Models
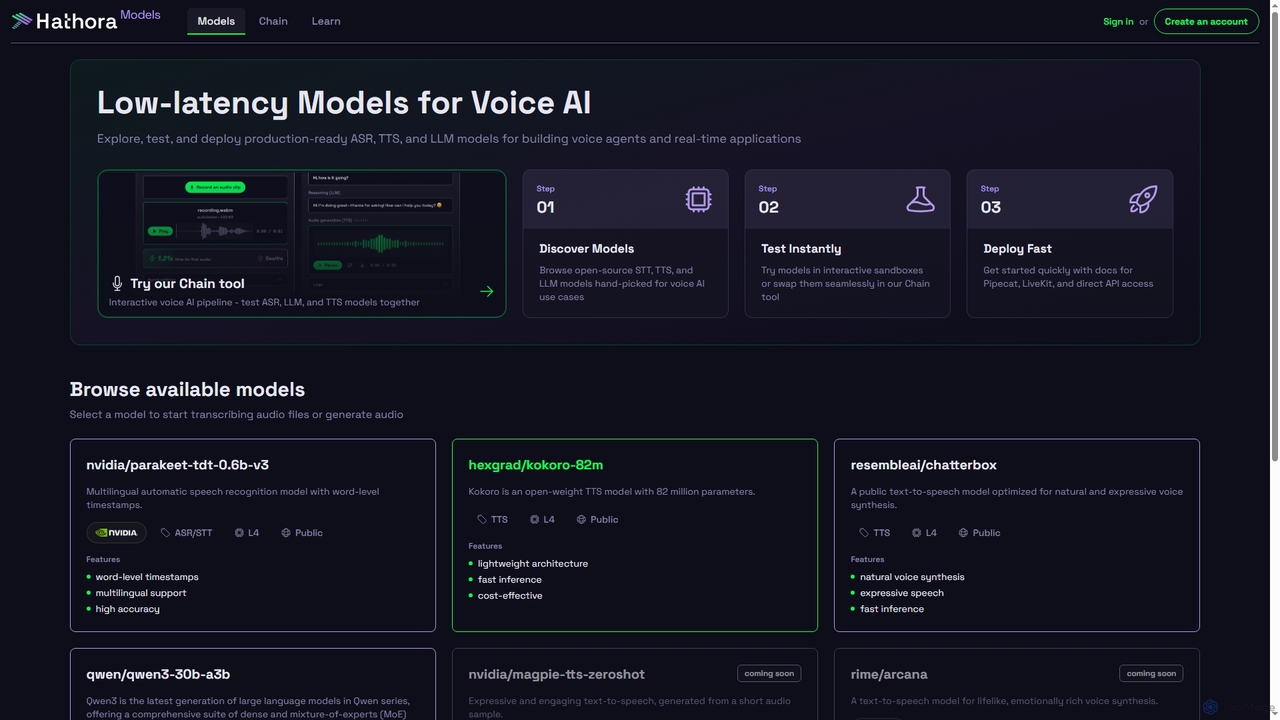
Models da Hathora oferece um catálogo selecionado de modelos ASR, TTS e LLM de baixa latência, otimizados para …
Models da Hathora oferece um catálogo selecionado de modelos ASR, TTS e LLM de baixa latência, otimizados para IA de voz e aplicações em tempo real. Desenvolvedores podem explorar, testar e implantar modelos prontos para produção rapidamente, com sandboxes interativas e acesso direto à API para integração perfeita em agentes de voz e outros aplicativos.
