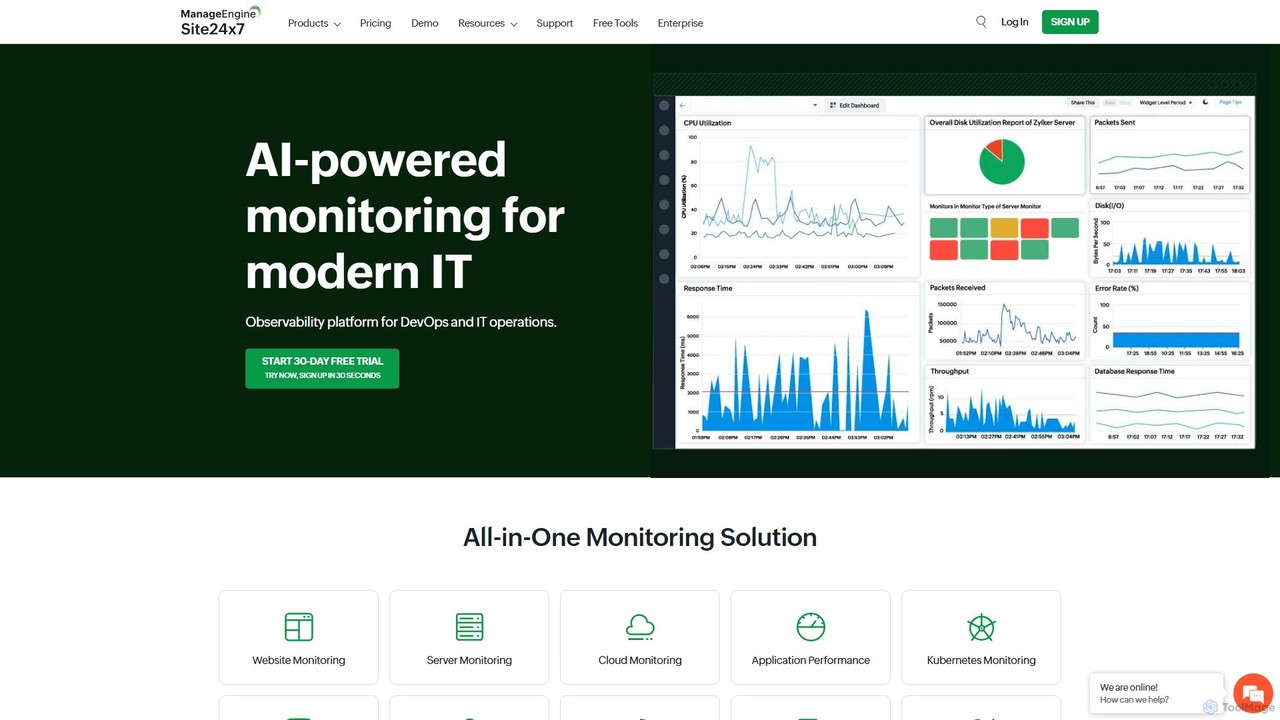
Site24x7
Site24x7は、DevOpsおよびIT運用向けのAI搭載オールインワンオブザーバビリティプラットフォームです。単一のコンソールからウェブサイト、サーバー、クラウドインフラ(AWS、Azure、GCP)、ネットワーク、アプリケーションの包括的な監視を提供します。アップタイムの確保、パフォーマンス問題のトラブルシューティング、ユーザーエクスペリエンスの最適化を支援します。
Site24x7は、DevOpsおよびIT運用向けのAI搭載オールインワンオブザーバビリティプラットフォームです。単一のコンソールからウェブサイト、サーバー、クラウドインフラ(AWS、Azure、GCP)、ネットワーク、アプリケーションの包括的な監視を提供します。アップタイムの確保、パフォーマンス問題のトラブルシューティング、ユーザーエクスペリエンスの最適化を支援します。
インフラ監視について
AIインフラ監視ツールは、人工知能を使用してITシステムの健全性とパフォーマンスを自動的に監視、分析、管理するプラットフォームです。これらのツールは機械学習アルゴリズムを活用し、サーバー、ネットワーク、クラウドサービス全体でリアルタイムに異常を検知し、潜在的な障害を予測し、根本原因を特定します。その主な価値は、IT運用を事後対応型から事前対応型へと転換させ、ダウンタイムを大幅に削減し、リソース配分を最適化することにあります。この高度な監視は、現代のITおよびセキュリティにおいて、システムの信頼性と安定性を確保するための重要な要素です。
主な機能
- 予測的異常検知:機械学習を用いて異常なパターンや潜在的な問題を、重大な障害に発展する前に特定します。
- 自動根本原因分析(RCA):様々なソースからのデータを自動的に関連付け、問題の正確な原因を特定し、手動調査時間を短縮します。
- インテリジェントアラート:関連するアラートをグループ化し、ノイズを抑制することで、アラート疲れを軽減し、チームが優先度の高いインシデントに集中できるようにします。
- キャパシティプランニングと予測:過去のトレンドを分析して将来のリソース需要を予測し、パフォーマンスのボトルネックを防ぎ、コストを最適化します。
利用シーン
これらのツールは、複雑で動的な環境を管理するDevOpsエンジニア、サイト信頼性エンジニア(SRE)、IT運用チームにとって不可欠です。ピーク時のトラフィック中の稼働時間を確保するためにEコマース分野で、取引システムの安定性を維持するために金融サービスで、またサービスレベル契約(SLA)を遵守するためにSaaS企業で広く使用されています。
選択のポイント
AIインフラ監視ツールを選択する際は、既存の技術スタック(例:Kubernetes、AWS、Azure)との統合能力を考慮してください。AI機能の深さ(真の予測分析を提供するか、基本的な異常検知のみか)を評価します。また、データ量を処理するためのスケーラビリティや、効果的な意思決定のためのデータ可視化とダッシュボードの明確さも評価する必要があります。
インフラ監視利用シーン
Eコマースプラットフォームのプロアクティブな障害防止
大手Eコマース企業のSREチームは、大規模なセールイベントに備えるためにAIインフラ監視ツールを使用しています。過去のトラフィックデータでトレーニングされたツールの予測分析モデルは、データベース負荷が300%急増すると予測します。この予測に基づき、チームはイベント開始の2時間前にプロアクティブにデータベースリソースをスケールアップし、クエリパフォーマンスを最適化します。その結果、プラットフォームはパフォーマンスの低下やダウンタイムなしにピークトラフィックを処理し、スムーズな顧客体験を確保し、収益を最大化しました。
