplifiée : Consolide votre base de données et votre moteur de recherche en un seul système, réduisant la complexité de l'infrastructure et la surcharge opérationnelle.
- Cohérence des Données Garantie : Élimine le risque de perte de données ou de résultats de recherche obsolètes causés par des synchronisations rompues entre Postgres et un moteur de recherche externe.
- Coût Total de Possession Réduit : Réduit les coûts associés à la licence, à la gestion et à la mise à l'échelle d'un cluster Elasticsearch distinct.
- Productivité Accrue des Développeurs : Permet aux développeurs d'utiliser un langage de requête unique et familier (SQL) pour toutes les opérations de données, accélérant les cycles de développement.
- Fiabilité Supérieure : S'appuie sur la fiabilité, la stabilité et l'écosystème mature éprouvés de Postgres pour des fonctionnalités telles que les sauvegardes et la haute disponibilité.
Tarification et plans
ParadeDB fonctionne sur un modèle freemium, open-core. La technologie de base est open-source et gratuite, disponible en tant qu'extension Postgres ou image Docker. C'est idéal pour les développeurs, les startups et pour l'autogestion du logiciel. Pour les entreprises nécessitant des fonctionnalités avancées, un support dédié ou une solution cloud entièrement gérée, ParadeDB propose des plans commerciaux. Les parties intéressées sont encouragées à contacter l'équipe commerciale pour une démonstration et des informations de tarification personnalisées.
ParadeDB Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantParadeDBAnalyse du trafic du site web
Trafic récent
Statut
Tendance du trafic mensuel
Localisation géographique
Top 5 pays / régions
-
🇺🇸 United States52,05%
-
🇮🇳 India17,38%
-
🇨🇭 Switzerland11,76%
-
🇻🇳 Vietnam9,85%
-
🇳🇱 Netherlands8,96%
Source de trafic
| Type de source | Pourcentage |
|---|---|
|
Accès direct
|
85,65% |
|
Trafic référent
|
14,35% |
Mots-clés populaires
| Mot-clé | Coût par clic (CPC) |
|---|---|
|
$2,53
|
|
|
$0,00
|
|
|
$3,18
|
|
|
$0,00
|
|
|
$0,00
|
ParadeDB Alternatives
Voir tout
Xata
Xata est une plateforme "Postgres à l'échelle" conçue pour améliorer la vélocité des développeurs et optimiser les performances …
Xata est une plateforme "Postgres à l'échelle" conçue pour améliorer la vélocité des développeurs et optimiser les performances des bases de données. Elle offre des fonctionnalités uniques telles que des branches instantanées en copie sur écriture avec anonymisation des PII, des migrations de schéma sans interruption de service et un agent alimenté par l'IA pour le réglage automatique des performances. Déployez sur l'infrastructure de Xata ou dans votre propre cloud pour une flexibilité et une conformité maximales.
TiDB Cloud
TiDB Cloud est une base de données SQL distribuée en tant que service (DBaaS) entièrement gérée. Elle offre …
TiDB Cloud est une base de données SQL distribuée en tant que service (DBaaS) entièrement gérée. Elle offre une scalabilité horizontale, une compatibilité MySQL et des capacités de traitement hybride transactionnel/analytique (HTAP). Idéale pour créer des applications modernes, gourmandes en données et des services basés sur l'IA, elle simplifie les opérations de base de données et fournit un backend puissant pour les applications nécessitant à la fois des transactions en temps réel et des analyses complexes, y compris la recherche vectorielle pour l'IA.
InfluxData
InfluxData propose InfluxDB, la principale plateforme de base de données de séries chronologiques conçue pour les données en …
InfluxData propose InfluxDB, la principale plateforme de base de données de séries chronologiques conçue pour les données en temps réel et les applications d'IA. Elle permet aux développeurs d'ingérer, de stocker et d'analyser des volumes massifs de données à haute vélocité provenant de l'IoT, des applications et de l'infrastructure. Dotée de requêtes haute performance, d'une compression de données supérieure et d'une intégration transparente avec les lacs de données et les pipelines d'IA/ML, InfluxData est le moteur de la détection d'anomalies, de la maintenance prédictive et des systèmes autonomes.