Zetic.ai
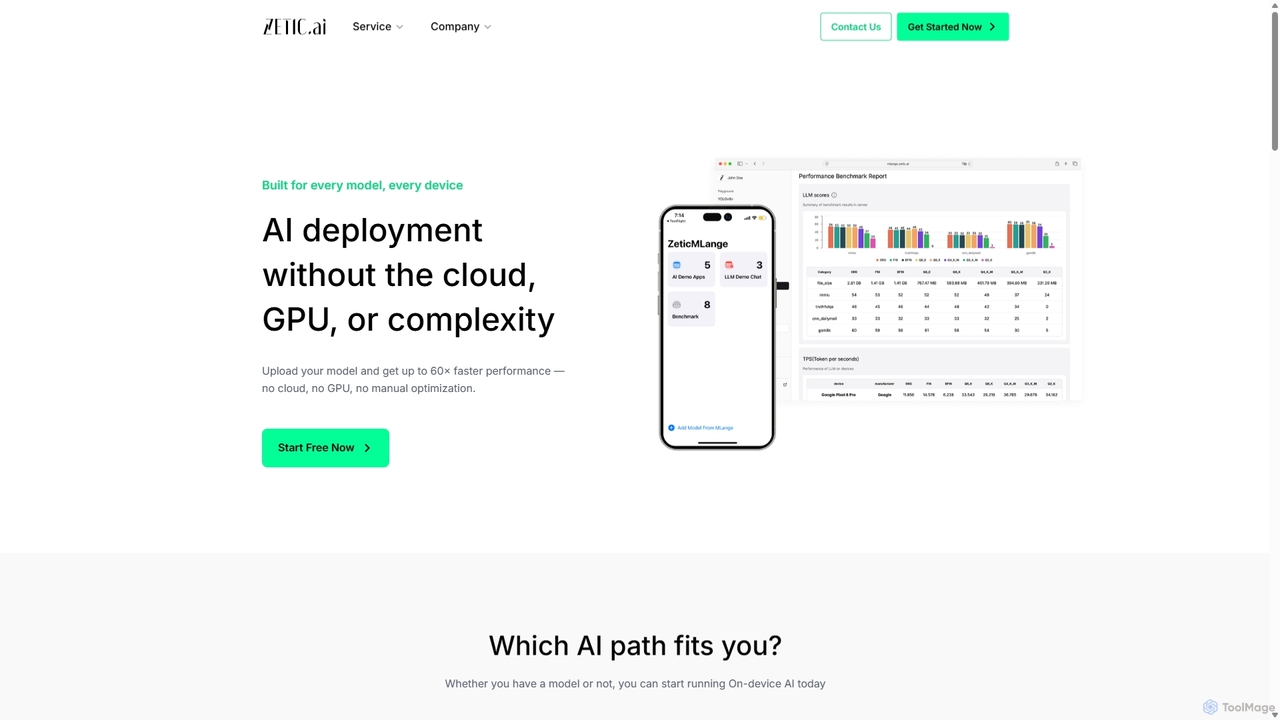
Zetic.ai é uma plataforma que permite aos desenvolvedores implantar modelos de IA diretamente em dispositivos de borda, eliminando …
Zetic.ai é uma plataforma que permite aos desenvolvedores implantar modelos de IA diretamente em dispositivos de borda, eliminando a necessidade de servidores GPU caros. Seu pipeline automatizado, ZETIC.MLange, otimiza e converte modelos para execução no dispositivo, alcançando um desempenho até 60x mais rápido com aceleração NPU, garantindo a privacidade dos dados e reduzindo a latência.
ComfyDeploy
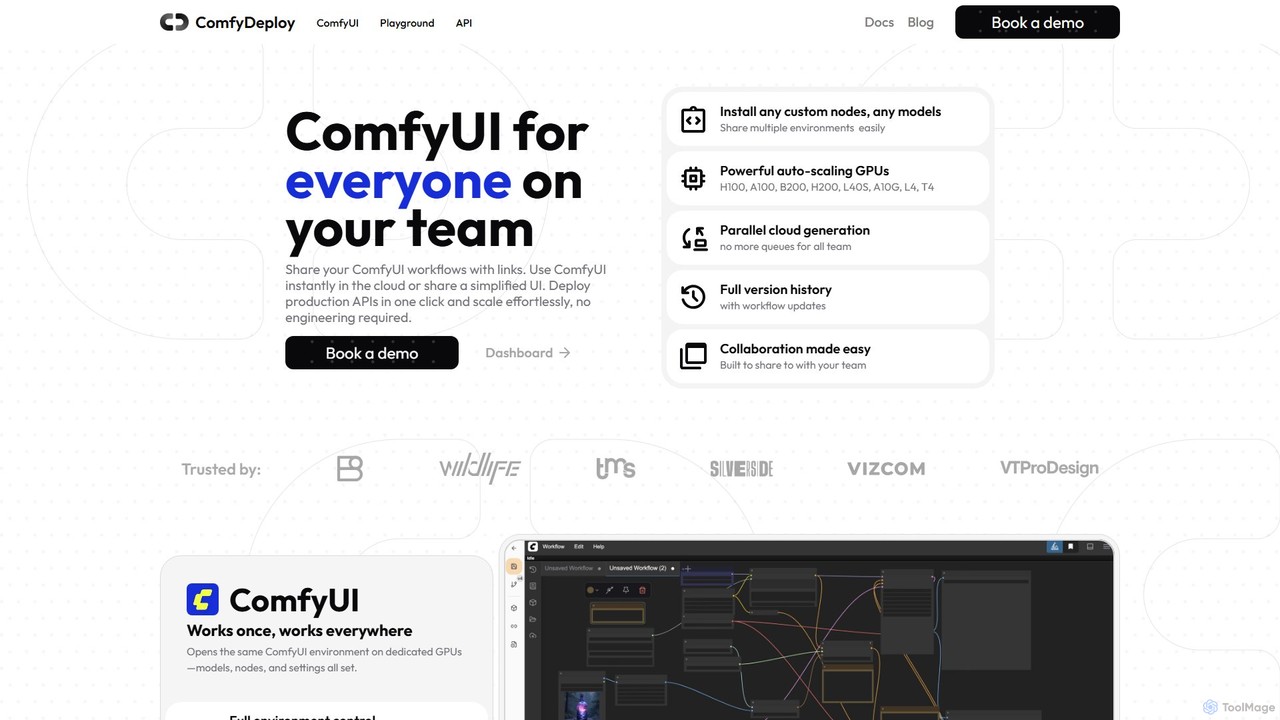
O ComfyDeploy é uma plataforma na nuvem para equipes construírem, compartilharem e escalarem fluxos de trabalho do ComfyUI. …
