pdfparser
Visiter le site web
pdfparser Aperçu
pdfparser est un outil spécialisé et performant conçu pour libérer les données piégées dans les fichiers PDF. En s'appuyant sur une IA avancée et la technologie de reconnaissance optique de caractères (OCR), il offre une solution simple mais puissante pour convertir le contenu PDF non structuré en données structurées et exploitables. Que vous traitiez des PDF natifs ou numérisés, des factures, des rapports ou des formulaires, pdfparser automatise le processus d'extraction, économisant d'innombrables heures de saisie manuelle de données et réduisant les erreurs humaines. Sa sortie principale est un JSON propre et bien organisé, ce qui le rend incroyablement facile à intégrer pour les développeurs dans n'importe quelle application ou pipeline de traitement de données.
Comment utiliser pdfparser
L'utilisation de pdfparser est conçue pour être un processus simple, accessible via son API pour une intégration transparente dans vos projets.
- Inscrivez-vous et obtenez des crédits : Créez un compte sur le site web de pdfparser et achetez un pack de crédits adapté à vos besoins. Un crédit correspond au traitement d'un document.
- Intégration de l'API : Utilisez votre clé API unique pour authentifier vos requêtes. La documentation fournit des exemples clairs pour effectuer des appels API.
- Soumettez votre PDF : Envoyez une requête POST au point de terminaison de l'API pdfparser, en incluant le fichier PDF que vous souhaitez traiter dans le corps de la requête.
- Traitement alimenté par l'IA : Le backend du service analysera automatiquement le document. Il détecte la mise en page, identifie les blocs de texte, reconnaît les tableaux et utilise l'OCR pour tout texte basé sur une image.
- Recevez un JSON structuré : L'API renverra un objet JSON détaillé contenant tout le contenu extrait, y compris le texte brut, les données de tableau structurées (avec lignes et colonnes) et les métadonnées sur le document.
Fonctionnalités principales de pdfparser
- Moteur OCR avancé : Extrait avec précision le texte de documents numérisés, d'images à basse résolution et de mises en page complexes, prenant en charge plusieurs langues.
- Extraction intelligente de tableaux : Détecte automatiquement les tableaux dans les PDF et préserve leur structure, en convertissant les lignes et les colonnes en un tableau JSON imbriqué pour une analyse facile.
- Sortie JSON structurée : Toutes les données extraites sont livrées dans un format JSON propre, prévisible et convivial pour les développeurs, prêtes à être utilisées immédiatement dans des bases de données, des applications ou des outils d'analyse.
- API évolutive : Conçue pour les développeurs, l'API robuste peut gérer de grands volumes de documents, permettant le traitement par lots et l'extraction de données en temps réel dans les applications d'entreprise.
- Système simple basé sur les crédits : Le modèle de tarification transparent de paiement à l'utilisation vous permet de ne payer que ce que vous utilisez, ce qui le rend rentable pour les petits projets comme pour les opérations à grande échelle.
Cas d'utilisation pour pdfparser
pdfparser est un outil polyvalent applicable dans de nombreuses industries :
- Automatisation financière : Extrayez automatiquement les données des factures, des bons de commande, des reçus et des relevés bancaires pour rationaliser la comptabilité.
- Science des données et recherche : Analysez des articles universitaires, des rapports de recherche et des ensembles de données à partir de PDF pour recueillir des informations pour l'analyse sans transcription manuelle.
- Juridique et conformité : Extrayez rapidement des clauses, des détails de cas et des informations clés de contrats juridiques, de documents judiciaires et de documents réglementaires.
- Logistique et chaîne d'approvisionnement : Numérisez les connaissements, les manifestes d'expédition et les bons de livraison pour automatiser le suivi et la gestion des stocks.
- Ressources humaines : Traitez les CV et les formulaires de candidature pour extraire les informations des candidats et alimenter les systèmes de gestion des RH.
Avantages de pdfparser
L'avantage clé de pdfparser est son accent sur la simplicité et la puissance. Il abstrait la complexité de l'analyse PDF et de l'OCR, fournissant un service fiable qui fonctionne tout simplement. Cela conduit à des cycles de développement considérablement plus rapides pour les applications qui dépendent des données de documents. Sa grande précision dans l'extraction de texte et de tableaux minimise le besoin de révision et de correction manuelles. Le modèle évolutif et basé sur les crédits garantit que les entreprises de toutes tailles peuvent tirer parti du traitement de documents de niveau entreprise sans un investissement initial important.
Tarification et plans
pdfparser fonctionne sur un système de crédits simple de paiement à l'utilisation, où 1 crédit est utilisé pour analyser 1 document.