ChartDB
ChartDB est un visualiseur de schémas de base de données alimenté par l'IA qui génère instantanément des diagrammes …
ChartDB est un visualiseur de schémas de base de données alimenté par l'IA qui génère instantanément des diagrammes ER interactifs à partir d'une seule requête. Il est conçu pour les développeurs et les équipes afin de concevoir, documenter et collaborer sur les structures de bases de données. Il propose une collaboration en temps réel, la synchronisation de base de données et un assistant IA pour optimiser la conception du schéma. Des versions cloud et auto-hébergées open source sont disponibles.
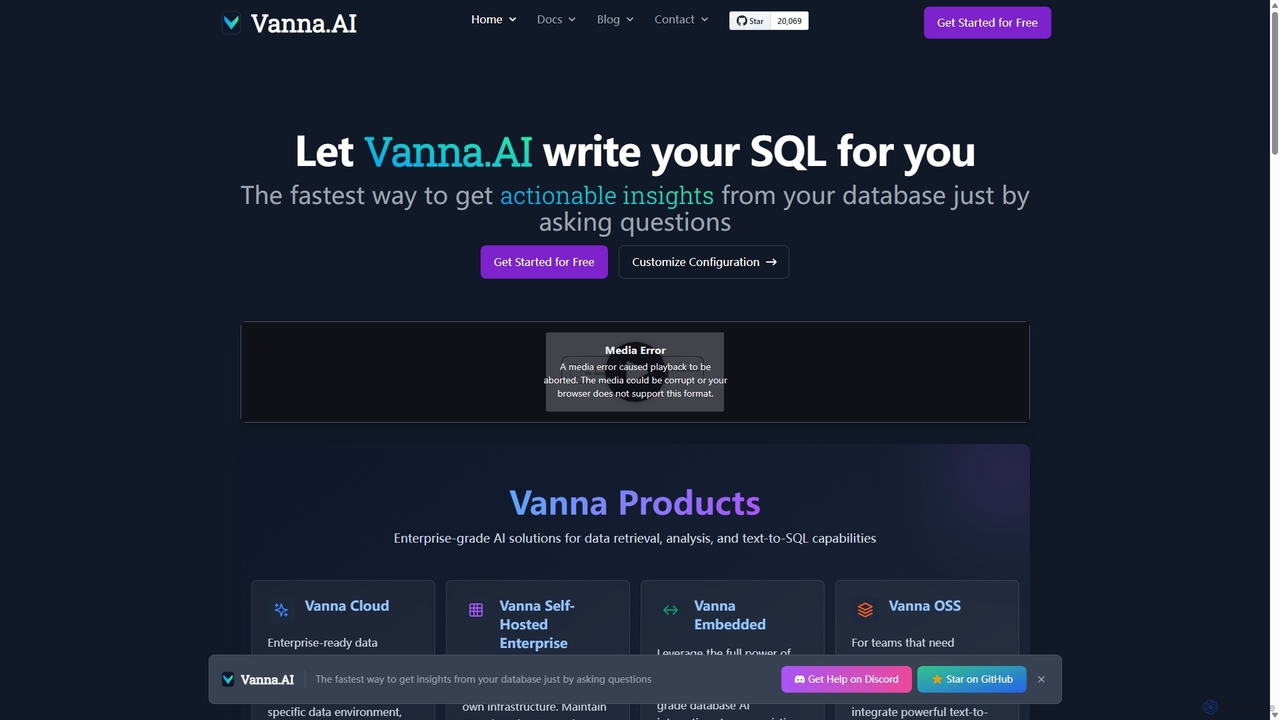
Vanna.AI
Vanna.AI est un agent SQL IA personnalisé et open-source qui transforme les questions en langage naturel en requêtes …
Vanna.AI est un agent SQL IA personnalisé et open-source qui transforme les questions en langage naturel en requêtes SQL précises. Il utilise un modèle de Génération Augmentée par Récupération (RAG) entraîné sur votre schéma de base de données spécifique, votre documentation et vos requêtes passées pour atteindre une haute précision sur des ensembles de données complexes. Il est conçu pour la sécurité, la flexibilité et une intégration facile dans n'importe quelle application, permettant aux utilisateurs techniques et non techniques d'obtenir sans effort des informations à partir de leurs données.