O ComfyDeploy é uma plataforma na nuvem para equipes construírem, compartilharem e escalarem fluxos de trabalho do ComfyUI. Ele permite a implantação de APIs prontas para produção com um clique, fornece infraestrutura de GPU com autoescalonamento e oferece interfaces simplificadas para usuários não técnicos. Colabore de forma transparente, gerencie nós e modelos personalizados e transforme processos criativos complexos em aplicativos escaláveis sem sobrecarga de engenharia.
NVIDIA Build
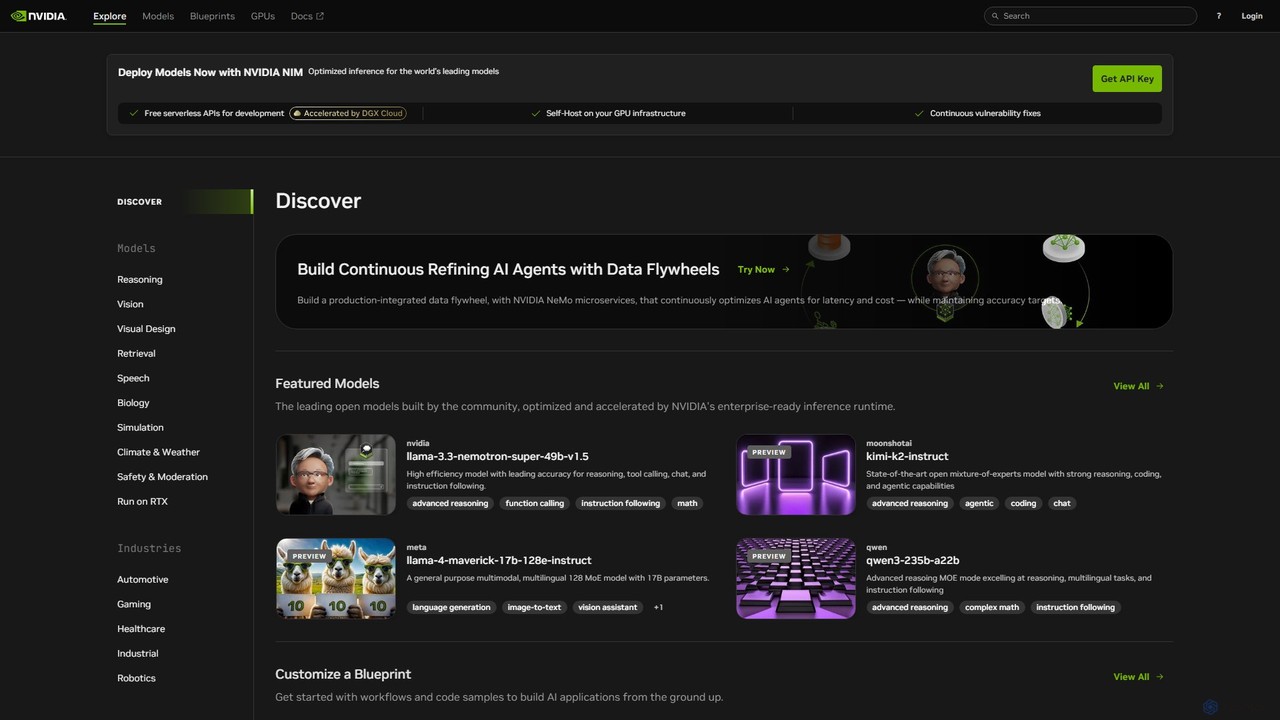
O NVIDIA Build é uma plataforma abrangente para desenvolvedores e empresas descobrirem, personalizarem e implantarem modelos de IA …
O NVIDIA Build é uma plataforma abrangente para desenvolvedores e empresas descobrirem, personalizarem e implantarem modelos de IA generativa prontos para produção. Apresenta um vasto catálogo de modelos otimizados, microsserviços NVIDIA NIM para inferência de alto desempenho e projetos de aplicação para acelerar o desenvolvimento.