- Lite : 1,00 $ pour 10 crédits
- Standard : 5,00 $ pour 60 crédits
- Pro : 25,00 $ pour 500 crédits
Les paiements sont traités en toute sécurité par carte ou PayPal. Cette tarification flexible le rend accessible aux développeurs testant une idée, aux petites entreprises automatisant un flux de travail ou aux grandes entreprises traitant des documents à grande échelle.
pdfparser Commentaires (0)
Connectez-vous pour laisser un commentaire
Connectez-vous maintenantpdfparser Alternatives
Voir tout
Finigami AI
Finigami AI propose des solutions d'IA d'entreprise, spécialisées dans le traitement intelligent des documents (IDP) et le développement …
Finigami AI propose des solutions d'IA d'entreprise, spécialisées dans le traitement intelligent des documents (IDP) et le développement d'IA personnalisée. Elle fournit une plateforme puissante pour extraire des données de n'importe quel document, y compris du texte manuscrit et des tableaux complexes, et s'associe à des entreprises pour construire des systèmes d'IA sur mesure pour des fonctions telles que la finance, les RH et les opérations.
CambioML
CambioML propose l'API AnyParser, un puissant LLM de Vision conçu pour l'analyse de documents de haute précision. Il …
CambioML propose l'API AnyParser, un puissant LLM de Vision conçu pour l'analyse de documents de haute précision. Il extrait du texte, des tableaux, des graphiques et des paires clé-valeur à partir de PDF, d'images et de documents Office. Avec des fonctionnalités telles que la rédaction des PII, des sorties configurables et un traitement en temps réel, il est idéal pour les développeurs et les entreprises des secteurs de la finance, de la recherche et de l'analyse de données pour automatiser les flux de travail d'extraction de données tout en garantissant la confidentialité et l'efficacité.
hand_check
hand_check est un outil d'OCR avancé qui utilise l'apprentissage automatique pour extraire du texte de PDF et d'images. …
hand_check est un outil d'OCR avancé qui utilise l'apprentissage automatique pour extraire du texte de PDF et d'images. Il est spécialisé dans la conversion de documents complexes, y compris les notes manuscrites et les tableaux, en texte modifiable ou en données JSON structurées. Avec une interface conviviale et une API puissante pour les développeurs, il est idéal pour les particuliers, les développeurs et les entreprises cherchant à automatiser le traitement des documents et l'extraction de données.
Sensible
Sensible est une plateforme de traitement intelligent de documents API-first pour les développeurs. Elle utilise une analyse LLM …
Sensible est une plateforme de traitement intelligent de documents API-first pour les développeurs. Elle utilise une analyse LLM avancée et des règles basées sur la mise en page visuelle pour extraire avec précision des données structurées de n'importe quel document, tel que des PDF, des images et des feuilles de calcul. Elle est conçue pour une intégration transparente, une évolutivité et une sécurité de niveau entreprise, y compris la conformité SOC 2 et HIPAA.
Monkt
Monkt est une plateforme alimentée par l'IA qui transforme les documents et les sites web en Markdown propre …
Monkt est une plateforme alimentée par l'IA qui transforme les documents et les sites web en Markdown propre et prêt pour l'IA ou en JSON structuré. Elle prend en charge divers formats comme le PDF, Word et Excel, offrant des fonctionnalités telles que l'OCR, le traitement par lots et une API REST pour automatiser l'extraction de données et préparer des ensembles de données pour la formation des LLM.
Doctly
Doctly est un outil alimenté par l'IA qui extrait avec précision les données des PDF et autres documents. …
Doctly est un outil alimenté par l'IA qui extrait avec précision les données des PDF et autres documents. Il convertit le texte, les tableaux, les figures et les graphiques en Markdown ou JSON structuré, en préservant le formatage original. Avec une API simple et une haute précision, il est conçu pour les développeurs et les entreprises afin d'automatiser les flux de travail de traitement de documents.
extracta.ai
extracta.ai est une plateforme alimentée par l'IA conçue pour l'extraction intelligente de données à partir de documents et …
extracta.ai est une plateforme alimentée par l'IA conçue pour l'extraction intelligente de données à partir de documents et d'images. Elle automatise le processus de capture de données structurées à partir de diverses sources telles que les factures, les reçus, les contrats et les formulaires, éliminant la saisie manuelle des données et rationalisant les flux de travail métier.