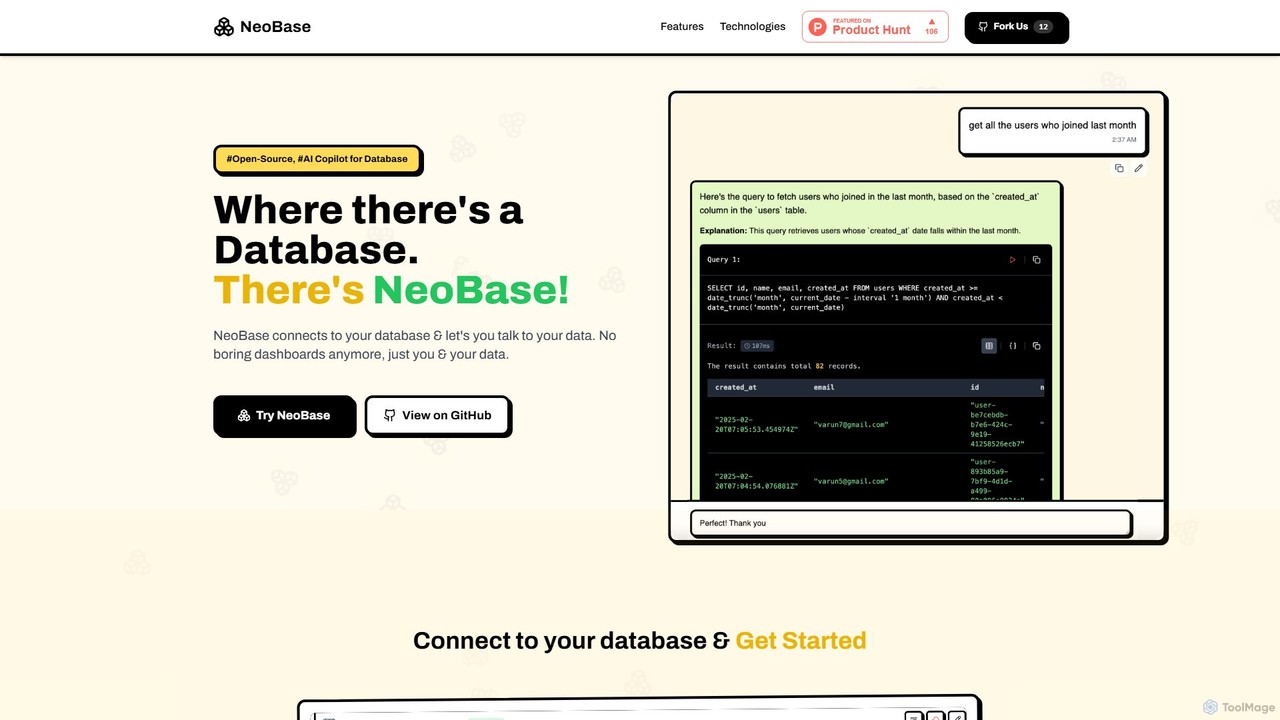
NeoBase
NeoBase est un copilote IA open-source pour bases de données, permettant aux utilisateurs d'interagir avec leurs données en …
NeoBase est un copilote IA open-source pour bases de données, permettant aux utilisateurs d'interagir avec leurs données en langage naturel. Il se connecte à diverses bases de données SQL et NoSQL, traduit des requêtes en anglais simple en code optimisé et visualise les résultats. Conçu pour les utilisateurs techniques et non techniques, il simplifie l'analyse de données, le débogage et le reporting, éliminant le besoin d'écrire des requêtes complexes et offrant un contrôle total des données grâce à l'auto-hébergement.
