Scorecard
Scorecardは、エンタープライズAIエージェントを評価、最適化、展開するためのエンドツーエンドのプラットフォームです。主観的なテストを構造化された評価に置き換え、継続的な監視、プロンプト管理、パフォーマンスメトリクスのツールを提供し、信頼性の高いAIアプリケーションを自信を持って構築するのに役立ちます。
Scorecardは、エンタープライズAIエージェントを評価、最適化、展開するためのエンドツーエンドのプラットフォームです。主観的なテストを構造化された評価に置き換え、継続的な監視、プロンプト管理、パフォーマンスメトリクスのツールを提供し、信頼性の高いAIアプリケーションを自信を持って構築するのに役立ちます。
評価について
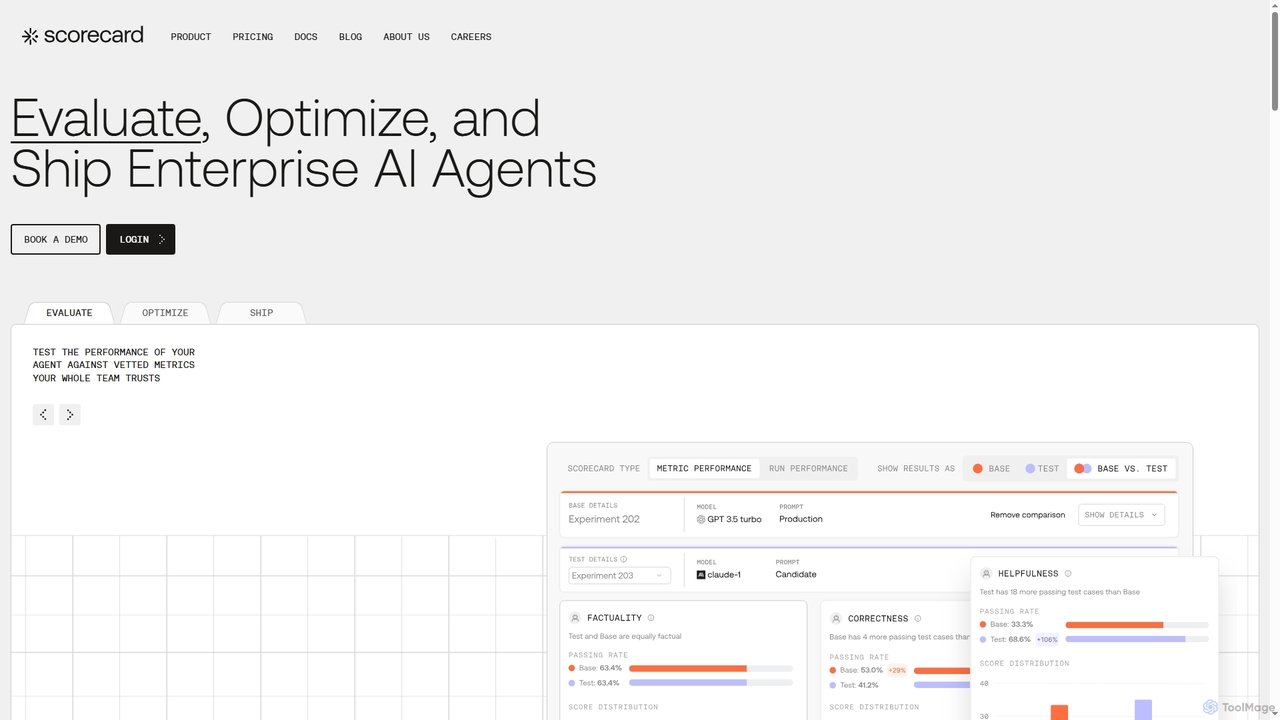
評価ツールは、AIモデルの性能、公平性、堅牢性を体系的に評価するために設計されたAI駆動型ソリューションです。これらのツールは、様々なメトリクス、テストデータセット、分析フレームワークを活用して、モデルの挙動に関する深い洞察を提供します。その主な目的は、デプロイ前後においてモデルが信頼性、正確性、倫理的健全性を備えていることを保証し、より広範なAIモデル管理ライフサイクルにおいて重要な役割を果たすことです。
主要機能
- 性能メトリクス計算:モデルの精度、適合率、再現率、F1スコア、その他の関連メトリクスを定量化します。
- バイアス検出と軽減:異なる人口統計グループやデータセグメントにおけるアルゴリズムのバイアスを特定し、測定します。
- 堅牢性テスト:敵対的攻撃や予期せぬデータシフトに対するモデルの安定性と回復力を評価します。
- 説明可能性(XAI)統合:モデルが特定の予測を行った理由に関する洞察を提供し、透明性を高めます。
- モデルバージョン比較:異なるモデルのイテレーションやバージョンの性能を比較し、改善を追跡します。
利用シーン
AIモデル評価ツールは、AIライフサイクルの様々な段階で不可欠です。データサイエンティストは、新しいモデルが性能ベンチマークを満たしていることを確認するために、厳格なデプロイ前検証にこれらを使用します。MLOpsチームは、デプロイされたモデルの継続的な監視に依存し、性能のドリフトやデータ品質の問題を検出します。さらに、研究者や開発者は、これらのツールを活用して異なるモデルアーキテクチャを比較し、AIソリューションを最適化します。
選択のポイント
AIモデル評価ツールを選択する際には、いくつかの要素を考慮する必要があります。モデルタイプとビジネス目標に関連する包括的な評価メトリクスをサポートするツールを優先してください。既存のMLOpsパイプラインやデータソースとの強力な統合機能を重視しましょう。スケーラビリティ、説明可能性機能、堅牢なレポート機能も、効果的なモデルガバナンスとコンプライアンスにとって重要です。