Fireworks AI
Uma plataforma de alto desempenho para desenvolvedores construírem, personalizarem e escalarem aplicações de IA generativa. Oferece um motor …
Uma plataforma de alto desempenho para desenvolvedores construírem, personalizarem e escalarem aplicações de IA generativa. Oferece um motor de inferência rápido líder do setor, capacidades avançadas de fine-tuning e acesso a uma vasta gama de modelos de código aberto, permitindo soluções de IA em tempo real e com custo-benefício.
llmware
llmware é uma plataforma de IA focada em empresas para construir e implantar fluxos de trabalho de IA …
llmware é uma plataforma de IA focada em empresas para construir e implantar fluxos de trabalho de IA privados. Seu principal produto, Model HQ, permite que os usuários executem mais de 100 modelos de linguagem pequenos (até 32B parâmetros) de forma segura e local em PCs com IA, sem conexão com a internet. Oferece RAG no dispositivo, consultas SQL e outras tarefas automatizadas, enfatizando a privacidade de dados, otimização de hardware e custo zero de inferência por token.

hypermink
O HyperMink oferece o Inferenceable, um servidor de inferência de IA gratuito, de código aberto e auto-hospedável. Construído …
O HyperMink oferece o Inferenceable, um servidor de inferência de IA gratuito, de código aberto e auto-hospedável. Construído em Node.js e llama.cpp, permite que desenvolvedores e empresas executem grandes modelos de linguagem localmente, garantindo total privacidade, controle e economia de dados. Sua IA, Suas Regras.
Sobre Implantação de Modelo
As ferramentas de Implantação de Modelo são plataformas especializadas projetadas para pegar um modelo de machine learning treinado e torná-lo operacional em um ambiente de produção ao vivo. Essas ferramentas automatizam o complexo processo de empacotar o modelo, criar endpoints de API escaláveis e gerenciar seu ciclo de vida pós-desenvolvimento. Elas fornecem a infraestrutura crítica para servir previsões a usuários ou outras aplicações de forma confiável e eficiente. Ao lidar com tarefas como configuração de servidor, gerenciamento de dependências e monitoramento de desempenho, elas preenchem a lacuna entre a pesquisa em ciência de dados e o valor de negócio real.
Recursos Principais
- Geração Automatizada de API: Crie instantaneamente endpoints de API REST seguros e escaláveis para qualquer modelo treinado, tornando-o acessível para aplicações.
- Gerenciamento de Infraestrutura Escalável: Gerencie e dimensione automaticamente os recursos de computação (CPUs/GPUs) para lidar com cargas flutuantes de solicitações de previsão sem intervenção manual.
- Monitoramento de Desempenho e Logs: Acompanhe métricas chave como latência, taxa de transferência, taxas de erro e utilização de recursos para garantir a saúde e a confiabilidade do modelo.
- Versionamento de Modelos e Reversões: Gerencie múltiplas versões de um modelo, realize testes A/B e reverta rapidamente para uma versão anterior se surgirem problemas.
- Empacotamento de Ambiente e Dependências: Empacote modelos e suas dependências de software específicas em contêineres reproduzíveis (ex: Docker) para um desempenho consistente em diferentes ambientes.
Casos de Uso
Essas ferramentas são essenciais para engenheiros de ML, cientistas de dados e equipes de DevOps que buscam colocar a IA em produção. Elas são amplamente utilizadas em setores como finanças para detecção de fraudes em tempo real, e-commerce para alimentar motores de recomendação, saúde para implantar modelos de diagnóstico e SaaS para integrar recursos de IA em produtos.