Upstage
Upstage fournit des modèles d'IA de haute performance et de qualité entreprise pour les entreprises. Sa suite comprend …
Upstage fournit des modèles d'IA de haute performance et de qualité entreprise pour les entreprises. Sa suite comprend le puissant LLM Solar pour les tâches linguistiques, une IA documentaire avancée pour analyser et extraire des données avec une grande précision, et des options de déploiement flexibles (API, sur site, cloud) pour automatiser les flux de travail complexes.
pdfmerse
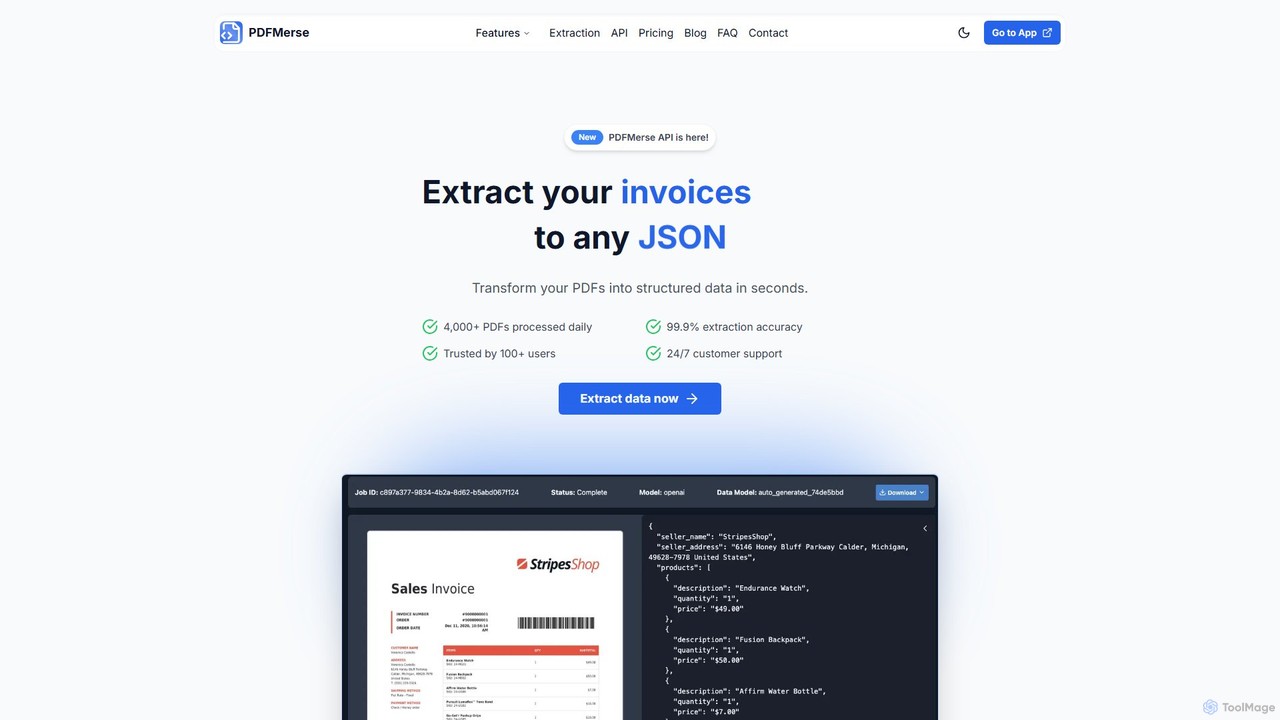
pdfmerse est un extracteur de données alimenté par l'IA qui automatise le processus de capture d'informations à partir …
pdfmerse est un extracteur de données alimenté par l'IA qui automatise le processus de capture d'informations à partir de n'importe quel document PDF. Il convertit intelligemment les données PDF non structurées en formats structurés comme JSON et texte. Idéal pour les entreprises et les particuliers cherchant à rationaliser le traitement des documents, à réduire la saisie manuelle des données et à améliorer l'efficacité des flux de travail avec une grande précision.

FormX.ai
FormX.ai est une plateforme alimentée par l'IA qui automatise l'extraction de données de n'importe quel document. Elle utilise …
FormX.ai est une plateforme alimentée par l'IA qui automatise l'extraction de données de n'importe quel document. Elle utilise une IA avancée, y compris des LLM et des modèles de vision, pour traiter les factures, les reçus, les cartes d'identité, et plus encore, rationalisant les flux de travail métier et améliorant l'efficacité opérationnelle.
pdfparser Catégorie
pdfparser Étiquettes
pdfparser Outil d'IA
pdfparser Fonction d'intégration
Copiez simplement le code d'intégration ci-dessous et collez ce superbe badge sur votre blog, article ou site officiel pour diriger le trafic directement vers la page de cet outil et augmenter rapidement votre visibilité et votre base d'utilisateurs !

Aucun commentaire pour l'instant, soyez le premier à commenter !