



Avian 概要
Avianは、市場で最速かつ最も信頼性の高いAI推論を提供するために設計された、最先端のAIインフラストラクチャプラットフォームです。AIアプリケーションに高スループット、低レイテンシーのパフォーマンスを必要とする開発者、AIエンジニア、企業を対象としています。NVIDIA B200やH200 GPUなどの最新ハードウェアと、投機的デコーディングなどの高度な最適化技術を活用することで、Avianは業界をリードする速度を達成し、DeepSeek R1のようなモデルで毎秒351トークンという新しいベンチマークを打ち立てています。
このプラットフォームは、多様なニーズに対応するために、柔軟なサーバーレスAPIと強力な専用デプロイメントという2つの主要なサービスを提供しています。このデュアルアプローチにより、ユーザーは簡単なAPIコールでトップクラスのモデルをアプリケーションに迅速に統合することも、インフラストラクチャを完全に制御して特殊なタスク用のカスタム、ファインチューニングされたモデルを実行することも可能です。Avianはスケーラビリティを重視して構築されており、レート制限なしで運用されるため、アプリケーションがプロトタイプから本格的な本番環境へと成長するのをサポートします。
Avianの使い方
Avianの利用開始は簡単で、開発者の効率を考慮して設計されています。その能力を活用するには、主に2つの方法があります。
- AvianサーバーレスAPIの使用: これは高性能モデルにアクセスする最も迅速な方法です。開発者はサインアップしてAPIキーを取得し、様々なモデルエンドポイント(例:Meta Llama 3.1シリーズ)にリクエストを送信するだけです。このプロセスは他のAI APIと同様の簡単なコード実装を含み、インフラを管理することなく既存のアプリケーションにシームレスに統合できます。
- 専用デプロイメントの構成: HuggingFaceのカスタムモデルを実行する必要がある、または一貫した高スループットのために専用リソースが必要なユーザー向けに、Avianは専用GPUインスタンスを提供します。ユーザーは希望するGPUタイプ(例:NVIDIA H200 SXM)を選択し、デプロイ期間を設定して、Avianの最適化されたインフラにモデルをデプロイできます。これは、保証されたパフォーマンスとリソース割り当てが要求される本番ワークロードに最適です。
Avianの主な機能
- 記録破りの推論速度: 毎秒最大351トークンの速度を達成し、業界平均を大幅に上回り、リアルタイムAIアプリケーションを可能にします。