マイクロサービスにおける自動根本原因分析
DevOpsチームは、数百のマイクロサービスで構築された複雑なアプリケーションを管理しています。ユーザーから応答時間が遅いと報告されると、AI監視ツールはすべてのサービスのメトリクス、ログ、トレースを自動的に分析します。エンジニアが手動でデータをふるいにかける代わりに、ツールのRCA機能が数分以内にメモリリークのある特定の「支払いサービス」マイクロサービスを根本原因として特定します。問題の影響の相関ビューを提示し、チームがすぐに努力を集中させ、修正をデプロイし、従来のメソッドよりも90%速くサービスパフォーマンスを回復できるようにします。
キャパシティ予測によるクラウドコストの最適化
ITマネージャーは、会社の月々のクラウドコンピューティング費用を削減する任務を負っています。AIインフラ監視ツールを使用して、仮想マシンインスタンスの過去の使用パターンを分析します。ツールの予測機能は、ピーク時でさえ、インスタンスの20%が一貫して過剰にプロビジョニングされ、十分に活用されていないと予測します。このデータに基づいた洞察に基づき、マネージャーは自信を持ってインスタンスのサイズを適正化し、アプリケーションのパフォーマンスに影響を与えることなく、月々のクラウド支出を直接15%削減することに成功しました。
NOCチームのアラート疲れの軽減
ネットワークオペレーションセンター(NOC)チームは、従来の監視システムから毎日何千もの個別のアラートに圧倒され、重要なインシデントを見逃すことがありました。AI監視ツールを導入した後、そのインテリジェントなアラート機能が関連イベントを自動的に相関させます。例えば、以前は50件の個別の「サーバー到達不能」アラートを生成していた単一のネットワークスイッチの障害は、今では「ネットワークスイッチ障害が50台のサーバーに影響」というタイトルの1つの高優先度インシデントに統合されます。これにより、アラート量が80%以上削減され、NOCチームは症状ではなく根本的な問題に集中できるようになります。
SaaSプロバイダーのSLAコンプライアンスの確保
B2B SaaSプロバイダーは、企業クライアントと厳格な99.9%の稼働時間サービスレベル契約(SLA)を結んでいます。彼らはAIインフラ監視ツールを使用して、アプリケーションの応答時間、サーバーのCPU使用率、データベースのレイテンシなどの主要業績評価指標(KPI)を継続的に追跡します。ツールのAIは、24時間以内にSLA違反につながる可能性のあるデータベースレイテンシの微妙で段階的な増加を検出します。高優先度の通知で運用チームに警告し、顧客に影響が及ぶ前にパフォーマンスの悪いデータベースインデックスを特定して解決できるようにし、SLAのコミットメントを成功裏に維持します。
クラウドネイティブ環境における動的なリソース割り当て
金融テクノロジー企業は、Kubernetesクラスターで取引プラットフォームを運営しています。ワークロードは一日を通して予測不能に変動します。AI監視ツールは、リソース消費パターンを継続的に分析し、今後の需要の急増を高い精度で予測します。KubernetesのHorizontal Pod Autoscalerと統合し、実行中のポッドの数をリアルタイムで動的に調整します。これにより、プラットフォームは常に取引量を遅延なく処理するのに十分なリソースを確保し、静かな期間には自動的にスケールダウンしてクラウドコストを25%以上節約します。