
Textraction 概要
Textractionは、開発者や企業が非構造化テキストから構造化データを簡単に抽出できるように設計された、最先端のAIツールです。ドキュメント、メール、ウェブページ、顧客フィードバックなどを解析し、クリーンで整理されたJSON形式に変換する強力なAPIとして機能します。Textractionの核心的な革新はそのシンプルさにあります。複雑なプログラミングやモデルのトレーニングの代わりに、ユーザーは「エンティティ」として知られる必要なデータポイントを、簡単な自然言語の記述を使って定義できます。これにより、高度なデータ抽出がより多くの人々に利用可能になり、開発や自動化のワークフローが劇的に高速化します。
Textractionの使い方
Textractionの使用は、迅速な統合と即時の結果を目指して設計された簡単なプロセスです。ワークフローは通常、以下のステップを含みます:
- スキーマの定義:最初のステップは、AIに何を抽出させたいかを伝えることです。関心のあるエンティティをリストアップしてスキーマを作成します。各エンティティについて、自然言語の記述(例:「アイテムの合計価格」)、データ型(文字列、浮動小数点数、整数など)、変数名(例:「total_price」)を提供します。
- 入力テキストの提供:情報を抽出したい生の非構造化テキストを提供します。これは製品レビュー、法的条項、不動産リスト、その他のテキストブロックなどです。
- API呼び出し:定義したスキーマと共に入力テキストをTextraction APIエンドポイントに送信します。この単一の呼び出しには、AIが抽出を実行するために必要なすべての情報が含まれています。
- 構造化JSON出力の受信:APIはリクエストをリアルタイムで処理し、適切に構造化されたJSONオブジェクトを返します。このオブジェクトには、スキーマで定義した変数名に従ってきれいに整理された抽出値が含まれています。
- 統合と自動化:返されたJSONデータをアプリケーションで直接使用したり、データベースに保存したり、他のサービスに渡したりします。Zapier連携により、コードを書かずにTextractionを何千もの他のアプリケーションに接続し、強力な自動化ワークフローを作成できます。
Textractionの主な機能
- カスタムエンティティ抽出:事前定義されたカテゴリを超えて、請求書のSKU番号から法的文書の特定の条項まで、記述できるほぼすべての情報を定義して抽出します。
- 自然言語スキーマ:機械学習の専門知識は不要です。必要なデータを平易な英語で記述するだけで、AIが要件を理解します。
- 開発者フレンドリーなAPI:クリーンで堅牢なREST APIにより、あらゆるアプリケーション、サービス、スクリプトに簡単に統合できます。ドキュメントは明確で、すぐに始められるように例が提供されています。
- Zapier連携:TextractionをGoogle Sheets、Slack、Airtableなどのアプリに接続してワークフローを自動化します。これにより、非開発者でも強力なデータ抽出パイプラインを構築できます。
- 多言語サポート:AIは英語に限定されません。さまざまな言語のテキストから情報を処理・抽出し、グローバルな運用に対応する多用途なツールとなります。
- スケーラブルで高速:最先端のAIインフラ上に構築されたTextractionは、大量のリクエストを迅速かつ確実に処理するように設計されており、小規模プロジェクトからエンタープライズレベルのアプリケーションまで適しています。
Textractionの使用例
Textractionの柔軟性は、多くの業界や機能で応用可能です:
- データ入力の自動化:請求書、領収書、発注書、フォームからデータを自動的に抽出し、データベースやERPシステムに入力することで、手作業のデータ入力を排除します。
- Eコマース:サプライヤーのデータフィード、競合他社のウェブサイト、製品説明を解析して、仕様、価格、特徴を抽出します。
- 不動産:物件リストを分析して、価格、ベッドルーム/バスルームの数、面積、場所などの主要な詳細を抽出します。
- 金融・法務:財務報告書、契約書、法的文書を精査して、主要な数値、日付、当事者名、特定の条項を抽出します。
- 採用:履歴書や職務経歴書を処理して、スキル、職務経験、連絡先などの候補者情報を自動的に抽出します。
- 市場調査:顧客レビュー、ソーシャルメディアの投稿、記事を分析して、製品の言及、感情、主要なテーマを抽出します。
Textractionの利点
Textractionを選択することには、いくつかの重要な利点があります。その主な利点は、パワーとシンプルさの組み合わせであり、高度なNLP技術へのアクセスを民主化します。カスタム抽出モデルの開発に関連する時間とコストを大幅に削減します。高度なカスタマイズ性により、ツールは独自のビジネスニーズに適応でき、その速度とスケーラビリティは成長をサポートします。面倒なデータ抽出タスクを自動化することで、貴重な人的リソースをより戦略的な活動に集中させることができます。
料金プラン
Textractionはフリーミアムモデルで運営されており、あらゆる規模のプロジェクトで利用できます。新規ユーザーは通常、テストや小規模なアプリケーションに最適な、かなりの数の抽出が可能な寛大な無料枠から始めることができます。より大量のニーズには、使用量(API呼び出しの数や処理された文字数など)に基づいた有料プランがあります。料金は透明でスケーラブルに設計されており、使用した分だけ支払うことができます。さまざまなプランとその制限や機能に関する詳細で最新の情報については、Textractionの公式ウェブサイトの料金ページをご覧ください。
Textraction コメント (0)
ログインするとコメントを投稿できます
今すぐログインTextraction 代替案
すべて表示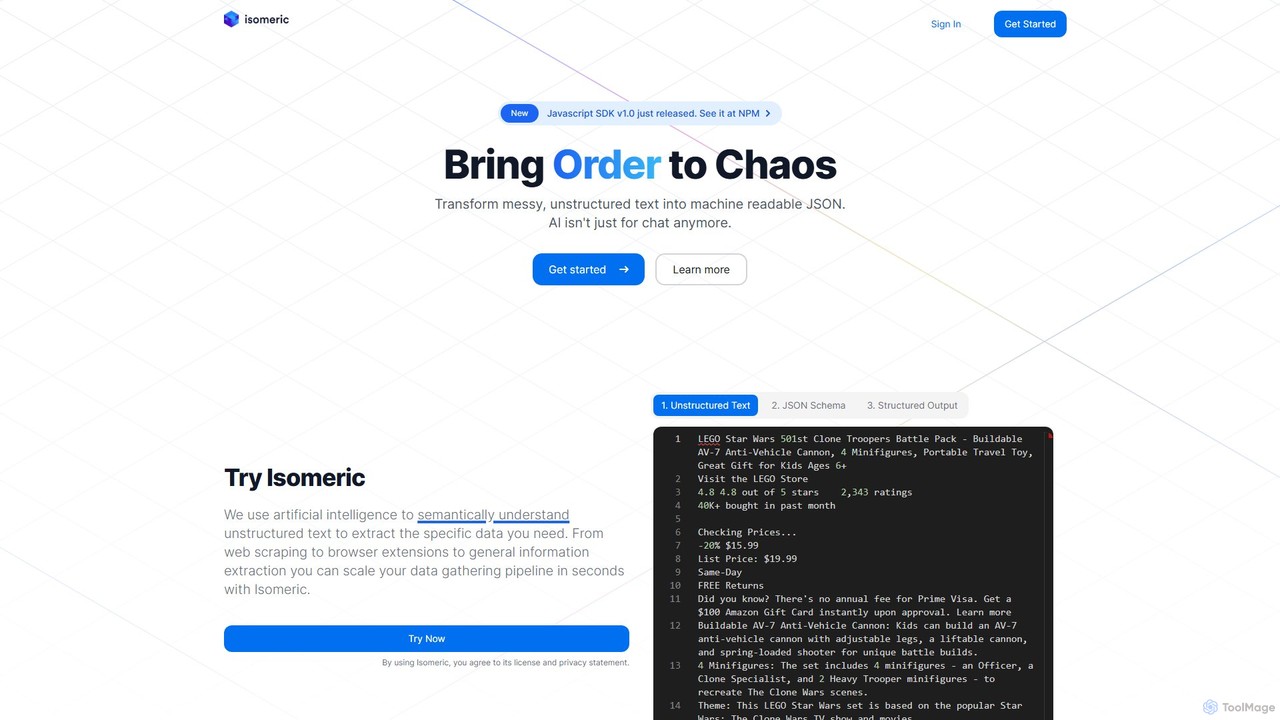
Isomeric
Isomericは、あらゆるソースからの乱雑な非構造化テキストを、クリーンで構造化されたJSONデータに変換するAI搭載APIです。簡単なJSONスキーマを定義するだけで、ウェブサイト、法的文書、カスタマーサポートの記録などから特定の情報を自動的に抽出し、データパイプラインと自動化を効率化します。
Isomericは、あらゆるソースからの乱雑な非構造化テキストを、クリーンで構造化されたJSONデータに変換するAI搭載APIです。簡単なJSONスキーマを定義するだけで、ウェブサイト、法的文書、カスタマーサポートの記録などから特定の情報を自動的に抽出し、データパイプラインと自動化を効率化します。

Foxscrape
FoxScrapeは、開発者向けのAI搭載ウェブスクレイピングREST APIです。平易な英語によるAI駆動の解析、動的サイト向けのJavaScriptレンダリング、ブロックを回避するための自動プロキシローテーションなどの機能を使用して、あらゆるウェブサイトを構造化されたJSONデータに変換し、データ抽出を簡素化します。
FoxScrapeは、開発者向けのAI搭載ウェブスクレイピングREST APIです。平易な英語によるAI駆動の解析、動的サイト向けのJavaScriptレンダリング、ブロックを回避するための自動プロキシローテーションなどの機能を使用して、あらゆるウェブサイトを構造化されたJSONデータに変換し、データ抽出を簡素化します。
instantapi
instantapiは、シンプルさとスピードを追求して設計されたAI搭載のウェブスクレイピングAPIです。ユーザーは複雑なコーディングや手動設定なしに、単一のAPIコールで任何のウェブサイトから構造化データを抽出できます。従来のウェブスクレイパーの手間をかけずに、高速で手頃な価格の信頼性の高いデータ抽出を必要とする開発者、データアナリスト、ビジネスに最適です。
instantapiは、シンプルさとスピードを追求して設計されたAI搭載のウェブスクレイピングAPIです。ユーザーは複雑なコーディングや手動設定なしに、単一のAPIコールで任何のウェブサイトから構造化データを抽出できます。従来のウェブスクレイパーの手間をかけずに、高速で手頃な価格の信頼性の高いデータ抽出を必要とする開発者、データアナリスト、ビジネスに最適です。
UseScraper
UseScraperは、開発者やAIアプリケーション向けに設計された強力なウェブクローラーおよびスクレイパーAPIです。あらゆるウェブサイトから効率的にデータを抽出し、完全なJavaScriptレンダリング、自動スケーリングインフラ、そしてChatGPTのようなLLMへのデータ供給に最適なクリーンなMarkdownなどの出力形式を特長としています。
UseScraperは、開発者やAIアプリケーション向けに設計された強力なウェブクローラーおよびスクレイパーAPIです。あらゆるウェブサイトから効率的にデータを抽出し、完全なJavaScriptレンダリング、自動スケーリングインフラ、そしてChatGPTのようなLLMへのデータ供給に最適なクリーンなMarkdownなどの出力形式を特長としています。
Browser Use
Browser Useは、コーディング不要で反復的なオンラインタスクを自動化するAI搭載のブラウザエージェントです。複雑なデータスクレイピング、フォーム入力、その他のウェブベースのワークフローを処理できます。Y Combinatorの支援を受けており、ユーザー向けのシンプルなチャットインターフェースと、開発者向けの強力なAPIを提供し、オンライン活動を効率化します。
Browser Useは、コーディング不要で反復的なオンラインタスクを自動化するAI搭載のブラウザエージェントです。複雑なデータスクレイピング、フォーム入力、その他のウェブベースのワークフローを処理できます。Y Combinatorの支援を受けており、ユーザー向けのシンプルなチャットインターフェースと、開発者向けの強力なAPIを提供し、オンライン活動を効率化します。
Webcrawlerapi
Webcrawlerapiは、開発者が簡単にウェブサイトをクロールし、クリーンなデータを抽出できるように設計された強力なAPIです。JavaScriptのレンダリング、アンチボット対策、データ解析を処理することで、複雑なウェブスクレイピングプロセスを簡素化します。LLM AIモデルのトレーニングや検索拡張生成(RAG)システムのために、Markdownやテキストなどの構造化コンテンツを収集するのに最適で、高い成功率とシンプルな従量課金制の価格モデルを提供します。
Webcrawlerapiは、開発者が簡単にウェブサイトをクロールし、クリーンなデータを抽出できるように設計された強力なAPIです。JavaScriptのレンダリング、アンチボット対策、データ解析を処理することで、複雑なウェブスクレイピングプロセスを簡素化します。LLM AIモデルのトレーニングや検索拡張生成(RAG)システムのために、Markdownやテキストなどの構造化コンテンツを収集するのに最適で、高い成功率とシンプルな従量課金制の価格モデルを提供します。
NuMind
NuMindは、高品質な構造化情報抽出のための専門AIプラットフォーム「NuExtract」を提供します。PDF、画像、メールなどの非構造化文書を大規模にクリーンなJSONデータに変換します。軽量で強力なVLM/LLMを活用し、大規模モデルよりも優れた精度と低いハルシネーション率を実現し、APIまたはプライベートエンタープライズソリューションとして利用可能です。
NuMindは、高品質な構造化情報抽出のための専門AIプラットフォーム「NuExtract」を提供します。PDF、画像、メールなどの非構造化文書を大規模にクリーンなJSONデータに変換します。軽量で強力なVLM/LLMを活用し、大規模モデルよりも優れた精度と低いハルシネーション率を実現し、APIまたはプライベートエンタープライズソリューションとして利用可能です。
Curlent
Curlentは、AIを搭載したウェブスクレイピングおよびデータ抽出プラットフォームで、あらゆるウェブサイトからの構造化データ収集を自動化します。動的なコンテンツ、ボット対策、複雑なレイアウトをインテリジェントに処理し、強力なAPIを通じてクリーンで即利用可能なデータを提供します。
Curlentは、AIを搭載したウェブスクレイピングおよびデータ抽出プラットフォームで、あらゆるウェブサイトからの構造化データ収集を自動化します。動的なコンテンツ、ボット対策、複雑なレイアウトをインテリジェントに処理し、強力なAPIを通じてクリーンで即利用可能なデータを提供します。
Crawly
CrawlyはDiffbotが開発したAI搭載のウェブクローラーで、ウェブサイト全体から構造化データを自動的に抽出します。URLを入力するだけで、Crawlyがサイトをスパイダーし、記事、製品、ディスカッションなどの重要な情報を取得し、コーディング不要でクリーンなJSONまたはCSVデータに変換します。
CrawlyはDiffbotが開発したAI搭載のウェブクローラーで、ウェブサイト全体から構造化データを自動的に抽出します。URLを入力するだけで、Crawlyがサイトをスパイダーし、記事、製品、ディスカッションなどの重要な情報を取得し、コーディング不要でクリーンなJSONまたはCSVデータに変換します。
Textraction AIツール
Textraction 埋め込み機能
下の埋め込みコードをコピーし、素敵なバッジをあなたのブログ、記事、またはアプリの公式サイトに貼り付けるだけで、このツールの詳細ページに直接トラフィックを誘導し、露出とユーザー数を素早く増やすことができます!

まだコメントはありません。最初のコメントをしてみませんか!