- サーバーレスAPI: Meta Llama 3.1やDeepSeek R1などの高性能モデルへの従量課金制アクセスをレート制限なしで提供します。
- 専用GPUデプロイメント: 最新のNVIDIA GPU(B200、H200、H100)を搭載した専用インスタンスを提供し、HuggingFaceの任意のモデルをデプロイして、最高のパフォーマンスと制御を保証します。
- エンタープライズレベルのセキュリティ: SOC2 Type 2コンプライアンス(進行中)、GDPR準拠、TLS 1.2+暗号化、多要素認証(MFA)など、堅牢なセキュリティ対策を備えています。データは永続的に保存されず、ユーザーのプライバシーを確保します。
- スケーラブルで本番環境に対応: パフォーマンスの低下なく大量の本番ワークロードを処理できるように構築されており、企業の規模拡大をサポートします。
- データコネクタ: Looker StudioやGoogle Sheetsなどのプラットフォーム向けのコネクタスイートを提供し、Google AnalyticsやFacebook Adsなどのソースからのシームレスなデータ統合を可能にします。
Avianの使用例
Avianの高速インフラは、要求の厳しいさまざまなAIアプリケーションに適しています。
- リアルタイムチャットボットとAIアシスタント: 即座に応答できる対話型AIを強化し、自然で流暢なユーザーエクスペリエンスを提供します。
- 大規模なコンテンツ生成: プラットフォームが前例のない規模と速度で記事、マーケティングコピー、コードを生成できるようにします。
- 複雑なデータ分析と要約: 金融分析、研究、ビジネスインテリジェンスのために、膨大な量のテキストデータをリアルタイムで処理・分析します。
- 独自モデルのデプロイ: カスタムトレーニングまたはファインチューニングされたモデルを持つ企業は、Avianの専用インフラにデプロイして、本番環境で最適なパフォーマンスを得ることができます。
Avianの利点
Avianは、競争の激しいAIインフラ市場において、いくつかの重要な利点で際立っています。
- 比類なきパフォーマンス: 他の主要なクラウドプロバイダーや推論サービスと比較して3〜10倍速い推論速度を提供します。
- 柔軟性: 簡単なAPIを介した標準モデルと、専用ハードウェア上のカスタムモデルの両方をサポートし、あらゆるレベルのAI開発に対応します。
- 費用対効果: APIと専用インスタンスの両方で競争力のある価格設定を提供し、優れたコストパフォーマンスを実現します。
- 信頼性とスケーラビリティ: レート制限がなく、本番グレードのインフラを使用しているため、アプリケーションはパフォーマンスのボトルネックに陥ることなくシームレスに拡張できます。
- 強力なセキュリティ体制: データセキュリティとプライバシーへの明確なコミットメントにより、機密情報を扱う企業顧客からの信頼を築きます。
料金プラン
Avianは、さまざまな利用パターンに合わせた透明で柔軟な料金体系を提供しています。
- Avian API(従量課金制): ユーザーは入力と出力の両方に対して100万トークンごとに課金されます。価格は競争力があり、モデルによって異なります。例:
- Meta Llama 3.1 8B Instruct:100万入出力トークンあたり$0.10。
- Meta Llama 3.1 70B Instruct:100万入出力トークンあたり$0.45。
- Meta Llama 3.1 405B Instruct:100万入出力トークンあたり$1.50。
- 専用デプロイメント: 予約されたGPUインスタンスに対して秒単位で課金されます。これは高スループットのワークロードに最適です。予約インスタンスの料金例:
- NVIDIA H100 SXM (80GB HBM3):$0.00139/秒から。
- NVIDIA H200 SXM (141GB HBM3):$0.00208/秒から。
- 新ハードウェアの予約注文: AvianはNVIDIA B200などの最先端ハードウェアの予約注文も提供しており、顧客は最新技術へのアクセスを確保できます。例えば、8x NVIDIA B200セットアップでのDeepSeek R1の7日間デプロイメントは$14,000です。
Avian コメント (0)
ログインするとコメントを投稿できます
今すぐログインAvianウェブサイトトラフィック分析
最新のトラフィック状況
ステータス
月間トラフィックの傾向
地域
上位5か国/地域
-
🇺🇸 United States32.46%
-
🇬🇧 United Kingdom26.65%
-
🇮🇳 India22.60%
-
🇻🇳 Vietnam18.29%
人気キーワード
| キーワード | クリック単価 |
|---|---|
|
$1.39
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$2.52
|
Avian 代替案
すべて表示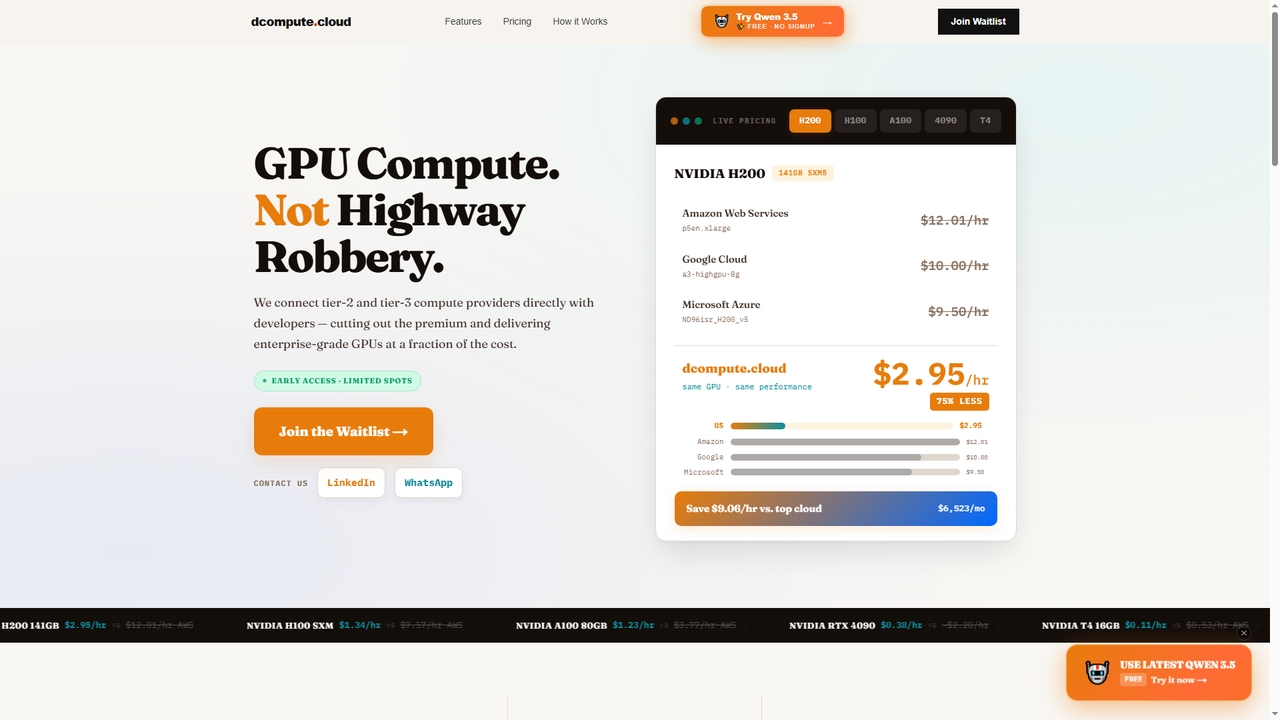
Dcompute
Dcomputeは、開発者を直接Tier-2およびTier-3データセンタープロバイダーに接続する分散型GPUコンピューティングマーケットプレイスです。主要クラウドプロバイダーのコストの数分の1でエンタープライズグレードのNVIDIA GPU(H200、H100、A100、RTX 4090、T4)を提供し、最大90%のコスト削減を実現します。プラットフォームは、即時デプロイ、統一API/ダッシュボード、完全なオーケストレーション、秒単位の純粋な従量課金(最低料金なし)を特徴としています。
Dcomputeは、開発者を直接Tier-2およびTier-3データセンタープロバイダーに接続する分散型GPUコンピューティングマーケットプレイスです。主要クラウドプロバイダーのコストの数分の1でエンタープライズグレードのNVIDIA GPU(H200、H100、A100、RTX 4090、T4)を提供し、最大90%のコスト削減を実現します。プラットフォームは、即時デプロイ、統一API/ダッシュボード、完全なオーケストレーション、秒単位の純粋な従量課金(最低料金なし)を特徴としています。
Zetic.ai
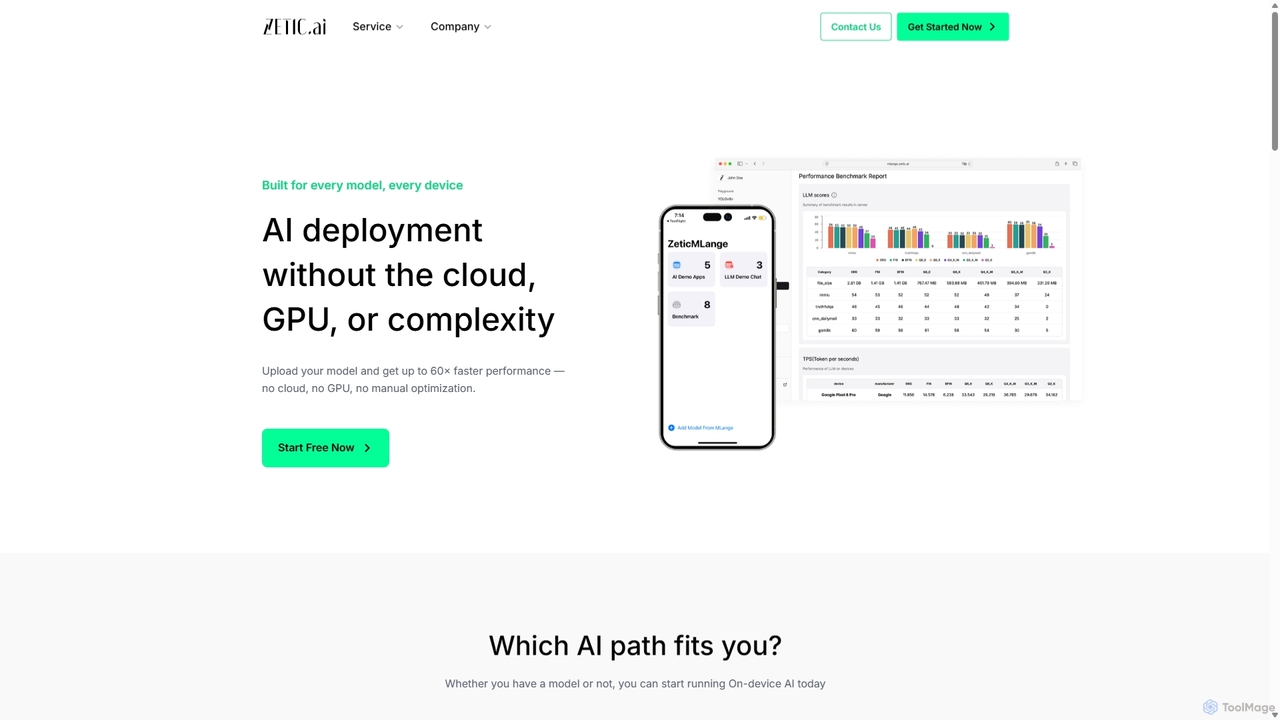
Zetic.aiは、開発者が高価なGPUサーバーなしでAIモデルをエッジデバイスに直接デプロイできるようにするプラットフォームです。その自動化パイプラインであるZETIC.MLangeは、オンデバイス実行のためにモデルを最適化・変換し、NPUアクセラレーションにより最大60倍のパフォーマンス向上を実現し、データプライバシーを確保し、遅延を削減します。
Zetic.aiは、開発者が高価なGPUサーバーなしでAIモデルをエッジデバイスに直接デプロイできるようにするプラットフォームです。その自動化パイプラインであるZETIC.MLangeは、オンデバイス実行のためにモデルを最適化・変換し、NPUアクセラレーションにより最大60倍のパフォーマンス向上を実現し、データプライバシーを確保し、遅延を削減します。
Symphony
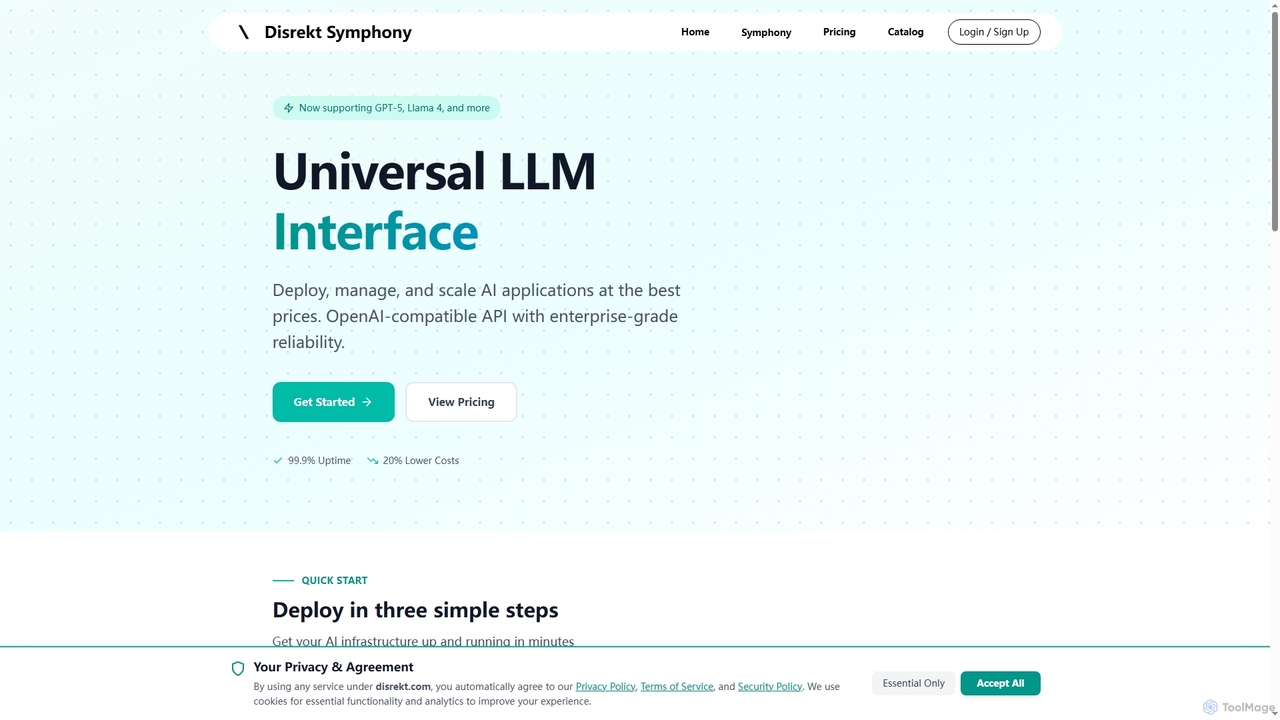
Symphonyは、OpenAI互換APIを提供するユニバーサルLLMインターフェースであり、AIアプリケーションのデプロイ、管理、スケーリングを可能にします。エンタープライズグレードの信頼性、最大20%のコスト削減、GPT-5やLlama 4を含む100以上の主要AIモデルをサポートし、効率的で堅牢なAIインフラを求める開発者や企業にとって理想的なソリューションです。
Symphonyは、OpenAI互換APIを提供するユニバーサルLLMインターフェースであり、AIアプリケーションのデプロイ、管理、スケーリングを可能にします。エンタープライズグレードの信頼性、最大20%のコスト削減、GPT-5やLlama 4を含む100以上の主要AIモデルをサポートし、効率的で堅牢なAIインフラを求める開発者や企業にとって理想的なソリューションです。
SiliconFlow
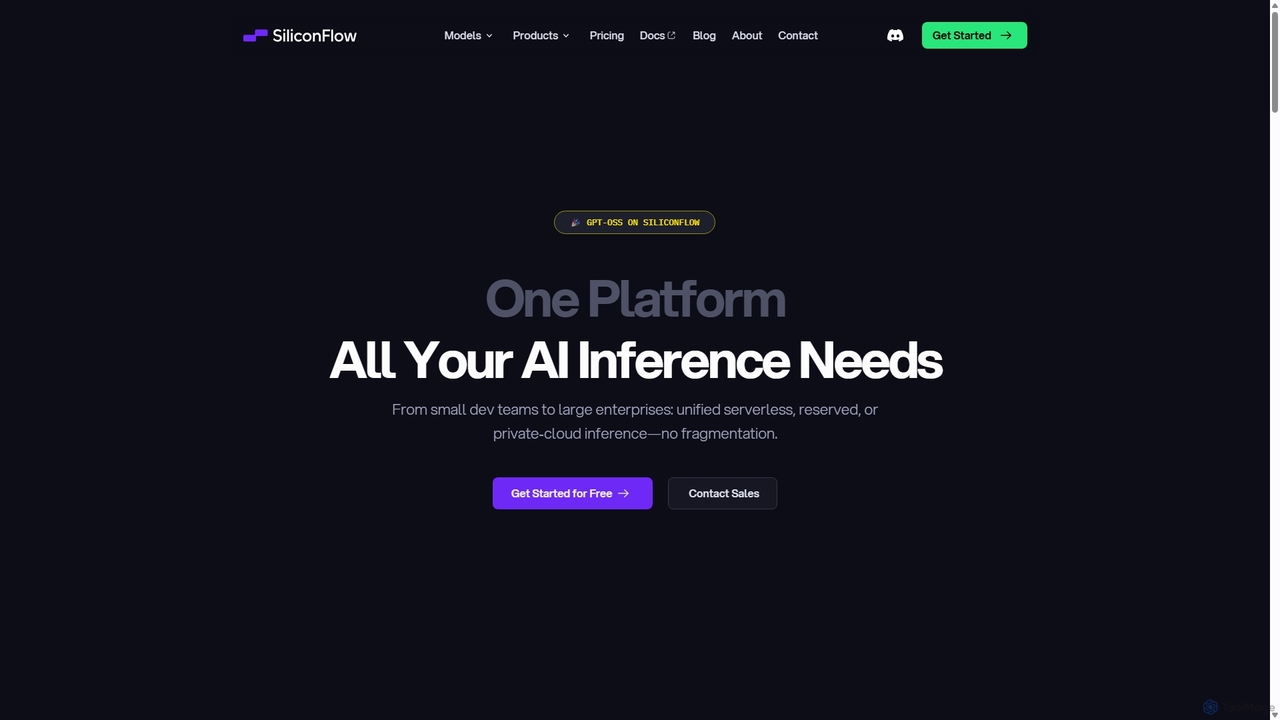
SiliconFlowは、大規模言語モデル(LLM)およびマルチモーダルモデルの高性能な推論のために設計された統合AIインフラストラクチャプラットフォームです。開発者や企業に、サーバーレスAPI、予約済みGPU、ファインチューニング機能など、スケーラブルでコスト効率の高い柔軟なデプロイメントオプションを、単一のOpenAI互換APIを通じて提供します。
SiliconFlowは、大規模言語モデル(LLM)およびマルチモーダルモデルの高性能な推論のために設計された統合AIインフラストラクチャプラットフォームです。開発者や企業に、サーバーレスAPI、予約済みGPU、ファインチューニング機能など、スケーラブルでコスト効率の高い柔軟なデプロイメントオプションを、単一のOpenAI互換APIを通じて提供します。

Baseten
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。
Nexlayer
Nexlayerは、AIコーディングエージェントが本番環境対応のアプリケーションを迅速にデプロイできるように設計された、最初のエージェントネイティブクラウドプラットフォームです。複雑なインフラストラクチャを自動化し、開発者や創業者がDevOpsのオーバーヘッドなしに、フルスタックアプリ、API、データベースを数分でリリースできるようにします。
Nexlayerは、AIコーディングエージェントが本番環境対応のアプリケーションを迅速にデプロイできるように設計された、最初のエージェントネイティブクラウドプラットフォームです。複雑なインフラストラクチャを自動化し、開発者や創業者がDevOpsのオーバーヘッドなしに、フルスタックアプリ、API、データベースを数分でリリースできるようにします。

Truefoundry
Truefoundryは、エージェント型AIアプリケーションをデプロイ、管理、スケーリングするためのエンタープライズ対応プラットフォームです。統一されたAIゲートウェイを提供し、複雑なAIワークフローをオーケストレーションし、モデルを管理し、セキュリティ、ガバナンス、可観測性を確保します。開発者やMLOpsチーム向けに設計されており、オンプレミス、クラウド、ハイブリッド展開をサポートし、GPU使用率を最適化し、市場投入までの時間を短縮します。
Truefoundryは、エージェント型AIアプリケーションをデプロイ、管理、スケーリングするためのエンタープライズ対応プラットフォームです。統一されたAIゲートウェイを提供し、複雑なAIワークフローをオーケストレーションし、モデルを管理し、セキュリティ、ガバナンス、可観測性を確保します。開発者やMLOpsチーム向けに設計されており、オンプレミス、クラウド、ハイブリッド展開をサポートし、GPU使用率を最適化し、市場投入までの時間を短縮します。
Vespa.ai
Vespa.aiは、大規模アプリケーションを構築するための高性能AI検索プラットフォームです。ベクトル検索、テキスト検索、機械学習ランキングを統合し、検索拡張生成(RAG)、推薦エンジン、インテリジェント検索などの高度なユースケースを強化します。リアルタイム推論とスケーラビリティのために設計されており、SpotifyやPerplexityなどの主要企業から、大量のデータセットを低遅延で処理するために信頼されています。
Vespa.aiは、大規模アプリケーションを構築するための高性能AI検索プラットフォームです。ベクトル検索、テキスト検索、機械学習ランキングを統合し、検索拡張生成(RAG)、推薦エンジン、インテリジェント検索などの高度なユースケースを強化します。リアルタイム推論とスケーラビリティのために設計されており、SpotifyやPerplexityなどの主要企業から、大量のデータセットを低遅延で処理するために信頼されています。

Nebius
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
novita.ai
Novita AIは、開発者向けのクラウドプラットフォームで、シンプルなAPIを通じて200以上のAIモデルに手頃な価格でスケーラブルなアクセスを提供します。サーバーレスGPU、専用GPUインスタンス、カスタムモデルのデプロイメントを提供し、開発者がインフラを管理することなくAIアプリケーションを構築・拡張できるようにします。
Novita AIは、開発者向けのクラウドプラットフォームで、シンプルなAPIを通じて200以上のAIモデルに手頃な価格でスケーラブルなアクセスを提供します。サーバーレスGPU、専用GPUインスタンス、カスタムモデルのデプロイメントを提供し、開発者がインフラを管理することなくAIアプリケーションを構築・拡張できるようにします。
Avian 分類
Avian タグ
Avian 適用職種
Avian AIツール
Avian 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!