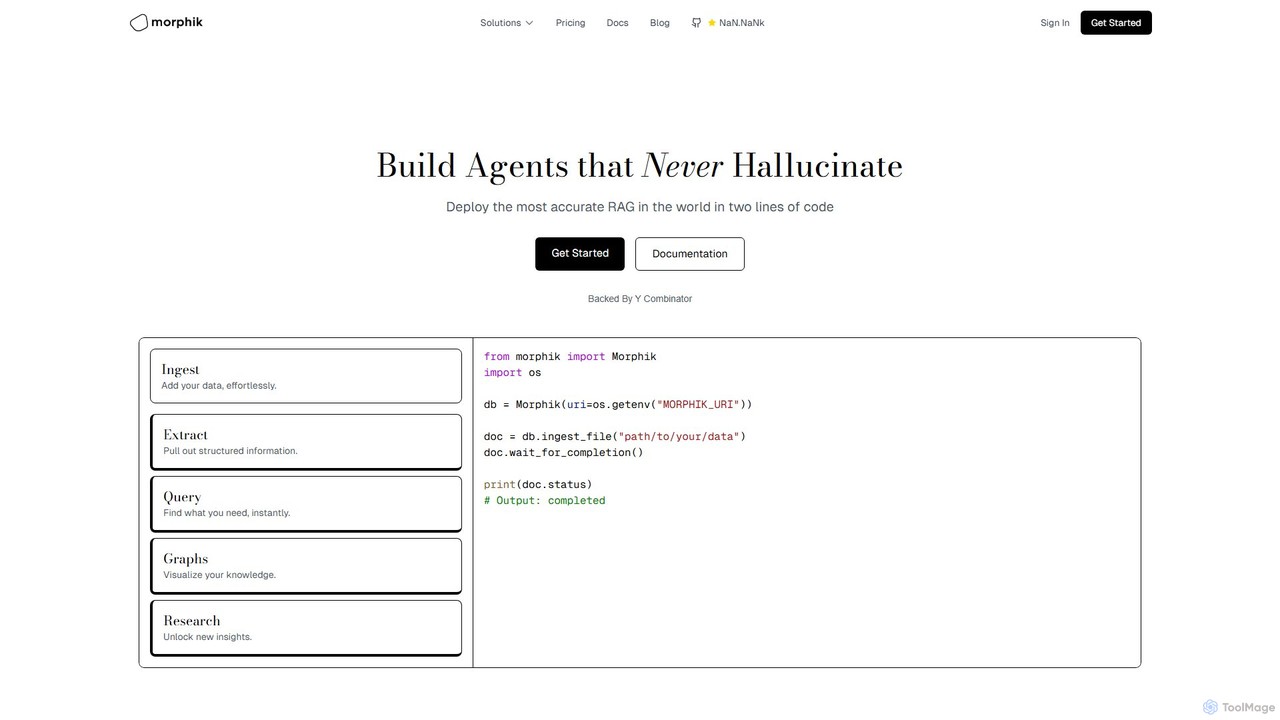
Morphik
Morphik est une plateforme de développement avancée pour créer des systèmes de Génération Augmentée par la Récupération (RAG) …
Morphik est une plateforme de développement avancée pour créer des systèmes de Génération Augmentée par la Récupération (RAG) et des agents IA de haute précision. Elle se spécialise dans l'élimination des hallucinations en utilisant une récupération visuelle prioritaire pour comprendre des documents complexes et spécifiques à un domaine, y compris les diagrammes et les schémas. Déployable en seulement deux lignes de code, elle offre des performances, une vitesse et une évolutivité supérieures pour les applications IA d'entreprise.