Como Escolher
Ao selecionar uma ferramenta de Implantação de Modelo, considere seu suporte para seus frameworks de ML específicos (como TensorFlow, PyTorch), seus alvos de implantação (nuvem, local ou borda) e suas capacidades de autoescalonamento. Além disso, avalie a qualidade de seus painéis de monitoramento, a integração com pipelines de CI/CD existentes (como Jenkins ou GitHub Actions) e seus recursos de segurança para proteger modelos e dados.
Implantação de ModeloCenários de aplicação
Servindo um Modelo de Detecção de Fraude em Tempo Real
Uma empresa de tecnologia financeira precisa implantar um modelo de machine learning que pontua transações por risco de fraude em milissegundos. Usando uma plataforma de implantação de modelos, seus engenheiros de ML empacotam o modelo treinado e criam um endpoint de API de baixa latência. Este endpoint é integrado ao seu sistema de processamento de pagamentos. A plataforma dimensiona automaticamente a infraestrutura para lidar com picos de volume de transações, garantindo alta disponibilidade e tempos de resposta consistentes, o que é crítico para prevenir transações fraudulentas sem impactar a experiência do usuário.
Potencializando um Motor de Recomendação de E-commerce
Um varejista online deseja fornecer recomendações de produtos personalizadas aos compradores. Sua equipe de ciência de dados constrói um modelo de filtragem colaborativa. Eles usam uma ferramenta de implantação de modelo para hospedar este modelo e expô-lo como uma API interna. O site de e-commerce chama esta API para cada usuário para buscar uma lista de produtos recomendados. O recurso de versionamento da ferramenta permite que eles implementem com segurança novas versões do modelo de recomendação, façam testes A/B de seu desempenho e revertam rapidamente se um novo modelo diminuir o engajamento do usuário ou as vendas.
Implantando um Modelo de Visão Computacional em Dispositivos de Borda (Edge)
Uma empresa de manufatura usa visão computacional para controle de qualidade em sua linha de montagem. Eles precisam implantar um modelo de detecção de objetos em dispositivos pequenos e de baixo consumo de energia diretamente no chão de fábrica para análise em tempo real. Uma ferramenta de implantação de modelo que suporta implantações de borda (edge) é usada para otimizar o modelo para o hardware de destino e empacotá-lo com todas as dependências necessárias. Isso permite a detecção de defeitos de baixa latência diretamente na fonte, reduzindo a dependência da conectividade de rede a um servidor central na nuvem e permitindo ação imediata na linha de produção.
Integrando um Modelo de PNL em um Chatbot de Suporte ao Cliente
Uma empresa de SaaS deseja aprimorar seu suporte ao cliente com um chatbot alimentado por IA. Após treinar um modelo de processamento de linguagem natural (PNL) para entender as consultas dos usuários, eles usam uma plataforma de implantação para hospedá-lo. A plataforma fornece uma API de alta disponibilidade com a qual a aplicação front-end do chatbot se comunica. Os recursos de monitoramento da ferramenta são cruciais para acompanhar o desempenho do modelo, identificar as consultas que ele não consegue entender e coletar dados para futuros ciclos de retreinamento, criando um ciclo de melhoria contínua para a precisão do chatbot.
Teste A/B de Diferentes Modelos de Previsão de Churn
Uma equipe de análise de marketing desenvolve dois modelos diferentes para prever o churn de clientes. Eles não têm certeza de qual terá um desempenho melhor em um cenário do mundo real. Usando uma plataforma de implantação de modelo que suporta a divisão de tráfego, eles implantam ambos os modelos simultaneamente. A plataforma direciona 50% das solicitações de previsão para o Modelo A e 50% para o Modelo B. Após uma semana coletando dados de desempenho ao vivo, a equipe pode determinar com confiança qual modelo é mais preciso e implantar a versão vencedora para 100% do tráfego, otimizando suas campanhas de retenção.
Oferecendo um Modelo de IA Proprietário como um Serviço de API Pago
Uma startup de IA desenvolveu um modelo generativo único para criar música. Para monetizar sua tecnologia, eles decidem oferecê-la como um serviço através de uma API paga. Eles usam uma plataforma de implantação de modelo para hospedar seu modelo, gerar um endpoint de API público e gerenciar a autenticação e a limitação de taxa para diferentes níveis de assinatura. A infraestrutura robusta da plataforma garante que seu serviço seja confiável e possa escalar à medida que sua base de clientes cresce, permitindo que eles se concentrem em melhorar sua tecnologia de modelo principal em vez de gerenciar uma infraestrutura de servidor complexa.