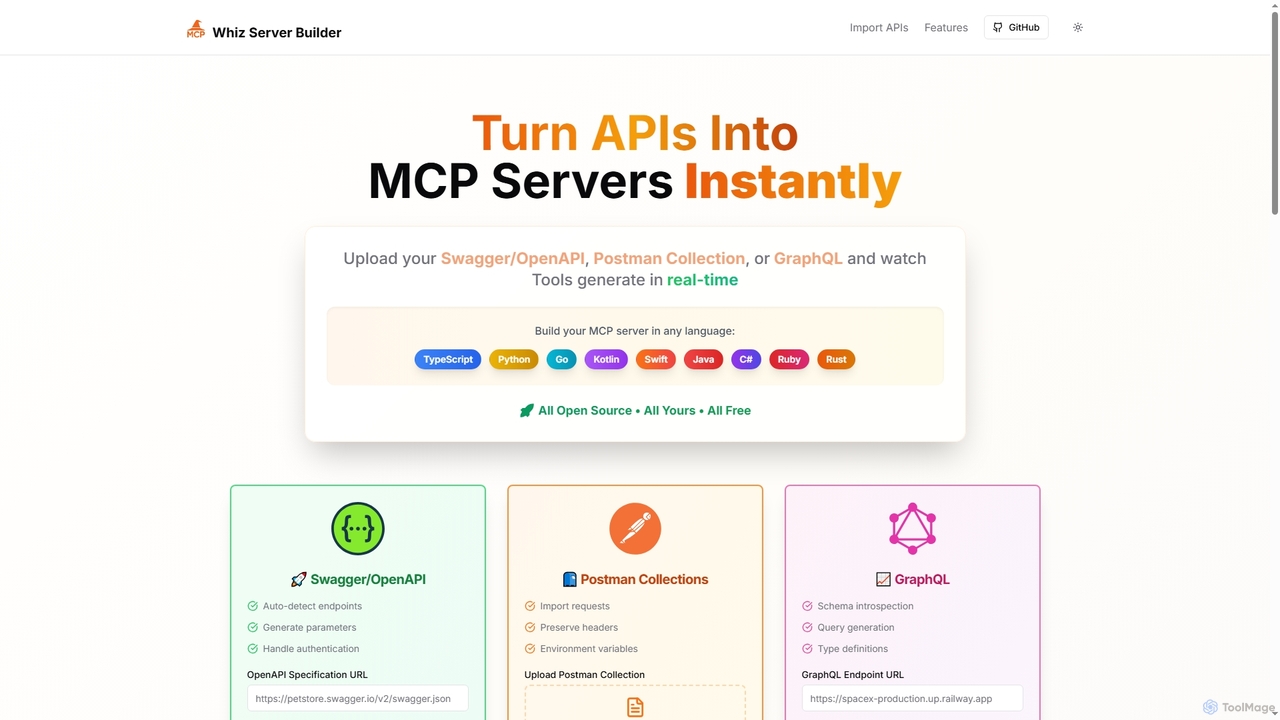
Mcpwhiz
Mcpwhiz é uma ferramenta de desenvolvedor gratuita e de código aberto que converte instantaneamente especificações de API como …
Mcpwhiz é uma ferramenta de desenvolvedor gratuita e de código aberto que converte instantaneamente especificações de API como Swagger/OpenAPI, Postman Collections e GraphQL em servidores de Protocolo de Contexto de Modelo (MCP) prontos para produção. Ele automatiza a geração de código em várias linguagens, incluindo TypeScript e Python, permitindo que os desenvolvedores criem aplicativos com reconhecimento de contexto com facilidade.
Sobre Gerenciamento de Servidor
As ferramentas de Gerenciamento de Servidor com IA são uma categoria especializada de software de Infraestrutura de IA que utiliza aprendizado de máquina para automatizar e otimizar o monitoramento, a manutenção e o desempenho de ambientes de servidor. Essas ferramentas analisam grandes volumes de dados de telemetria — como logs, métricas e traces — para identificar padrões, prever falhas e automatizar tarefas administrativas complexas. Seu valor principal reside na transformação das operações de servidor de um modelo reativo para um proativo, aumentando significativamente o tempo de atividade, a segurança e a eficiência dos recursos. Ao alavancar a análise preditiva, elas ajudam a prevenir problemas antes que afetem os usuários e a otimizar a alocação de recursos para cargas de trabalho exigentes, como o treinamento de modelos de IA.
Recursos Principais
- Análise Preditiva de Falhas: Usa modelos de aprendizado de máquina para analisar métricas de hardware e logs para prever falhas potenciais de componentes do servidor.
- Escalonamento Automatizado de Recursos: Ajusta inteligentemente recursos de computação, memória e armazenamento com base nas demandas da carga de trabalho em tempo real para otimizar o desempenho e o custo.
- Detecção de Anomalias com IA: Identifica padrões incomuns em dados de desempenho ou segurança que se desviam das linhas de base normais, sinalizando possíveis problemas ou ameaças.
- Análise de Causa Raiz (RCA) Automatizada: Correlaciona eventos em toda a pilha de infraestrutura para identificar automaticamente a origem de um problema, reduzindo o tempo de solução de problemas.
- Otimização do Consumo de Energia: Analisa a utilização do servidor para gerenciar estados de energia e distribuição de carga de trabalho, minimizando os custos de eletricidade em data centers.
Cenários de Aplicação
Essas ferramentas são essenciais para engenheiros de DevOps, equipes de MLOps, Engenheiros de Confiabilidade de Site (SREs) e administradores de TI que gerenciam frotas de servidores em grande escala ou de missão crítica. Elas são particularmente valiosas em ambientes com clusters de computação de alto desempenho (HPC), aplicativos nativos da nuvem e infraestrutura dedicada ao treinamento e implantação de modelos de IA, onde o desempenho e a confiabilidade são primordiais.
Critérios de Seleção
Ao escolher uma ferramenta de Gerenciamento de Servidor com IA, considere suas capacidades de integração com sua pilha de monitoramento existente (por exemplo, Prometheus, Datadog). Avalie a sofisticação de seus modelos de IA para previsão e detecção de anomalias. Além disso, avalie sua compatibilidade com sua infraestrutura, seja local, na nuvem ou híbrida, e seu suporte para hardware específico, como GPUs.
Gerenciamento de ServidorCenários de aplicação
Manutenção Proativa de Hardware de Data Center
Um administrador de TI de uma grande plataforma de comércio eletrônico é responsável pela manutenção de centenas de servidores físicos. Usando uma ferramenta de Gerenciamento de Servidor com IA, eles podem ir além das verificações de rotina agendadas. A ferramenta analisa continuamente dados de sensores de vibração, métricas de temperatura e taxas de erro de E/S de disco. Ela prevê que três discos rígidos específicos em um cluster de banco de dados crítico têm 85% de probabilidade de falha nos próximos 30 dias. Isso permite que o administrador agende uma janela de manutenção para substituir os discos proativamente, evitando uma interrupção catastrófica durante um período de pico de vendas e economizando horas de trabalho de recuperação de emergência.
Alocação Dinâmica de Recursos de GPU para MLOps
Uma equipe de MLOps em um instituto de pesquisa gerencia um cluster compartilhado de servidores GPU caros para múltiplos experimentos de aprendizado de máquina simultâneos. Uma ferramenta de Gerenciamento de Servidor com IA monitora as solicitações de recursos e a utilização real de cada trabalho de treinamento. Quando detecta que um trabalho de alta prioridade está subutilizando suas GPUs alocadas enquanto outro está na fila, ela realoca automaticamente os recursos de GPU ociosos. Esse agendamento dinâmico garante que o hardware de alto custo seja sempre usado de forma eficiente, reduzindo os tempos de conclusão dos experimentos em até 30% e maximizando o retorno sobre o investimento em hardware.
Detecção Automatizada de Ameaças de Segurança
Uma empresa de serviços financeiros usa uma ferramenta de Gerenciamento de Servidor com IA para aprimorar sua postura de segurança. A ferramenta estabelece uma linha de base do tráfego de rede normal e da atividade do usuário para seus servidores críticos. Certa noite, ela detecta uma série de tentativas de login incomuns de um endereço IP estrangeiro, seguidas por transferências de dados inesperadas para um servidor externo. Esse padrão se desvia significativamente da norma estabelecida. O sistema sinaliza isso automaticamente como uma anomalia de alto risco, isola o servidor afetado da rede e alerta a equipe de operações de segurança, prevenindo uma potencial violação de dados antes que danos significativos ocorram.
Otimização de Custos de Computação em Nuvem
Uma startup que executa toda a sua aplicação em um provedor de nuvem pública quer controlar seus custos crescentes de computação. Sua equipe de DevOps implanta uma ferramenta de Gerenciamento de Servidor com IA que analisa os padrões históricos de uso de suas instâncias de máquina virtual. A ferramenta identifica que várias instâncias grandes usadas para processamento de dados ficam ociosas por mais de 18 horas por dia. Ela recomenda um cronograma automatizado para desligar essas instâncias durante os horários de pico e reiniciá-las antes do início do dia de trabalho. A implementação desta única recomendação reduz sua fatura mensal de servidor em nuvem em 25% sem impactar o desempenho da aplicação.
Acelerando a Resposta a Incidentes com Análise de Causa Raiz
Um Engenheiro de Confiabilidade de Site (SRE) recebe um alerta de que uma API voltada para o cliente está com alta latência. Em vez de vasculhar manualmente logs e painéis de dezenas de microsserviços, ele consulta sua ferramenta de Gerenciamento de Servidor com IA. A ferramenta já correlacionou o pico de latência com um aumento anormal no uso de memória em um servidor de banco de dados específico e uma série de consultas lentas de um serviço recém-implantado. Ela apresenta uma cadeia causal clara, identificando as consultas defeituosas como a causa raiz. Isso reduz o tempo médio de resolução (MTTR) de mais de uma hora para apenas dez minutos.
Gerenciamento de Frotas de Computação de Borda Distribuída
Uma rede de varejo opera milhares de pequenos nós de servidor em suas lojas para ponto de venda e gerenciamento de estoque. Monitorar manualmente essa frota distribuída é impossível. Eles usam uma plataforma de Gerenciamento de Servidor com IA para supervisionar centralmente a saúde e o desempenho de todos os dispositivos de borda. A IA pode detectar padrões indicativos de problemas específicos de localização, como problemas de conectividade de rede afetando um grupo de lojas em uma região. Ela também pode automatizar o gerenciamento de patches, distribuindo atualizações de segurança de forma inteligente com base na carga de trabalho do dispositivo para evitar interromper as operações da loja, garantindo que toda a frota de borda permaneça segura e operacional.