評価利用シーン
デプロイ前モデル検証
データサイエンティストは、不正検出システムなどの新しいAIモデルをデプロイする前に、多様なデータセットに対して厳密にテストするために評価ツールを使用します。これにより、モデルが精度と信頼性のベンチマークを満たしていることを確認し、本番環境で高価なエラーにつながる可能性のある潜在的な弱点やエッジケースを特定します。このプロセスは、モデルの実世界でのアプリケーションへの準備状況を検証し、リスクを最小限に抑えるのに役立ちます。
バイアスと公平性の評価
AI倫理学者や開発者は、ローン申請や採用などに使用されるモデル内のバイアスを体系的に検出し、定量化するために評価プラットフォームを利用します。異なる人口統計グループ間の予測を分析することで、不公平な結果を特定し、その根本原因を理解し、差別的な行動を軽減するための戦略を実行して、倫理的なAIデプロイメントを保証します。
継続的な性能監視
MLOpsエンジニアは、評価ツールを本番パイプラインに統合し、レコメンデーションエンジンなどのデプロイされたAIモデルの性能を継続的に監視します。これらのツールは、時間の経過とともに主要なメトリクスを追跡し、性能の低下、データドリフト、またはコンセプトドリフトが発生した場合にチームに警告を発し、モデルの精度と関連性を維持するためのプロアクティブな介入を可能にします。
比較モデル選択
機械学習の研究者は、複数の候補モデルや同じモデルの異なるバージョンの性能を比較するために評価ツールを利用します。例えば、自然言語処理モデルを開発する際、どのアーキテクチャやハイパーパラメータのセットが様々な言語タスクで最良の結果をもたらすかを客観的に評価し、最適なモデル選択を導きます。
規制遵守レポート
金融やヘルスケアなどの規制産業の企業は、AIシステムに関する包括的な監査証跡と性能レポートを作成するために評価ツールを使用します。これにより、説明責任の義務付けや公平性ガイドラインなどの業界標準や規制要件への準拠を実証し、監査人や利害関係者に対して透明性と説明責任を提供します。
敵対的堅牢性テスト
セキュリティ専門家は、評価ツールを適用して、特に自動運転やサイバーセキュリティなどの重要なアプリケーションにおけるAIモデルを敵対的攻撃に対してテストします。モデルを欺くように設計された悪意のある入力をシミュレートすることで、その堅牢性を評価し、脆弱性を特定し、高度な脅威に対するモデルの回復力を強化し、敵対的な環境での信頼性を確保します。