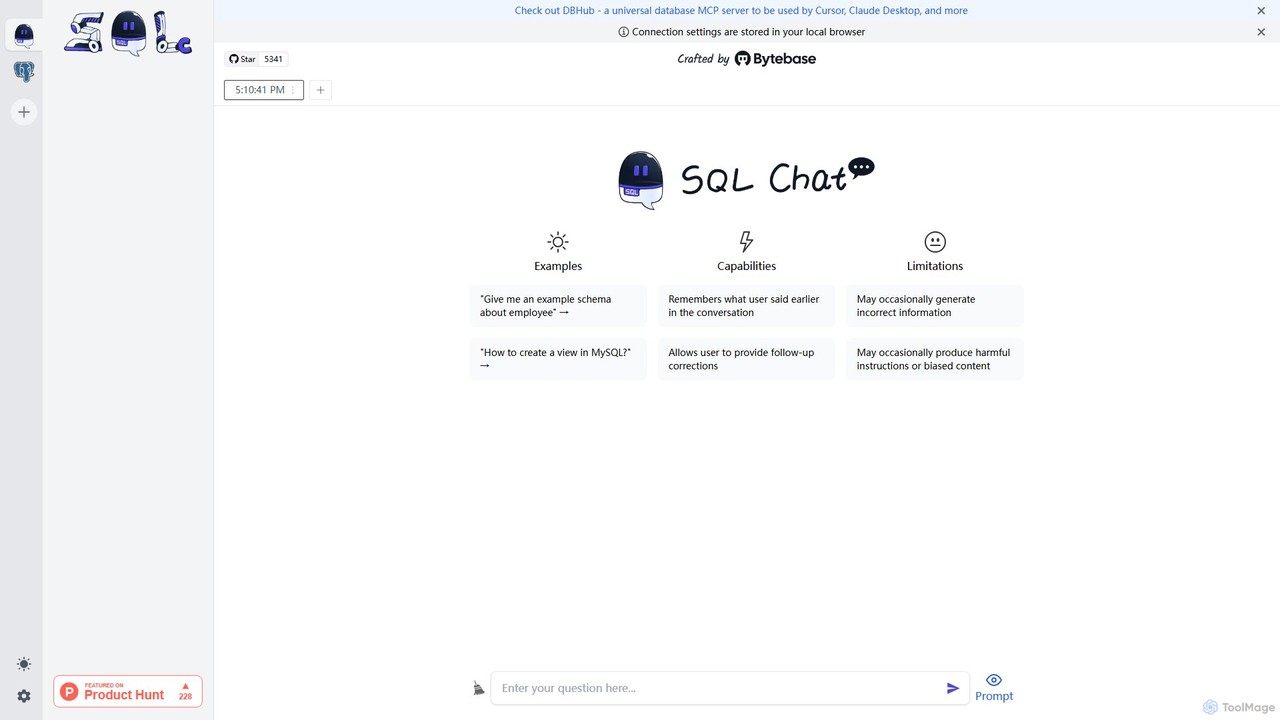
SQL Chat
SQL Chat est un client et éditeur SQL open-source basé sur le chat qui utilise l'IA pour traduire …
SQL Chat est un client et éditeur SQL open-source basé sur le chat qui utilise l'IA pour traduire les questions en langage naturel en requêtes SQL. Connectez-vous à votre base de données, posez des questions en français simple et obtenez des résultats instantanément, démocratisant l'accès aux données pour les utilisateurs techniques et non techniques.

Milvus
Milvus est une base de données vectorielle open-source haute performance conçue pour les applications d'IA. Elle permet aux …
Milvus est une base de données vectorielle open-source haute performance conçue pour les applications d'IA. Elle permet aux développeurs de gérer et de rechercher des milliards de vecteurs de haute dimension avec une latence minimale. Idéale pour construire des systèmes évolutifs comme la génération augmentée par récupération (RAG), les moteurs de recommandation et la recherche sémantique, Milvus offre des options de déploiement flexibles, du prototypage local aux clusters distribués à grande échelle.
Supadash
Supadash est une plateforme sans code alimentée par l'IA qui génère instantanément des tableaux de bord visuels à …
Supadash est une plateforme sans code alimentée par l'IA qui génère instantanément des tableaux de bord visuels à partir de votre base de données. Connectez votre source de données et, en quelques secondes, l'IA de Supadash analyse vos tables et crée des graphiques et des analyses pertinents. Il est conçu pour les développeurs, les startups et les équipes qui ont besoin de suivre des métriques clés sans écrire de requêtes SQL complexes, transformant sans effort les données brutes en informations exploitables.
ParadeDB Catégorie
ParadeDB Étiquettes
ParadeDB Outil d'IA
ParadeDB Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !