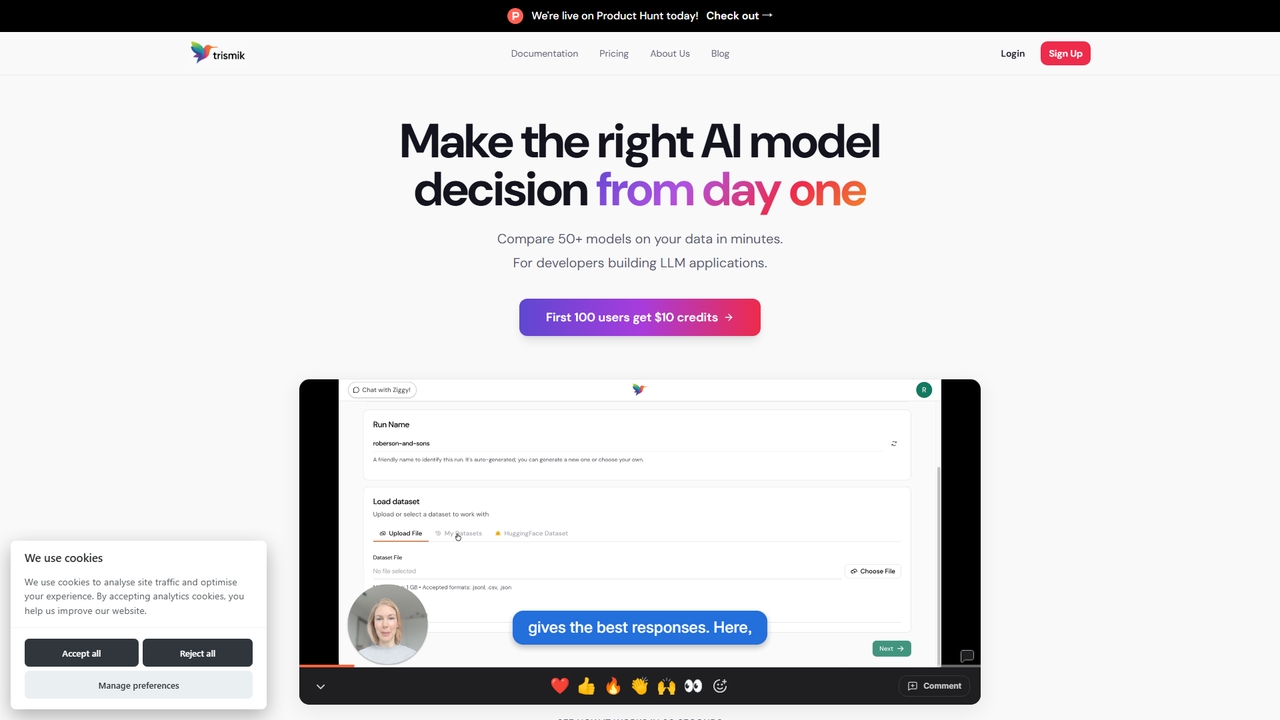
Trismik
独自のデータで50以上のLLMを数分で比較。品質、コスト、速度に関するエビデンスに基づいたモデル決定を。
独自のデータで50以上のLLMを数分で比較。品質、コスト、速度に関するエビデンスに基づいたモデル決定を。
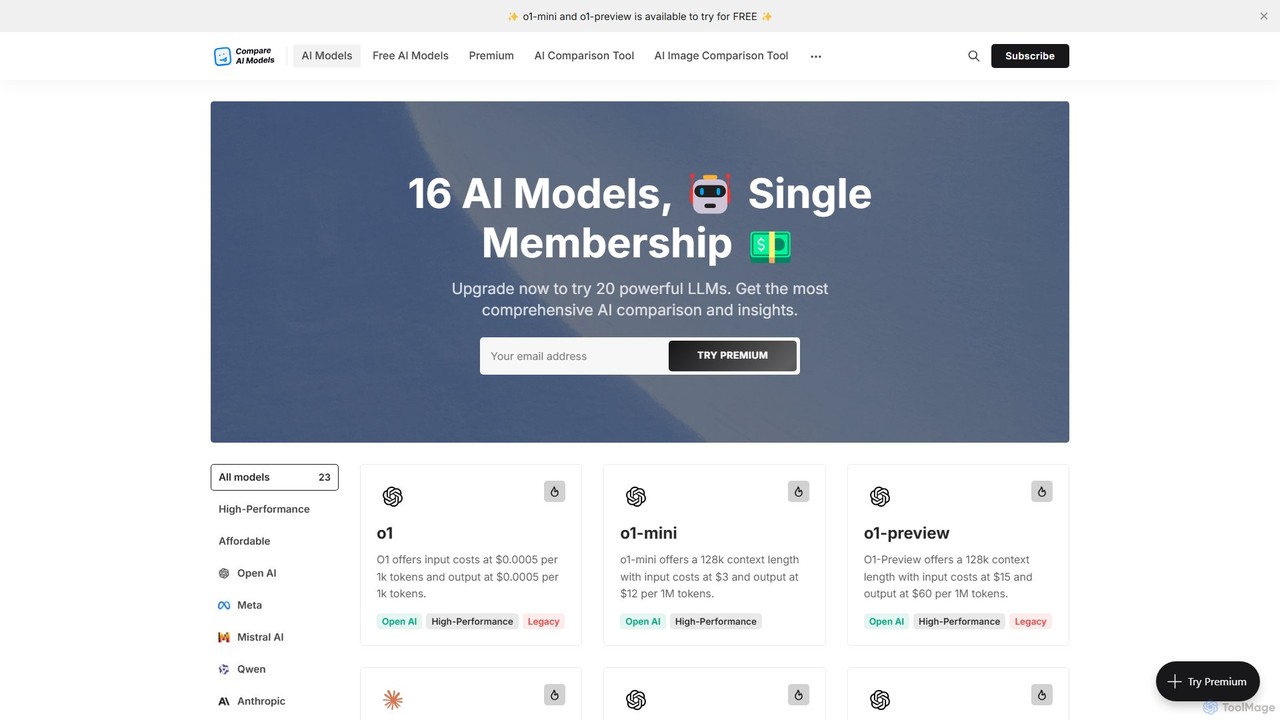
Compare AI Models
20以上の主要な大規模言語モデル(LLM)を比較するための包括的なプラットフォーム。性能、API価格、コンテキストウィンドウ、機能に関する詳細な指標を提供し、モデルを直接テストできる無料チャットも備えています。開発者、研究者、ビジネスが完璧なAIを見つけるための必須ツールです。
20以上の主要な大規模言語モデル(LLM)を比較するための包括的なプラットフォーム。性能、API価格、コンテキストウィンドウ、機能に関する詳細な指標を提供し、モデルを直接テストできる無料チャットも備えています。開発者、研究者、ビジネスが完璧なAIを見つけるための必須ツールです。
Joythee AI
Joythee AIは、複数のAIエージェントと同時にチャットできる高度な会話型AIプラットフォームです。単一のインターフェースで様々なLLMからの応答を比較し、パーソナライズされた会話を楽しみ、シークレットモードでプライバシーを保護します。生産性と創造性の向上を目指す個人、チーム、企業に最適です。
Joythee AIは、複数のAIエージェントと同時にチャットできる高度な会話型AIプラットフォームです。単一のインターフェースで様々なLLMからの応答を比較し、パーソナライズされた会話を楽しみ、シークレットモードでプライバシーを保護します。生産性と創造性の向上を目指す個人、チーム、企業に最適です。
モデル比較について
モデル比較ツールは、開発者ツールキット内にある専門的なプラットフォームで、異なるAIモデルのパフォーマンスを体系的に評価、ベンチマーク、比較するために設計されています。これらのツールは、LLMや画像ジェネレーターなどのモデルを同じ入力やデータセットに対して実行し、その出力を客観的に測定するための構造化された環境を提供します。データに基づいた意思決定に不可欠であり、開発者や研究者が特定のアプリケーションに最も正確で費用対効果が高く、効率的なモデルを選択するのに役立ちます。並列分析と定量的メトリクスを提供することで、複雑で時間のかかるモデル選択プロセスを効率化します。
主な機能
- サイドバイサイド・プレイグラウンド:統一されたインターフェースで、同じプロンプトに対する複数モデルの出力を即座に比較します。
- 自動ベンチマーキング:標準的な業界ベンチマーク(例:MMLU、HumanEval)を実行し、様々な能力についてモデルをスコアリングします。
- コストとレイテンシー分析:各モデルの推論にかかる費用と応答時間を追跡・比較します。
- 定性的評価:一貫性、スタイル、安全性などの主観的な基準について、人間によるフィードバックとスコアリングを促進します。
- バージョン管理と履歴:評価実験を記録・追跡し、パフォーマンスの変化やリグレッションを監視します。
利用シーン
これらのツールは、AI開発者、MLOpsエンジニア、プロダクトマネージャーにとって、開発および保守のライフサイクルにおいて非常に重要です。新機能の基盤モデルを選択したり、ファインチューニングの影響を評価したり、モデル更新後にリグレッションテストを実施したりする際に使用されます。例えば、カスタマーサービスのチャットボットを構築するチームは、これらのツールを使用してOpenAI、Anthropic、Googleのモデルの対話能力とコストを比較し、採用するモデルを決定します。
選択のポイント
モデル比較ツールを選択する際は、プロプライエタリAPIとオープンソースオプションの両方を含む、サポートされているモデルの幅広さを考慮してください。利用可能なベンチマークスイートと、カスタム評価データセットを作成する柔軟性を評価します。既存のMLOpsワークフローやCI/CDパイプラインとの統合能力を査定することも重要です。最後に、チームメンバーが結果をレビューできるコラボレーション機能や、評価ニーズに応じてスケールする価格モデルを検討してください。
モデル比較利用シーン
新しいチャットボットに最適なLLMの選定
ある製品チームが、新しいAI搭載のカスタマーサポートチャットボットを開発しています。彼らはモデル比較ツールを使用して、GPT-4、Claude 3 Sonnet、Llama 3 70Bを評価します。100件の一般的な顧客からの問い合わせを含む「ゴールデンデータセット」を作成し、3つのモデルすべてをそれでテストします。プラットフォームは、応答のサイドバイサイド表示と、有用性やトーンに関する自動化されたメトリクスを提供します。また、各モデルの1000会話あたりの平均コストも計算します。結果に基づき、彼らは特定のユースケースにおいて会話の質と運用コストのバランスが最も良いClaude 3 Sonnetを選択しました。
ファインチューニングされたモデルのパフォーマンス評価
あるMLエンジニアが、質疑応答タスクのために、社内文書でオープンソースのMistral 7Bモデルをファインチューニングしました。デプロイを正当化するため、彼らは比較ツールを使用して、ファインチューニングされたモデルをベースのMistral 7BモデルやGPT-4のようなプロプライエタリモデルと比較してベンチマークします。50の技術的な質問からなるテストセットをアップロードします。ツールは事実の正確性と関連性を測定します。結果、ファインチューニングされたモデルはベースモデルよりも精度が30%高く、GPT-4よりも10倍安価であることが示され、デプロイを進めるための明確な証拠となりました。
モデルAPI更新のためのリグレッションテスト
あるMLOpsチームが、外部モデルAPIに依存する要約機能を管理しています。APIプロバイダーが新しいバージョンを発表しました。切り替える前に、チームはモデル比較プラットフォームを使用して、500のテストドキュメントスイートを旧バージョンと新バージョンの両方のAPIで実行します。プラットフォームは、新バージョンの要約で、旧バージョンの出力と比較して著しく短い、一貫性がない、または事実と異なるものを自動的にフラグ付けします。この自動化されたリグレッションテストにより、サービス品質の低下を防ぎ、更新されたモデルへのスムーズな移行を保証します。
マーケティング用の画像生成モデルの比較
あるマーケティング代理店が、広告クリエイティブを作成するための画像生成モデルを選択する必要があります。彼らは比較ツールを使用して、クライアントの製品に関連する20の異なるプロンプトでDALL-E 3、Midjourney、Stable Diffusionをテストします。このツールにより、クリエイティブチームは生成された各画像を、プロンプトへの忠実度、美的品質、ブランド適合性について1〜5のスケールで評価できます。集計されたスコアから、Midjourneyが最も美的に優れた画像を生成する一方で、DALL-E 3はプロンプトで言及された特定の製品詳細を正確に組み込む点で優れており、彼らのニーズにとってより良い選択であることが明らかになりました。
要約APIのコストパフォーマンスの最適化
あるニュース集約サービスが、記事の要約にLLMを使用しています。コストを削減するため、品質を維持しつつ最も安価なモデルを見つけたいと考えています。比較ツールを使用して、ハイエンドのGPT-4から小規模なオープンソースの代替品まで、5つの異なるモデルをテストします。各モデルで1,000本の記事を処理し、自動化されたROUGEスコアで要約の品質を測定し、ツールは各モデルのコストを追跡します。その結果、Llama 3 8Bモデルの量子化バージョンが、GPT-4の95%の品質をわずか10%のコストで提供することを発見し、大幅な月間節約につながりました。
複数モデルにわたるプロンプトのA/Bテスト
あるプロンプトエンジニアが、コード生成機能のための最も効果的なプロンプトを作成する任務を負っています。プロンプトを一つずつテストする代わりに、彼らはモデル比較ツールを使用してマトリックス実験を設定します。3つの異なるプロンプトバリエーションを入力し、4つのモデル(例:GPT-4、Claude 3 Opus、Gemini Pro、および専門のコードモデル)でテストします。プラットフォームは12の組み合わせすべてを実行し、結果をヒートマップで表示し、どのプロンプトとモデルのペアが最も正確で効率的なコードを生成するかを示します。これにより、プロンプトの最適化プロセスが10倍加速します。